Thank you @omria for the suggestion. Recompiling with end-node-names solved this problem for me!
Steps followed :
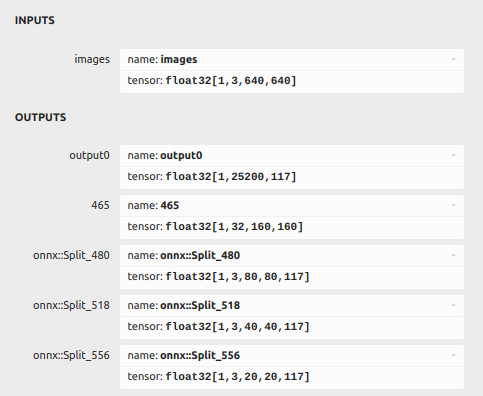
I have opened the onnx model in netron app. It showed the output names as following
I have updated hailomz compile arguments to include end-node-names as below
hailomz compile yolov5m_seg --ckpt=retrained_model.onnx --hw-arch hailo8l --calib-path dataset/train/images --classes 1 --end-node-names output0 465 onnx::Split_480 onnx::Split_518 onnx::Split_556
This resolved the earlier error of not finding the output node names, but still unable to complete the compilation siting dimension mismatch
<Hailo Model Zoo INFO> Start run for network yolov5m_seg ...
<Hailo Model Zoo INFO> Initializing the hailo8l runner...
[info] Translation started on ONNX model yolov5m_seg
[info] Restored ONNX model yolov5m_seg (completion time: 00:00:00.39)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:01.25)
[info] Simplified ONNX model for a parsing retry attempt (completion time: 00:00:02.48)
Traceback (most recent call last):
.....
.....
.....
hailo_sdk_client.model_translator.exceptions.ParsingWithRecommendationException: Parsing failed. The errors found in the graph are:
UnsupportedShuffleLayerError in op /model.24/Reshape_1: Failed to determine type of layer to create in node /model.24/Reshape_1
UnsupportedModelError in op /model.24/Add: In vertex /model.24/Add_input the constant value shape (1, 3, 80, 80, 2) must be broadcastable to the output shape [80, 80, 6]
UnsupportedModelError in op /model.24/Mul_3: In vertex /model.24/Mul_3_input the constant value shape (1, 3, 80, 80, 2) must be broadcastable to the output shape [80, 80, 6]
UnsupportedShuffleLayerError in op /model.24/Reshape_3: Failed to determine type of layer to create in node /model.24/Reshape_3
UnsupportedModelError in op /model.24/Add_1: In vertex /model.24/Add_1_input the constant value shape (1, 3, 40, 40, 2) must be broadcastable to the output shape [40, 40, 6]
UnsupportedModelError in op /model.24/Mul_7: In vertex /model.24/Mul_7_input the constant value shape (1, 3, 40, 40, 2) must be broadcastable to the output shape [40, 40, 6]
UnsupportedShuffleLayerError in op /model.24/Reshape_5: Failed to determine type of layer to create in node /model.24/Reshape_5
UnsupportedModelError in op /model.24/Add_2: In vertex /model.24/Add_2_input the constant value shape (1, 3, 20, 20, 2) must be broadcastable to the output shape [20, 20, 6]
UnsupportedModelError in op /model.24/Mul_11: In vertex /model.24/Mul_11_input the constant value shape (1, 3, 20, 20, 2) must be broadcastable to the output shape [20, 20, 6]
Please try to parse the model again, using these end node names: /model.24/proto/cv3/act/Mul, /model.24/Transpose_1, /model.24/Transpose, /model.24/Transpose_2
When the end-node-names was changed as suggested in the error message like below
hailomz compile yolov5m_seg --ckpt=retrained_model.onnx --hw-arch hailo8l --calib-path Dataset/train/images --classes 1 --end-node-names /model.24/Transpose /model.24/Transpose_2 /model.24/Transpose_1 /model.24/proto/cv3/act/Mul
Compilation was successful and generated .hef file
To test this .hef file, I have put it in a raspberry pi 5 with hailo8L
- Tried replacing this .hef file in the hailo-rpi5-examples/doc/basic-pipelines.md at main · hailo-ai/hailo-rpi5-examples · GitHub
but it gave segmentation fault
- Tried to use it in the Hailo-Application-Code-Examples/runtime/python/instance_segmentation at main · hailo-ai/Hailo-Application-Code-Examples · GitHub
but post processing was not successful
Is this the right way to test?