Hello everyone in the community! As shown in the question, I am parsing the model, but it seems that the reshape and transpose nodes in the model cannot be
Uploading: 微信图片_20250107114715.png…
converted properly. I have tried to replace reshape with squeeze, but still cannot modify the dimensions. The reason for the problem is that onnx is in the data format chw, but is the har model in hwc? Is there any solution?
This is my partial model:
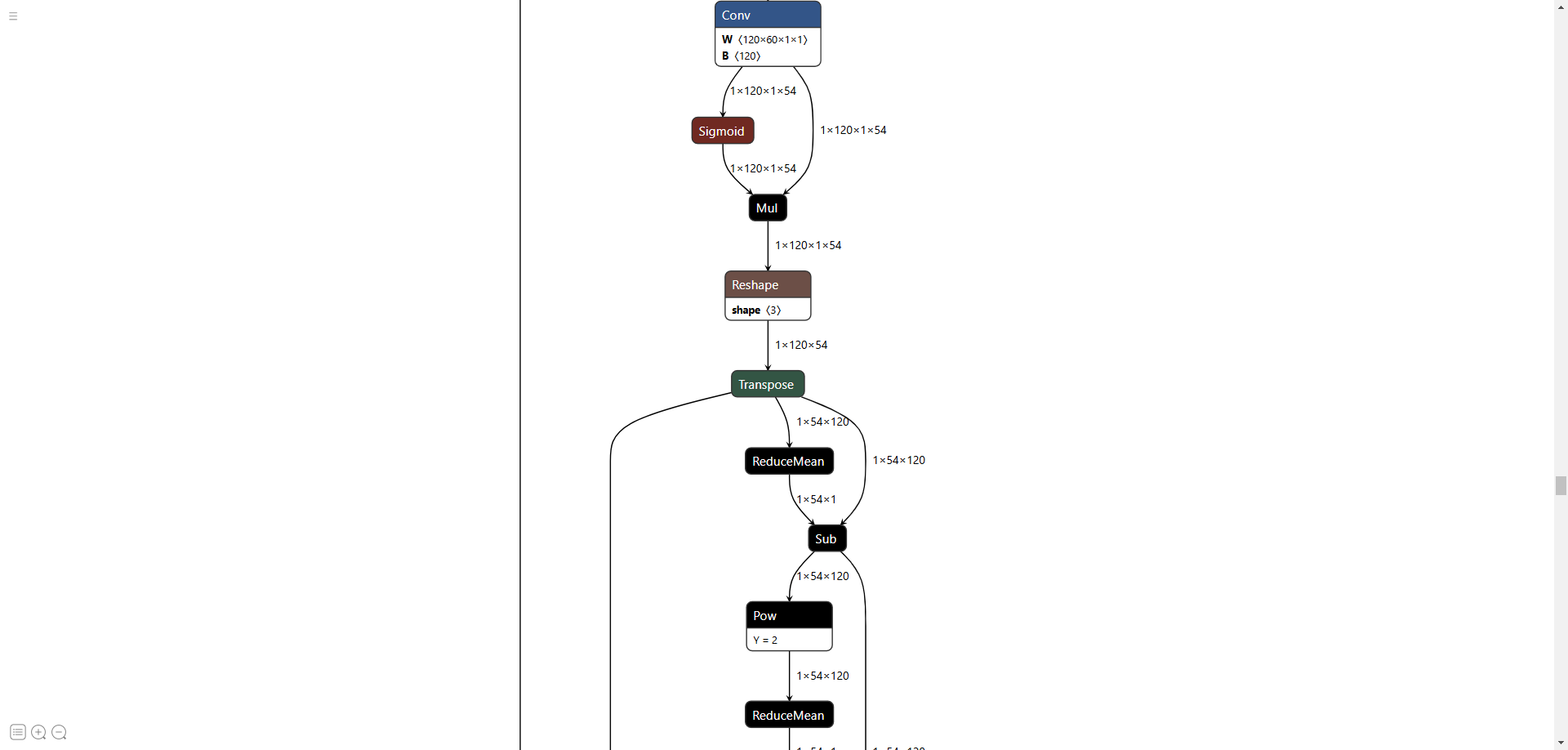
Hi @user61,
You’re right about the color scheme issue - this is related to a data format mismatch between ONNX (CHW) and Hailo (HWC). Let me provide two ways to fix this:
Option 1 - Fix During Model Export (Recommended):
- Add this to your PyTorch model before export:
model_output = model(input_tensor)
model_output = model_output.permute(0, 2, 3, 1) # Convert CHW to HWC
torch.onnx.export(
model,
input_tensor,
"model.onnx",
input_names=["input"],
output_names=["output"]
)
Option 2 - Fix the ONNX Model Directly:
If you already have the ONNX model, you can modify it:
import onnx
from onnx import helper
# Load and modify ONNX model
model = onnx.load("model.onnx")
transpose_node = helper.make_node(
'Transpose',
inputs=['input'],
outputs=['transposed_input'],
perm=[0, 2, 3, 1] # CHW to HWC
)
model.graph.node.insert(0, transpose_node)
onnx.save(model, "modified_model.onnx")
# Use modified model in Hailo pipeline
hailo parser modified_model.onnx
hailo optimize model.har
hailo compile model.har --hef model.hef
Try Option 1 first as it’s simpler. If that doesn’t work for your setup, then go with Option 2.
Let me know if you need any clarification!
Best regards,
Omria
Thank you for your reply. I have already resolved this issue, but I have encountered a new problem while quantifying it.
The problem is as follows:
Quantization failed in layer rec_onnx/ew_mult4 due to unsupported required slope. Desired shift is 107.0, but op has only 8 data bits. This error raises when the data or weight range are not balanced. Mostly happens when using random calibration-set/weights, the calibration-set is not normalized properly or batch-normalization was not used during training.
What does this mean? What does quantization into 8-bit mean? Why does it parse into a har model? Test Native Model is completely fine, but quantization fails. What does Desired shift 107.0 mean? I would be extremely grateful if you could answer my question.
My input data has been batch standardized