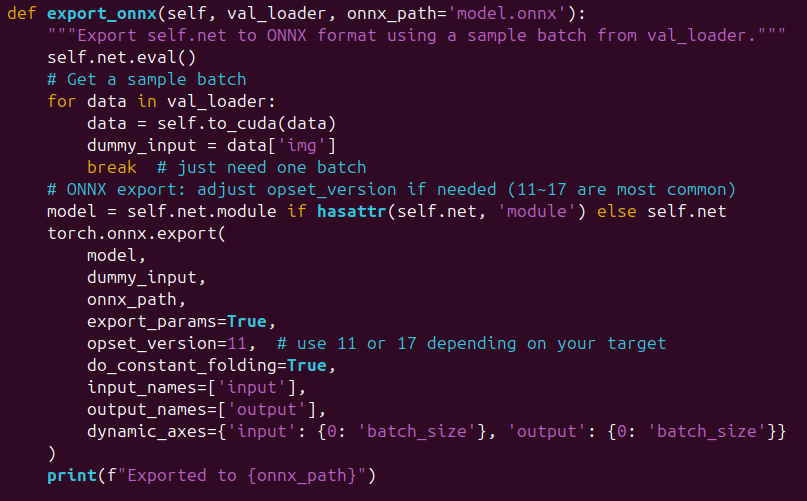
I am currently working on converting my RESA lane detection model to the Hailo platform. However, I am encountering an issue where the native output from the generated HAR file does not match the results from the original ONNX model.
Here are some details about my environment and the steps I have taken:
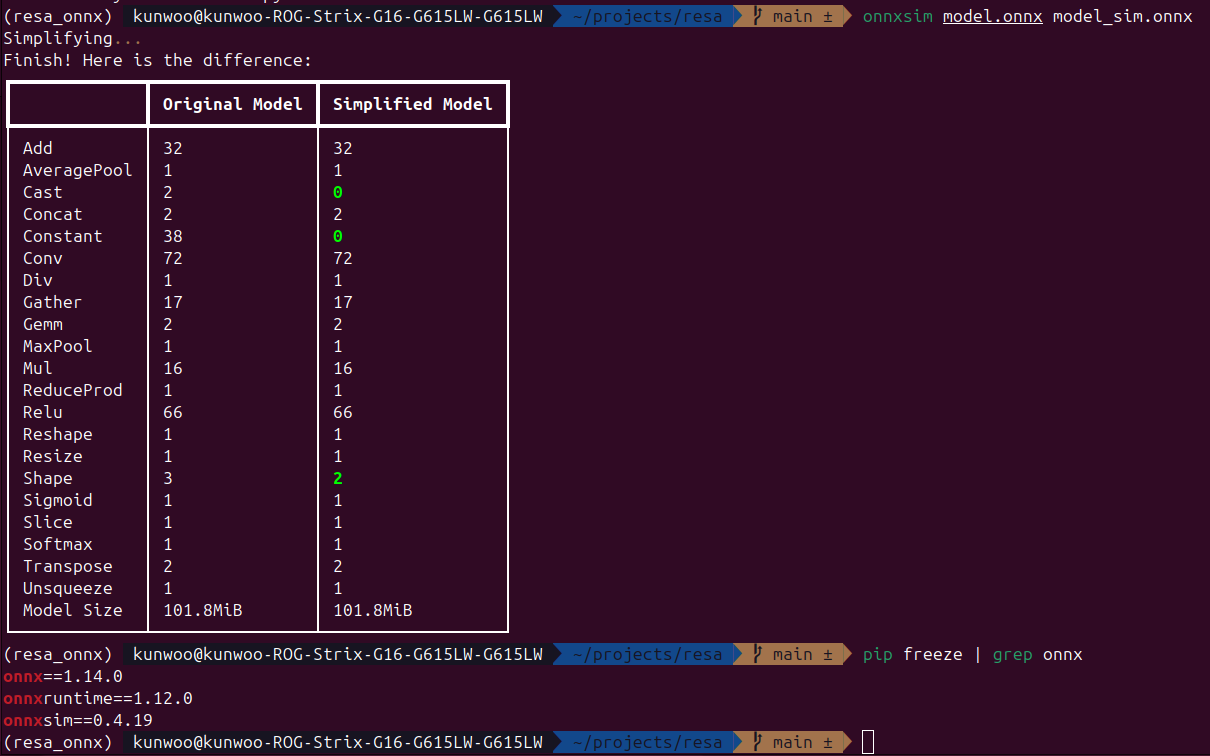
ONNX version: 1.14.0
ONNX Runtime: 1.12.0
ONNX Simplifier: 0.4.19
Hailo Dataflow Compiler: Latest Docker container (released July 2025)
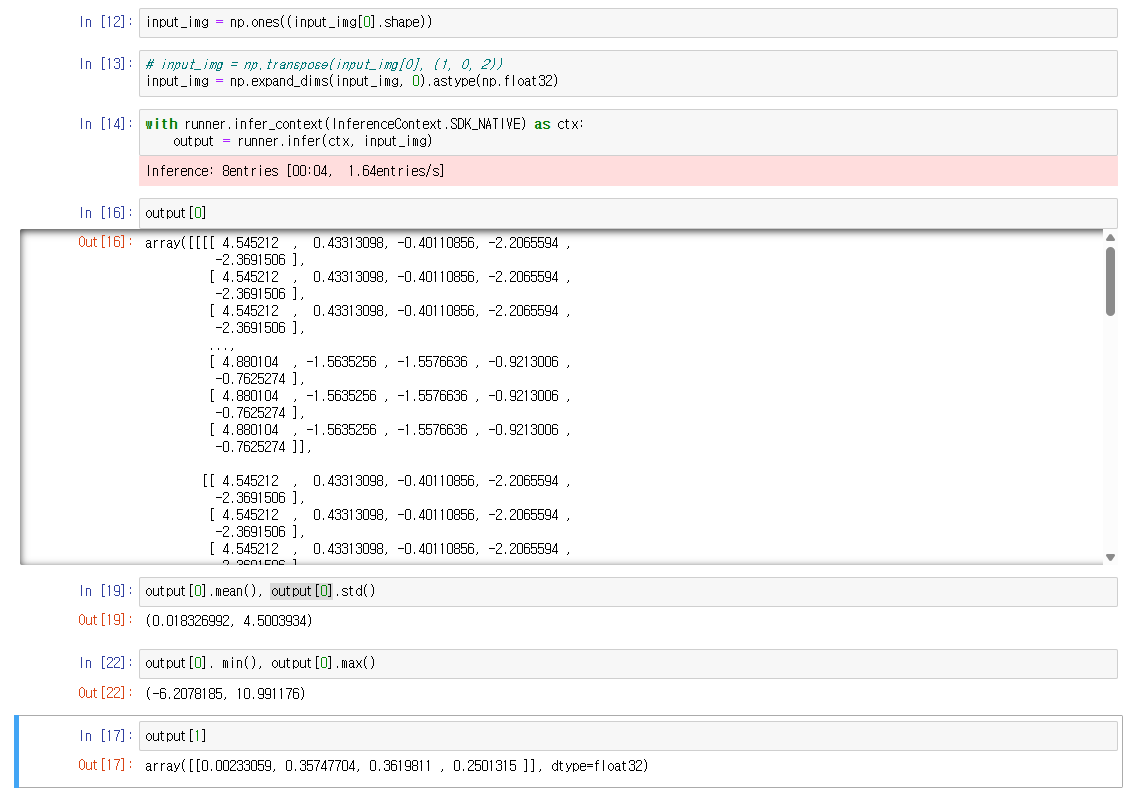
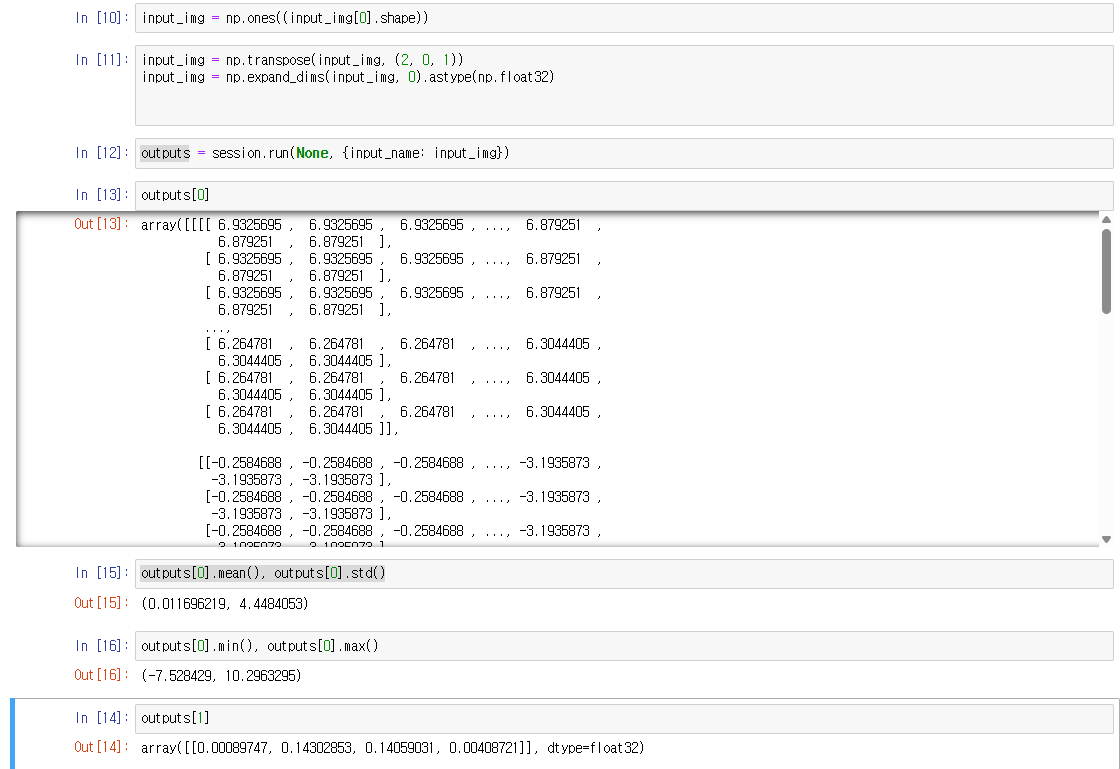
I have tried parsing both the original and the simplified ONNX files into HAR, but the outputs remain inconsistent with the ONNX results in both cases.
I would greatly appreciate any advice or suggestions to help resolve this issue.
BTW, If you need the code or ONNX files for further investigation, please let me know. I can provide all the files I have used so far—just let me know if you can share a link for uploads.
When you see differences between ONNX-Runtime and Hailo outputs, it’s usually due to parsing issues, quantization noise, or post-compilation problems. Here’s how to debug it systematically:
1. Check if it’s a parsing problem first Run full-precision emulation to see if your model parses correctly before quantization:
If this already differs from ONNX-Runtime, you have a parsing/model-script issue (wrong shapes, normalization, etc.). If it matches, the problem is in quantization.
2. Find which layers are causing quantization noise