Hello,
for the conversion, I tried both DFC 3.28 and DFC 2.27. DFC 3.28 appears to have some shape issue in the optimization currently, so I will only show the results for DFC 3.27.
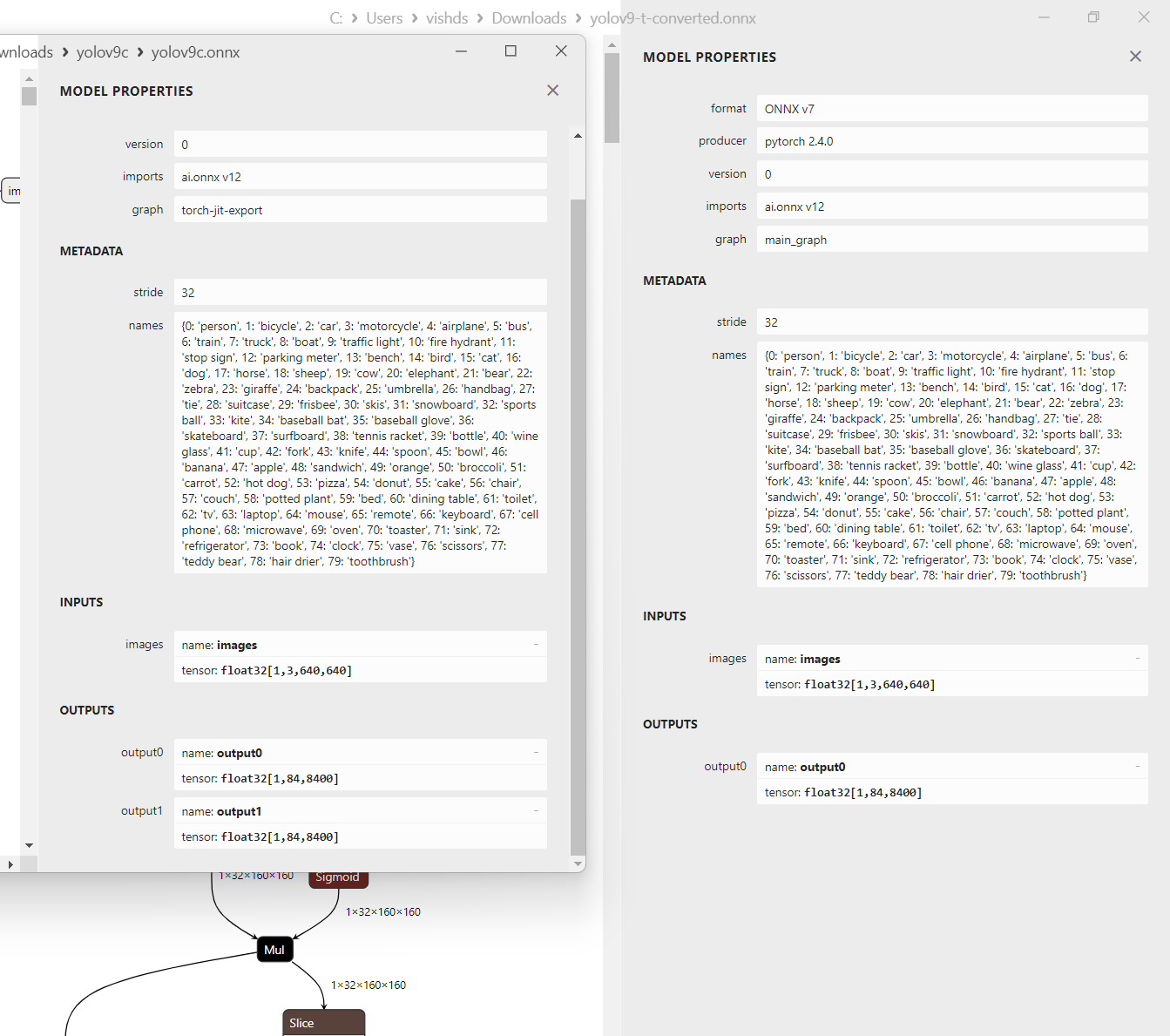
I used the weights from here: WongKinYiu/Readme/Performance/YOLOv9-T
I exported it using the command python export.py --include onnx --weights yolov9-t-converted.pt --imgsz 640 640 --simplify --optimize
(I can also make the model accesible)
Note that this onnx file is slightly different from the yolov9c in the model-zoo, as it was optimized to remove an auxiliary branch that’s only required for training.
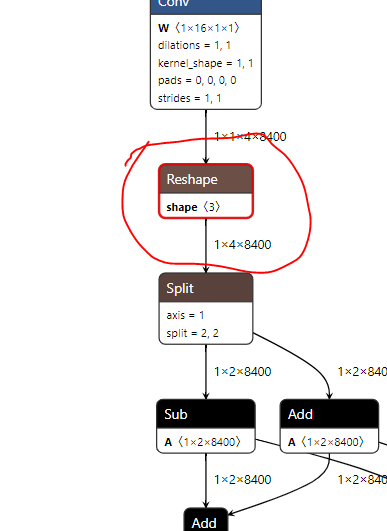
Left: YoloV9c from hailo model zoo, right: YoloV9-T
I also have a requirements.txt for the used environment with pip, that I can upload if someone provides me an upload space.
Once a .onnx file as been generated, I use these commands for conversion:
hailo parser onnx yolov9-t-converted.onnx --net-name yolov9-t --har-path yolov9-t.har --start-node-names images --end-node-names output0 --hw-arch hailo8 --augmented-path yolov9-t-augmented.onnx
These are the respective logs which look fine to me:
Note that some auto-fixed issue with the output node appeared to arise, and I dont need NMS right now, so I skipped that.
(...)
[info] System info: OS: Linux, Kernel: 6.5.0-41-generic
[info] Hailo DFC Version: 3.27.0
[info] HailoRT Version: Not Installed
[info] PCIe: b5:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] PCIe: b6:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] PCIe: b7:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] PCIe: b8:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] Running `hailo parser onnx yolov9-t-converted.onnx --net-name yolov9-t --har-path yolov9-t.har --start-node-names images --end-node-names output0 --hw-arch hailo8 --augmented-path yolov9-t-augmented.onnx`
[info] Translation started on ONNX model yolov9-t
[info] Restored ONNX model yolov9-t (completion time: 00:00:00.05)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:00.20)
[info] Saving a modified model, augmented with tensors names (where applicable). New file path is at yolov9-t-augmented.onnx
[info] Saving a simplified model, augmented with tensors names (where applicable). New file path is at yolov9-t-augmented.sim.onnx
[info] Simplified ONNX model for a parsing retry attempt (completion time: 00:00:02.13)
Parsing failed with recommendations for end node names: ['/model.22/Concat_3'].
Would you like to parse again with the recommendation? (y/n)
y
[info] According to recommendations, retrying parsing with end node names: ['/model.22/Concat_3'].
[info] Translation started on ONNX model yolov9-t
[info] Restored ONNX model yolov9-t (completion time: 00:00:00.04)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:00.20)
[info] Saving a modified model, augmented with tensors names (where applicable). New file path is at yolov9-t-augmented.onnx
[info] NMS structure of yolov8 (or equivalent architecture) was detected.
[info] In order to use HailoRT post-processing capabilities, these end node names should be used: /model.22/cv2.0/cv2.0.2/Conv /model.22/cv3.0/cv3.0.2/Conv /model.22/cv2.1/cv2.1.2/Conv /model.22/cv3.1/cv3.1.2/Conv /model.22/cv2.2/cv2.2.2/Conv /model.22/cv3.2/cv3.2.2/Conv.
[info] Start nodes mapped from original model: 'images': 'yolov9-t/input_layer1'.
[info] End nodes mapped from original model: '/model.22/Concat_3'.
[info] Translation completed on ONNX model yolov9-t (completion time: 00:00:02.79)
Would you like to parse the model again with the mentioned end nodes and add nms postprocess command to the model script? (y/n)
n
[info] Saved HAR to: (...)/hds/hailo_model_zoo/yolov9-t.har
With this command, I receive a bunch of files, one of them being yolov9-t.har. This I continue to optimize with the following command and alls file:
.alls file
normalization1 = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])
model_optimization_config(calibration, batch_size=2)
post_quantization_optimization(finetune, policy=enabled, learning_rate=1e-5)
Command
hailo optimize --hw-arch hailo8 --use-random-calib-set --calib-random-max 1 --work-dir ./wdir --model-script ~/hds/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov9t.alls --output-har-path yolov9-t-converted.har yolov9-t.har
Yes, I’m aware that --use-random-calib-set is not optimal, I wanted to test the whole toolchain before deepdiving.
These are the respective logs, which again look fine to me:
[info] Current Time: 09:11:41, 07/30/24
[info] PCIe: b5:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
(...)
[info] Running `hailo optimize --hw-arch hailo8 --use-random-calib-set --calib-random-max 1 --work-dir ./wdir --model-script /home/user/hds/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov9t.alls --output-har-path yolov9-t-converted.har yolov9-t.har`
[info] Loading model script commands to yolov9-t from /home/user/hds/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov9t.alls
[info] Found model with 3 input channels, using real RGB images for calibration instead of sampling random data.
[info] Starting Model Optimization
[info] Using default optimization level of 2
[info] Model received quantization params from the hn
[info] Starting Mixed Precision
[info] Mixed Precision is done (completion time is 00:00:00.18)
[info] create_layer_norm skipped
[info] Starting Stats Collector
[info] Using dataset with 64 entries for calibration
Calibration: 100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 64/64 [01:27<00:00, 1.37s/entries]
[info] Stats Collector is done (completion time is 00:01:32.82)
[info] No shifts available for layer yolov9-t/conv1/conv_op, using max shift instead. delta=4.770761047870071
[info] No shifts available for layer yolov9-t/conv1/conv_op, using max shift instead. delta=2.385380519565488
[info] Bias Correction skipped
[info] Adaround skipped
[info] Starting Fine Tune
[warning] Dataset is larger than expected size. Increasing the algorithm dataset size might improve the results
[info] Using dataset with 1024 entries for finetune
Epoch 1/4
437/512 [========================>.....] - ETA: 29s - total_distill_loss: 0.0831 - _distill_loss_yolov9-t/concat31: 0.0831
(...)
[info] Fine Tune is done (completion time is 00:16:57.09)
[info] Starting Layer Noise Analysis
Full Quant Analysis: 100%|¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 8/8 [05:14<00:00, 39.36s/iterations]
[info] Layer Noise Analysis is done (completion time is 00:05:22.68)
[info] Output layers signal-to-noise ratio (SNR): measures the quantization noise (higher is better)
[info] yolov9-t/output_layer1 SNR: 16.04 dB
[info] Runtime input quantization on host will be required.
Adding normalization on chip could improve the performance, by making the quantization redundant.
For more information, see Hailo Dataflow Compiler user guide / Model Optimization / Optimization Related Model Script Commands / model_modification_commands / normalization
[info] yolov9-t/input_layer1:
Current range, per feature: [(0.0, 1.0), (0.0, 1.0), (0.0, 1.0)]
Expected range (for all features): (0, 255)
[info] Model Optimization is done
[info] Saved HAR to: /home/user/hds/hailo_model_zoo/yolov9-t-converted.har
Now I try to compile the model:
hailo compiler --hw-arch hailo8 --model-script /home/user/hds/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov9t.alls --output-dir . --output-har-path yolov9-t-compiled.har /home/user/hds/hailo_model_zoo/yolov9-t-converted.har
which fails:
[info] Current Time: 09:42:34, 07/30/24
[info] CPU: Architecture: x86_64, Model: Intel(R) Core(TM) i9-9900X CPU @ 3.50GHz, Number Of Cores: 20, Utilization: 0.1%
[info] Memory: Total: 62GB, Available: 56GB
[info] System info: OS: Linux, Kernel: 6.5.0-41-generic
[info] Hailo DFC Version: 3.27.0
[info] HailoRT Version: Not Installed
[info] PCIe: b5:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] PCIe: b6:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] PCIe: b7:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] PCIe: b8:00.0: Number Of Lanes: 4, Speed: 8.0 GT/s PCIe
[info] Running `hailo compiler --hw-arch hailo8 --model-script /home/user/hds/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov9t.alls --output-dir . --output-har-path yolov9-t-compiled.har /home/user/hds/hailo_model_zoo/yolov9-t-converted.har`
[info] Loading model script commands to yolov9-t from /home/user/hds/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov9t.alls
[info] Compiling network
[info] Loading network parameters
[info] Starting Hailo allocation and compilation flow
[error] Mapping Failed (allocation time: 14s)
No successful assignment for: format_conversion1_defuse_reshape_hxf_to_w_transposed, format_conversion1_defuse_width_feature_reshape, concat31
[error] Failed to produce compiled graph
[error] BackendAllocatorException: Compilation failed: No successful assignment for: format_conversion1_defuse_reshape_hxf_to_w_transposed, format_conversion1_defuse_width_feature_reshape, concat31