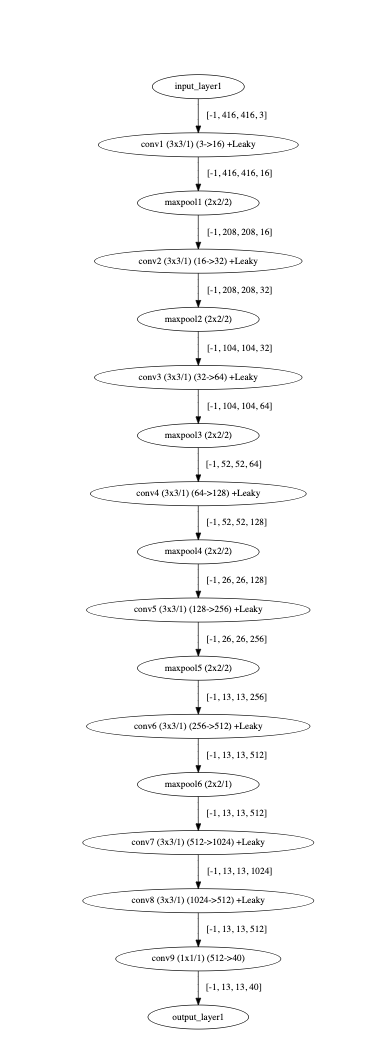
I have a simple ONNX model trained and downloaded from Microsoft CustomVision. It could work in the ONNX runtime, but after converting to HEF using DFC following the parse, optimization and compile, it can’t work (input data are the same, but output data are greatly different). I’ve no idea what’s going wrong, so post here to ask some help, thanks.
The original ONNX model:
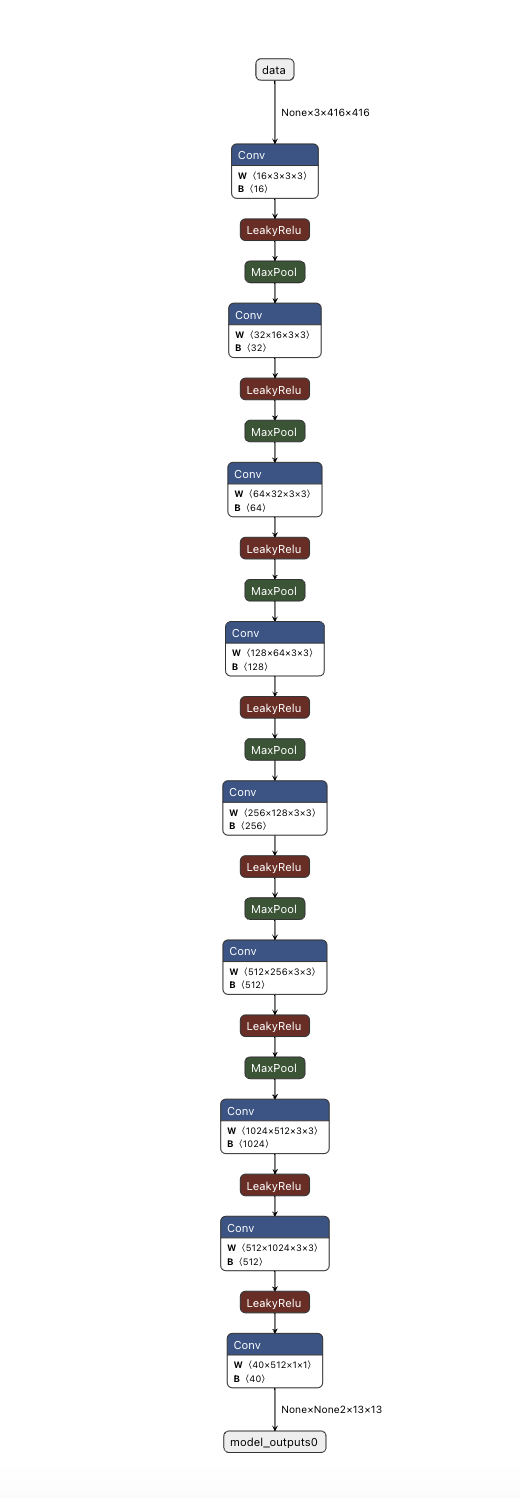
The convention steps:
hailo parser onnx --hw-arch hailo8 models/model.onnx
hailo optimize --hw-arch hailo8 --use-random-calib-set model.har
hailo compiler --hw-arch hailo8 model_optimized.har
There are logs during the conversion:
- parse
hailo parser onnx --hw-arch hailo8 models/model.onnx
[info] Current Time: 18:30:59, 11/09/24
[info] CPU: Architecture: x86_64, Model: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz, Number Of Cores: 16, Utilization: 0.6%
[info] Memory: Total: 30GB, Available: 26GB
[info] System info: OS: Linux, Kernel: 5.15.0-122-generic
[info] Hailo DFC Version: 3.29.0
[info] HailoRT Version: Not Installed
[info] PCIe: No Hailo PCIe device was found
[info] Running `hailo parser onnx --hw-arch hailo8 models/model.onnx`
[info] Translation started on ONNX model model
[info] Restored ONNX model model (completion time: 00:00:00.38)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:01.21)
/home/hailo-test/onnx-to-hailo/venv/lib/python3.10/site-packages/tensorflow_addons/utils/tfa_eol_msg.py:23: UserWarning:
TensorFlow Addons (TFA) has ended development and introduction of new features.
TFA has entered a minimal maintenance and release mode until a planned end of life in May 2024.
Please modify downstream libraries to take dependencies from other repositories in our TensorFlow community (e.g. Keras, Keras-CV, and Keras-NLP).
For more information see: https://github.com/tensorflow/addons/issues/2807
warnings.warn(
/home/hailo-test/onnx-to-hailo/venv/lib/python3.10/site-packages/tensorflow_addons/utils/ensure_tf_install.py:53: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.13.0 and strictly below 2.16.0 (nightly versions are not supported).
The versions of TensorFlow you are currently using is 2.12.0 and is not supported.
Some things might work, some things might not.
If you were to encounter a bug, do not file an issue.
If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version.
You can find the compatibility matrix in TensorFlow Addon's readme:
https://github.com/tensorflow/addons
warnings.warn(
[warning] ONNX shape inference failed: Field 'type' of 'value_info' is required but missing.
[info] Start nodes mapped from original model: 'data': 'model/input_layer1'.
[info] End nodes mapped from original model: 'convolution8'.
[info] Translation completed on ONNX model model (completion time: 00:00:01.72)
[info] Saved HAR to: /home/hailo-test/onnx-to-hailo/model.har
- optimize
hailo optimize --hw-arch hailo8 --use-random-calib-set model.har
[info] Current Time: 18:32:24, 11/09/24
[info] CPU: Architecture: x86_64, Model: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz, Number Of Cores: 16, Utilization: 0.5%
[info] Memory: Total: 30GB, Available: 26GB
[info] System info: OS: Linux, Kernel: 5.15.0-122-generic
[info] Hailo DFC Version: 3.29.0
[info] HailoRT Version: Not Installed
[info] PCIe: No Hailo PCIe device was found
[info] Running `hailo optimize --hw-arch hailo8 --use-random-calib-set model.har`
[info] Found model with 3 input channels, using real RGB images for calibration instead of sampling random data.
[info] Starting Model Optimization
[warning] Reducing optimization level to 0 (the accuracy won't be optimized and compression won't be used) because there's no available GPU
[warning] Running model optimization with zero level of optimization is not recommended for production use and might lead to suboptimal accuracy results
[info] Model received quantization params from the hn
[info] Starting Mixed Precision
[info] Mixed Precision is done (completion time is 00:00:00.10)
[info] LayerNorm Decomposition skipped
[info] Starting Statistics Collector
[info] Using dataset with 64 entries for calibration
Calibration: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 64/64 [00:09<00:00, 6.77entries/s]
[info] Statistics Collector is done (completion time is 00:00:09.84)
[info] Starting Fix zp_comp Encoding
[info] Fix zp_comp Encoding is done (completion time is 00:00:00.00)
[info] Matmul Equalization skipped
[info] No shifts available for layer model/conv1/conv_op, using max shift instead. delta=2.8604
[info] Finetune encoding skipped
[info] Bias Correction skipped
[info] Adaround skipped
[info] Quantization-Aware Fine-Tuning skipped
[info] Layer Noise Analysis skipped
[info] The calibration set seems to not be normalized, because the values range is [(0.0, 1.0), (0.0, 1.0), (0.0, 1.0)].
Since the neural core works in 8-bit (between 0 to 255), a quantization will occur on the CPU of the runtime platform.
Add a normalization layer to the model to offload the normalization to the neural core.
Refer to the user guide Hailo Dataflow Compiler user guide / Model Optimization / Optimization Related Model Script Commands / model_modification_commands / normalization for details.
[info] Model Optimization is done
[info] Saved HAR to: /home/hailo-test/onnx-to-hailo/model_optimized.har
- compile
hailo compiler --hw-arch hailo8 model_optimized.har
[info] Current Time: 18:33:52, 11/09/24
[info] CPU: Architecture: x86_64, Model: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz, Number Of Cores: 16, Utilization: 0.6%
[info] Memory: Total: 30GB, Available: 26GB
[info] System info: OS: Linux, Kernel: 5.15.0-122-generic
[info] Hailo DFC Version: 3.29.0
[info] HailoRT Version: Not Installed
[info] PCIe: No Hailo PCIe device was found
[info] Running `hailo compiler --hw-arch hailo8 model_optimized.har`
[info] Compiling network
[info] To achieve optimal performance, set the compiler_optimization_level to "max" by adding performance_param(compiler_optimization_level=max) to the model script. Note that this may increase compilation time.
[info] Loading network parameters
[info] Starting Hailo allocation and compilation flow
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=75%, max_compute_utilization=75%, max_compute_16bit_utilization=75%, max_memory_utilization (weights)=75%, max_input_aligner_utilization=75%, max_apu_utilization=75%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=75%, max_compute_utilization=75%, max_compute_16bit_utilization=75%, max_memory_utilization (weights)=75%, max_input_aligner_utilization=75%, max_apu_utilization=75%
Validating context_0 layer by layer (100%)
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
● Finished
[info] Solving the allocation (Mapping), time per context: 59m 59s
Context:0/0 Iteration 4: Trying parallel mapping...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost
worker0 V V V V V V V V V
worker1 V V V V V V V V V
worker2 V V V V V V X V V
worker3 V V V V V V V V V
00:34
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 0
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] Iterations: 4
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 0
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] +-----------+---------------------+---------------------+--------------------+
[info] | Cluster | Control Utilization | Compute Utilization | Memory Utilization |
[info] +-----------+---------------------+---------------------+--------------------+
[info] | cluster_0 | 50% | 46.9% | 41.4% |
[info] | cluster_1 | 31.3% | 20.3% | 27.3% |
[info] | cluster_2 | 68.8% | 85.9% | 53.1% |
[info] | cluster_3 | 100% | 92.2% | 68% |
[info] | cluster_4 | 68.8% | 60.9% | 68% |
[info] | cluster_5 | 81.3% | 85.9% | 85.2% |
[info] | cluster_6 | 18.8% | 7.8% | 6.3% |
[info] | cluster_7 | 12.5% | 14.1% | 17.2% |
[info] +-----------+---------------------+---------------------+--------------------+
[info] | Total | 53.9% | 51.8% | 45.8% |
[info] +-----------+---------------------+---------------------+--------------------+
[info] Successful Mapping (allocation time: 1m 10s)
[info] Compiling context_0...
[info] Bandwidth of model inputs: 3.96094 Mbps, outputs: 0.0515747 Mbps (for a single frame)
[info] Bandwidth of DDR buffers: 0.0 Mbps (for a single frame)
[info] Bandwidth of inter context tensors: 0.0 Mbps (for a single frame)
[info] Building HEF...
[info] Successful Compilation (compilation time: 43s)
[info] Compilation complete
[info] Saved HEF to: /home/hailo-test/onnx-to-hailo/model.hef
[info] Saved HAR to: /home/hailo-test/onnx-to-hailo/model_compiled.har