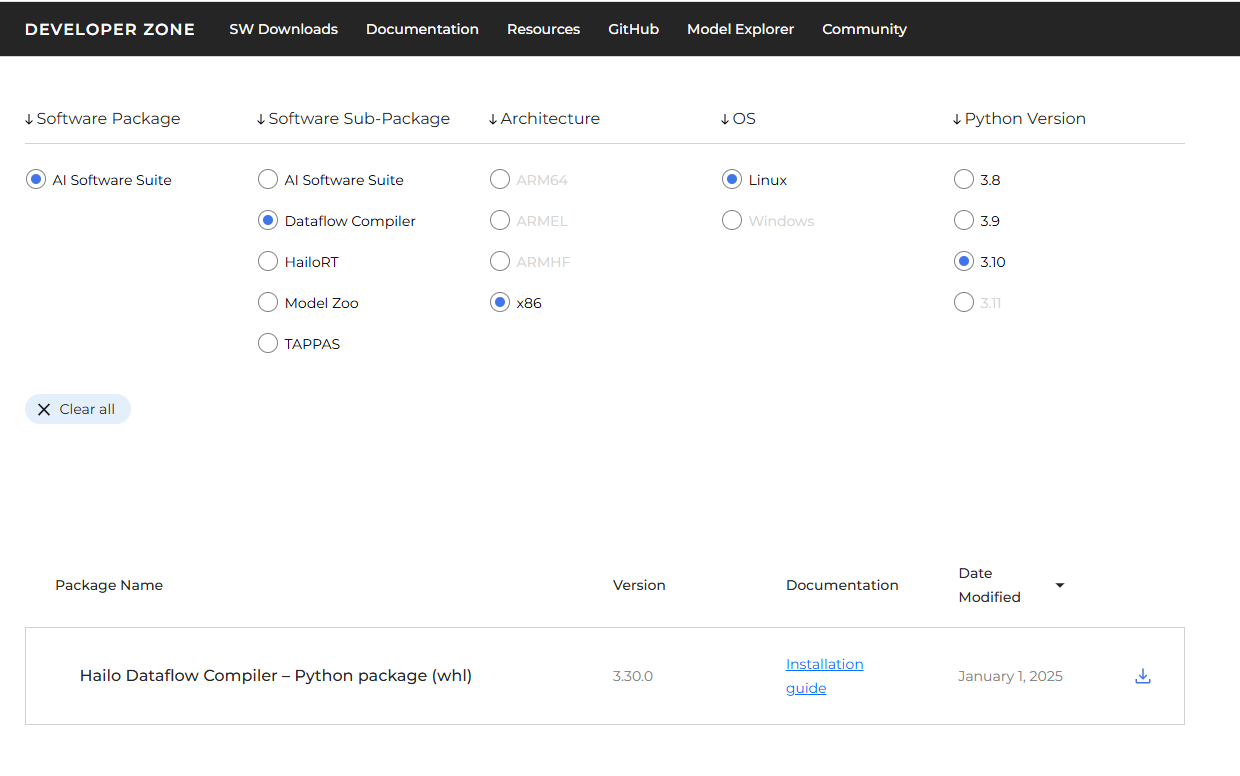
For everyone’s consideration, I find this morning an update available hailo_dataflow_compiler-3.30.0-py3-none-linux_x86_64.whl.
1 Like
I created three separate Colab notebooks for converting to .hef. I used the YOLOv8n version from the Ultralytics library. I have commented on the necessary steps in each notebook.
1 .Create a model:Colab Notebook
2. Create a calibration dataset: [Google Colab](https://Colab Notebook)
3. Convert the model: Colab notebook
The notebooks were created thanks to the inspiration from the awesome community’s work. Cheers to everyone!
5 Likes
In the case that anyone’s receiving the error:
ERROR: Could not find a version that satisfies the requirement onnxruntime==1.12.1 (from versions: 1.15.0, 1.15.1, 1.16.0)
ERROR: No matching distribution found for onnxruntime==1.12.1
from making installing the WHL, Colab seems to be installing python release 3.11.11, which our .whl file doesn’t work on. Make sure to use python3.10:
!sudo apt update
!sudo apt install python3.10
!sudo apt install python3.10-venv
!python3.10 -m venv my_env
4 Likes
Fixed the Optimization Issue
For this I referred to this article.
To do this in colab, this is what I did:
Step 1:
!wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
Step 2:
!sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
Step 3:
!sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-D95DBBE2-keyring.gpg /usr/share/keyrings/
Step 4:
!sudo apt-get update
Step 5:
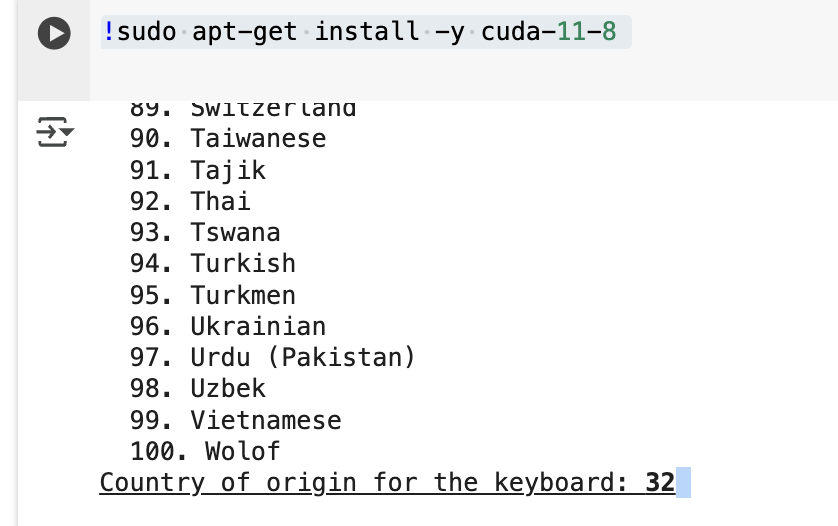
!sudo apt-get install -y cuda-11-8
For this step you have to fill provide the language, I’m using English as my default so I entered “32”, then “1” for the dialect of english. There should be a little text box next to the terminal prompt, so click the area next to it and you should be able to type.

Step 6:
!echo 'export PATH=/usr/local/cuda-11.8/bin:$PATH' >> ~/.bashrc
!echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
!source ~/.bashrc
Step 7:
!ls /usr/local | grep cuda
This step is just a sanity check to see if Cuda 11.8 was installed.
Step 8:
!sudo ln -sf /usr/local/cuda-11.8 /usr/local/cuda
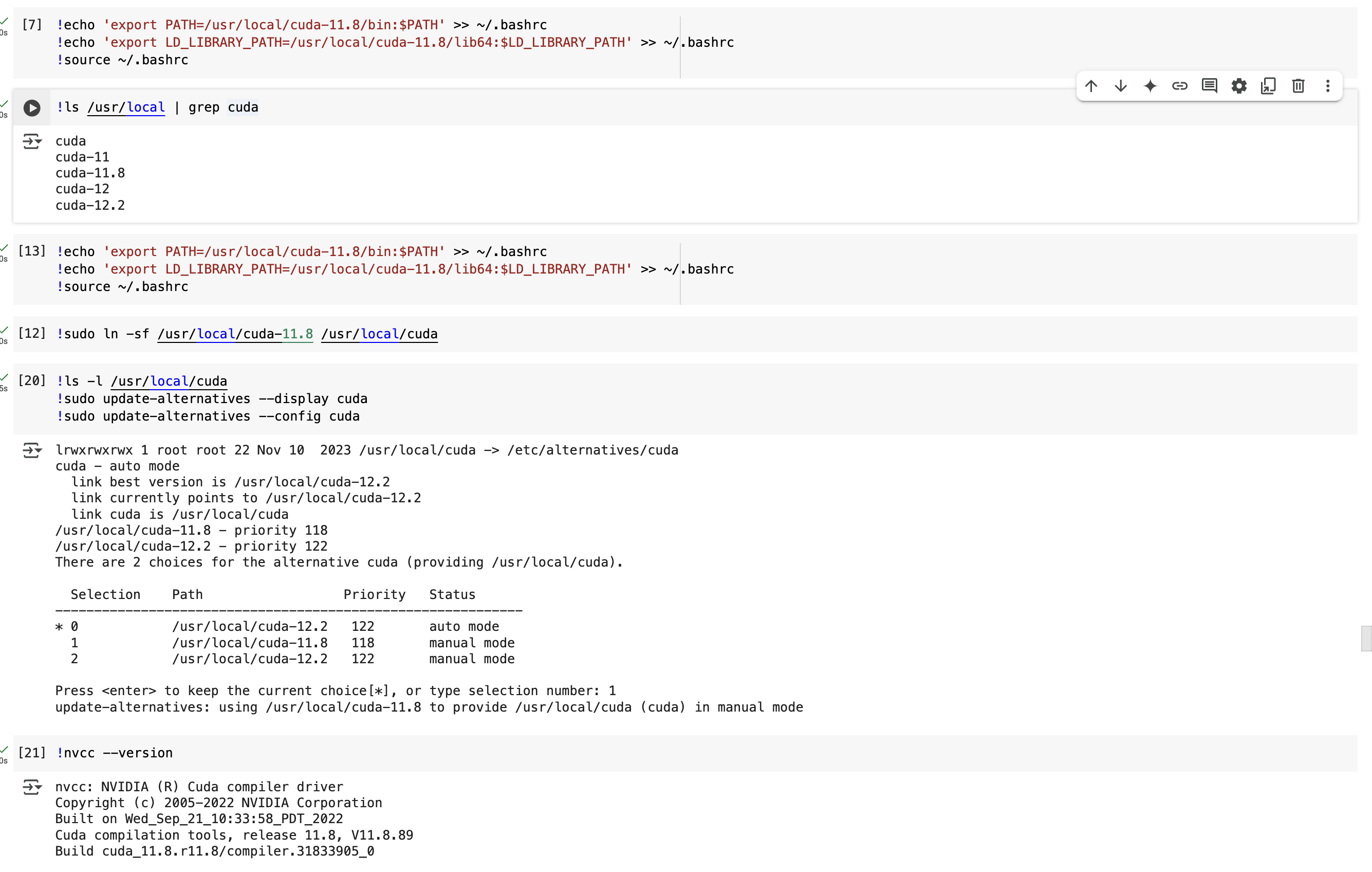
Step 9:
!ls -l /usr/local/cuda
!sudo update-alternatives --display cuda
!sudo update-alternatives --config cuda
This should be the expected output, for the last couple steps.
I did this step right before the second step of the compilation process, but you can do it at any time before optimization.
Note: For optimization level 1, you will need at least a calibration dataset of 64 images. For optimization level 2, you will need 1024 images.
2 Likes
Forgot to mention, enter whatever number corresponding to cuda 11.8 in step 9 in the little pop up box, for me it was “1”.
I got a series of errors after due to Colab not recognizing cublas. To solve this…
Step 1:
!apt-get update
!apt-get install -y libnvinfer8=8.5.2-1+cuda11.8 libnvinfer-dev=8.5.2-1+cuda11.8 libnvinfer-plugin8=8.5.2-1+cuda11.8
!apt-get install -y libcublas-11-8
Step 2:
!nvidia-smi
!sudo ln -sf /usr/local/cuda-11.8 /usr/local/cuda
!sudo ln -sf /usr/local/cuda-11.8/lib64/libcudart.so /usr/lib/x86_64-linux-gnu/libcudart.so
!sudo ln -sf /usr/local/cuda-11.8/lib64/libcublas.so /usr/lib/x86_64-linux-gnu/libcublas.so
!sudo ln -sf /usr/local/cuda-11.8/lib64/libcublasLt.so /usr/lib/x86_64-linux-gnu/libcublasLt.so
!sudo apt-get remove --purge -y libnvinfer10
Step 3:
!dpkg -l | grep nvinfer
!ls -l /usr/lib/x86_64-linux-gnu/libnvinfer*
Step 4:
!sudo apt-get autoremove -y
!sudo apt-get autoclean
!sudo apt-get install -y libnvinfer8=8.5.2-1+cuda11.8 libnvinfer-dev=8.5.2-1+cuda11.8 libnvinfer-plugin8=8.5.2-1+cuda11.8
Step 5:
!echo 'export PATH=/usr/local/cuda-11.8/bin${PATH:+:${PATH}}' >> ~/.bashrc
!echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' >> ~/.bashrc
!source ~/.bashrc
Step 6:
!my_env/bin/pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Step 7:
!my_env/bin/pip uninstall scipy
!my_env/bin/pip install scipy==1.9.3
Step 8:
!my_env/bin/python optimize_model.py
After this and the steps above in my most recent reply, all of the warnings about GPU not being detected are gone, and it properly goes through the optimization process. It should look like this.
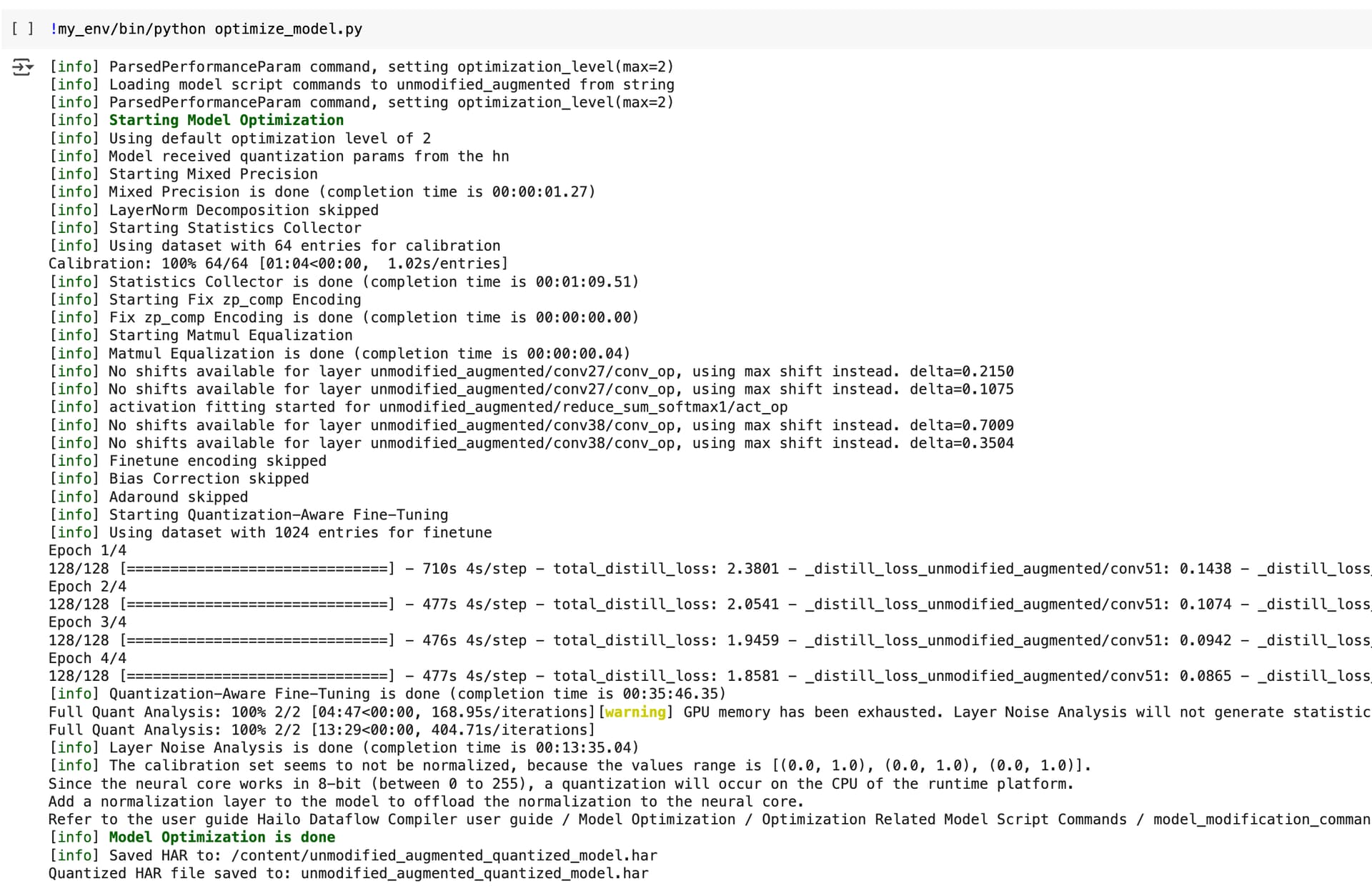
The final compilation should proceed as normal.
2 Likes
Hello there,
I followed your steps and im now running optimize_model.py succesfully. However i encounter this warning:
[warning] Dataset is larger than expected size. Increasing the algorithm dataset size might improve the results
[info] Using dataset with 1024 entries for finetune
how do I increase this? my dataset is 7000 images
I took just the first 1024 entries, from that log I believe you are using the entire dataset.
An example:
# Mounting Google Drive
drive.mount('/content/drive/', force_remount=True)
# Paths to directories and files
image_dir = '/content/drive/MyDrive/path_to_dataset/train/images'
output_dir = '/content/'
final_output_path = '/content/calibration_data_1024.npy'
# Create the output directories if they don't exist
os.makedirs(output_dir, exist_ok=True)
# Get the list of images, limited to 1024
image_files = [f for f in os.listdir(image_dir) if f.lower().endswith(('.jpg', '.jpeg', '.png'))]
image_files = image_files[:1024] # Take only the first 1024 images
If you run into memory issues even with High-RAM, you could process them in batches as individual .npy arrays, then concat them later.
For the purpose of optimization, around 1024 images is good enough. Having a lot more can sometimes decrease the accuracy as it will capture more outliers, which will increase the dynamic range of the activate layers to be quantized.
1 Like
Where? I can’t seem to find any. Could you provide some links please?
1 Like
Yup, here are some:
- https://community.hailo.ai/t/parsing-yolo-models-with-the-hailo-dataflow-compiler-tool/2384
- https://community.hailo.ai/t/difficulties-retraining-yolov5/4977/4
- https://github.com/hailo-ai/hailo_model_zoo/issues/24
- https://community.hailo.ai/t/running-hailomz-optimize-reports-layer-yolov8n-conv41-doesnt-have-one-output-layer/4854/9
- https://community.hailo.ai/t/convert-yolo-pytorch-model-to-hef-for-raspberry-pi-5-with-hailo8l/2673/5
These are just some, the first article should be the most helpful, but the process that we both outlined is just for yolo, not for other models.
1 Like
Thank you so much, my friend! Your guidance is truly a gem for beginners like me who are just starting out with this. You’ve helped me a lot—I managed to compile to HEF format and optimize my model. I really appreciate it!
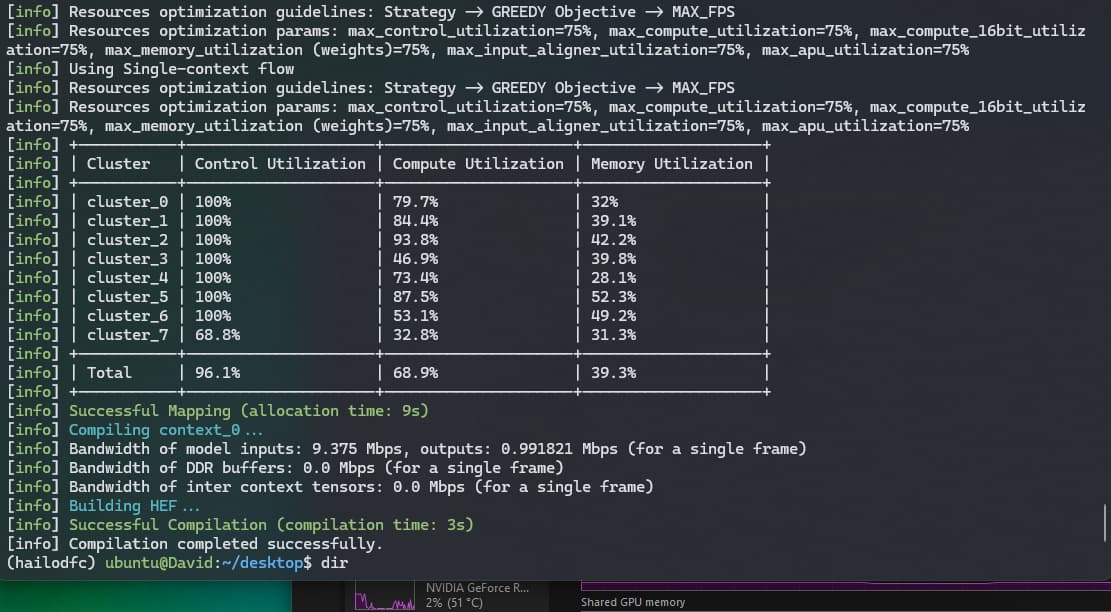
1 Like
I compiled my yolov11m model using the guide and collab above (slightly modified to work correctly), but when i try to test it on an image on my rpi5 with the ai hat+ (hailo8) I cant seem to get any detection, I get around 22fps when running the model on multiple images but 0 objects detected. Any idea why that might be?
Try to convert the input from BGR to RGB on your inference script, that fixes mine, if that didn’t work, Check the .har inference performance on your host machine
Thanks for the reply, I tried both rgb and bgr formats and both show no detections, also when I ran the compile.py in the notebook the process took around 12 hours, idk if that is normal for everyone or it should be lower and I messed up something.
The long compilation time sounds right, that’s what I was also getting. Also several updates for the optimization step, colab recently updated their cuDNN to 9, however with the DFC 3.29, and 3.3 it doesn’t seem to recognize the T4 GPU, so I downgraded by the following:
You can find the deb here, it is under the dropdown, Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 11.x, this is to be combined with the previous step of downgrading to cuda 11.8, which can be found earlier in this post. This is how to install it.
!sudo dpkg -i "/path/to/cudnn-local-repo-ubuntu2204-8.9.7.29_1.0-1_amd64.deb"
!sudo cp /var/cudnn-local-repo-ubuntu2204-8.9.7.29/cudnn-local-*.key /usr/share/keyrings/
!sudo apt-get update
!sudo apt-get install libcudnn8 libcudnn8-dev libcudnn8-samples -y
I’m currently in the process of doing another conversion because I was getting a lot of duplicate detections, but will update once completed to see if the HEF file still struggles.
Okay I am going to try to downgrade cuDNN and see if that helps, in case it doesnt would you be able to share your notebook once you are done with your do your convertion successfully ?
Hello, when i run python optimize_model.py, I got issue:
I use yolov11n-seg with 1 classes, input_name: images.
this is my node:
# Use the recommended end node names for translation
end_node_names = [
"/model.23/cv2.0/cv2.0.2/Conv",
"/model.23/cv3.0/cv3.0.2/Conv",
"/model.23/cv2.1/cv2.1.2/Conv",
"/model.23/cv3.1/cv3.1.2/Conv",
"/model.23/cv2.2/cv2.2.2/Conv",
"/model.23/cv3.2/cv3.2.2/Conv",
]
(hailodfc) devpham@DevPham:~$ python optimize_model.py
[info] ParsedPerformanceParam command, setting optimization_level(max=2)
[info] Loading model script commands to best_rename from string
[info] ParsedPerformanceParam command, setting optimization_level(max=2)
[info] Found model with 3 input channels, using real RGB images for calibration instead of sampling random data.
[info] Starting Model Optimization
[warning] Reducing optimization level to 0 (the accuracy won't be optimized and compression won't be used) because there's less data than the recommended amount (1024), and there's no available GPU
[warning] Running model optimization with zero level of optimization is not recommended for production use and might lead to suboptimal accuracy results
[info] Model received quantization params from the hn
Traceback (most recent call last):
File "/home/devpham/optimize_model.py", line 35, in <module>
runner.optimize(calib_dataset)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_common/states/states.py", line 16, in wrapped_func
return func(self, *args, **kwargs)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_client/runner/client_runner.py", line 2201, in optimize
result = self._optimize(
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_common/states/states.py", line 16, in wrapped_func
return func(self, *args, **kwargs)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_client/runner/client_runner.py", line 2020, in _optimize
checkpoint_info = self._sdk_backend.full_quantization(
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_client/sdk_backend/sdk_backend.py", line 1196, in full_quantization
new_checkpoint_info = self._full_acceleras_run(
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_client/sdk_backend/sdk_backend.py", line 1434, in _full_acceleras_run
new_checkpoint_info = self._optimization_flow_runner(optimization_flow, checkpoint_info)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_sdk_client/sdk_backend/sdk_backend.py", line 2088, in _optimization_flow_runner
optimization_flow.run()
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/tools/orchestator.py", line 239, in wrapper
return func(self, *args, **kwargs)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/flows/optimization_flow.py", line 357, in run
step_func()
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/tools/subprocess_wrapper.py", line 154, in parent_wrapper
self.build_model()
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/flows/optimization_flow.py", line 260, in build_model
model.compute_output_shape(shapes)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/acceleras/model/hailo_model/hailo_model.py", line 1153, in compute_output_shape
return self.compute_and_verify_output_shape(input_shape, verify_layer_inputs_shape=False)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/acceleras/model/hailo_model/hailo_model.py", line 1187, in compute_and_verify_output_shape
layer_output_shape = layer.compute_output_shape(layer_input_shapes)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/keras/engine/base_layer.py", line 917, in compute_output_shape
outputs = self(inputs, training=False)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/keras/utils/traceback_utils.py", line 70, in error_handler
raise e.with_traceback(filtered_tb) from None
File "/tmp/__autograph_generated_filecr64q5lt.py", line 41, in tf__call
outputs = ag__.converted_call(ag__.ld(self).call_core, (ag__.ld(inputs), ag__.ld(training)), dict(**ag__.ld(kwargs)), fscope)
File "/tmp/__autograph_generated_filecmb9y4fj.py", line 90, in tf__call_core
ag__.if_stmt(ag__.ld(self).postprocess_type in [ag__.ld(PostprocessType).NMS, ag__.ld(PostprocessType).BBOX_DECODER], if_body_3, else_body_3, get_state_3, set_state_3, ('do_return', 'retval_'), 2)
File "/tmp/__autograph_generated_filecmb9y4fj.py", line 22, in if_body_3
retval_ = ag__.converted_call(ag__.ld(self).bbox_decoding_and_nms_call, (ag__.ld(inputs),), dict(is_bbox_decoding_only=ag__.ld(self).postprocess_type == ag__.ld(PostprocessType).BBOX_DECODER), fscope)
File "/tmp/__autograph_generated_file525amlyj.py", line 116, in tf__bbox_decoding_and_nms_call
ag__.if_stmt(ag__.ld(self).meta_arch in [ag__.ld(NMSOnCpuMetaArchitectures).YOLOV5, ag__.ld(NMSOnCpuMetaArchitectures).YOLOX], if_body_5, else_body_5, get_state_5, set_state_5, ('decoded_bboxes', 'detection_score', 'do_return', 'retval_', 'inputs'), 4)
File "/tmp/__autograph_generated_file525amlyj.py", line 113, in else_body_5
ag__.if_stmt(ag__.ld(self).meta_arch == ag__.ld(NMSOnCpuMetaArchitectures).YOLOV5_SEG, if_body_4, else_body_4, get_state_4, set_state_4, ('decoded_bboxes', 'detection_score', 'do_return', 'retval_'), 4)
File "/tmp/__autograph_generated_file525amlyj.py", line 110, in else_body_4
ag__.if_stmt(ag__.ld(self).meta_arch == ag__.ld(NMSOnCpuMetaArchitectures).YOLOV8, if_body_3, else_body_3, get_state_3, set_state_3, ('decoded_bboxes', 'detection_score'), 2)
File "/tmp/__autograph_generated_file525amlyj.py", line 69, in if_body_3
(decoded_bboxes, detection_score) = ag__.converted_call(ag__.ld(self).yolov8_decoding_call, (ag__.ld(inputs),), dict(offsets=[0.5, 0.5]), fscope)
File "/tmp/__autograph_generated_filekxohwso9.py", line 87, in tf__yolov8_decoding_call
decoded_bboxes = ag__.converted_call(ag__.ld(tf).expand_dims, (ag__.ld(decoded_bboxes),), dict(axis=2), fscope)
ValueError: Exception encountered when calling layer "yolov8_nms_postprocess" (type HailoPostprocess).
in user code:
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/acceleras/hailo_layers/base_hailo_none_nn_core_layer.py", line 45, in call *
outputs = self.call_core(inputs, training, **kwargs)
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/acceleras/hailo_layers/hailo_postprocess.py", line 123, in call_core *
is_bbox_decoding_only=self.postprocess_type == PostprocessType.BBOX_DECODER,
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/acceleras/hailo_layers/hailo_postprocess.py", line 157, in bbox_decoding_and_nms_call *
decoded_bboxes, detection_score = self.yolov8_decoding_call(inputs, offsets=[0.5, 0.5])
File "/home/devpham/hailodfc/lib/python3.10/site-packages/hailo_model_optimization/acceleras/hailo_layers/hailo_postprocess.py", line 375, in yolov8_decoding_call *
decoded_bboxes = tf.expand_dims(decoded_bboxes, axis=2)
ValueError: Tried to convert 'input' to a tensor and failed. Error: None values not supported.
Call arguments received by layer "yolov8_nms_postprocess" (type HailoPostprocess):
• inputs=['tf.Tensor(shape=(None, 80, 80, 64), dtype=float32)', 'tf.Tensor(shape=(None, 80, 80, 4), dtype=float32)', 'tf.Tensor(shape=(None, 40, 40, 64), dtype=float32)', 'tf.Tensor(shape=(None, 40, 40, 4), dtype=float32)', 'tf.Tensor(shape=(None, 20, 20, 64), dtype=float32)', 'tf.Tensor(shape=(None, 20, 20, 4), dtype=float32)']
• training=False
• kwargs=<class 'inspect._empty'>
This is my nms config:
{
"nms_scores_th": 0.2,
"nms_iou_th": 0.7,
"image_dims": [
640,
640
],
"max_proposals_per_class": 100,
"classes": 1,
"regression_length": 16,
"background_removal": false,
"background_removal_index": 0,
"bbox_decoders": [
{
"name": "bbox_decoder51",
"stride": 8,
"reg_layer": "conv51",
"cls_layer": "conv54"
},
{
"name": "bbox_decoder62",
"stride": 16,
"reg_layer": "conv62",
"cls_layer": "conv65"
},
{
"name": "bbox_decoder77",
"stride": 32,
"reg_layer": "conv77",
"cls_layer": "conv80"
}
]
}
this is my alls:
normalization1 = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])
change_output_activation(conv54, sigmoid)
change_output_activation(conv65, sigmoid)
change_output_activation(conv80, sigmoid)
nms_postprocess("/save_nms/path/nms_layer_config.json", meta_arch=yolov8, engine=cpu)
performance_param(compiler_optimization_level=max)
I can’t share the entire notebook, only snippets, however, here is the appropriate commands for reverting cuDNN.
!wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
!sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.deb
!sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-D95DBBE2-keyring.gpg /usr/share/keyrings/
!sudo apt-get update
!sudo apt-get install -y cuda-11-8
!sudo ln -sf /usr/local/cuda-11.8 /usr/local/cuda
Press 1 when prompted, should be 11.8
( 1 /usr/local/cuda-11.8 118 manual mode )
!ls -l /usr/local/cuda
!sudo update-alternatives --display cuda
!sudo update-alternatives --config cuda
Verify:
!nvcc --version
Next step:
import os
!tar -xvf "path/to/cudnn-linux-x86_64-8.9.7.29_cuda11-archive.tar.xz"
!sudo cp cudnn-linux-x86_64-8.9.7.29_cuda11-archive/include/* /usr/local/cuda/include/
!sudo cp cudnn-linux-x86_64-8.9.7.29_cuda11-archive/lib/* /usr/local/cuda/lib64/
os.environ['PATH'] = '/usr/local/cuda/bin:' + os.environ['PATH']
os.environ['LD_LIBRARY_PATH'] = '/usr/local/cuda/lib64:' +
os.environ.get('LD_LIBRARY_PATH', '')
Reverting scipy:
!my_env/bin/pip install scipy==1.8.1 numpy==1.23.3
This should solve your optimization errors. I was able to do a compilation and it isn’t as accurate as the .pt so will have to keep looking into it.
I’m working on a hobby project with the Raspberry Pi 5 and Hailo-8L AI HAT, using a custom-trained YOLOv5 model. I’ve already exported it to ONNX, but I’m unable to convert it to .hef because the Dataflow Compiler is not publicly available.
Could you please let me know how to obtain the compiler, or what the correct procedure is to get access as an individual developer?
Thanks in advance!