YOLO is a known and frequently used object detection model created by Ultralytics. It has many architecture versions - v3,v4,v5,v6,x,v7,v8,v9,10 and many sub-versions.
The yolo models are built with a backbone and a detection head, when it can be divided into two groups - anchor based models, such as yolov5 and yolov7, and anchor free models, such as yolov6, yolox, yolov8 etc.
In this post I’ll take to representative models to explain how to parse the YOLO models using Hailo’s Parser tool - yolov5 and yolov8.
Yolov5
Yolov5, as mentioned, is an anchor based YOLO model. The model detector head is composed of the detector neural ops and the postprocessing ops.
Hailo chip is a neural accelerator, and therefore is very good at running neural ops, but is less efficient in running post processing ops. This is way Hailo’s SW doesn’t support some postprocessing ops such as specific Reshape layer, Gather etc. that are not a neural op.
So, when coming to parse a yolov5 model with Hailo’s Parser (which is the first step of the Dataflow Compiler pipeline), we need to provide it with the relevant end nodes, meaning the last neural ops of the model, just before the postprocessing operations.
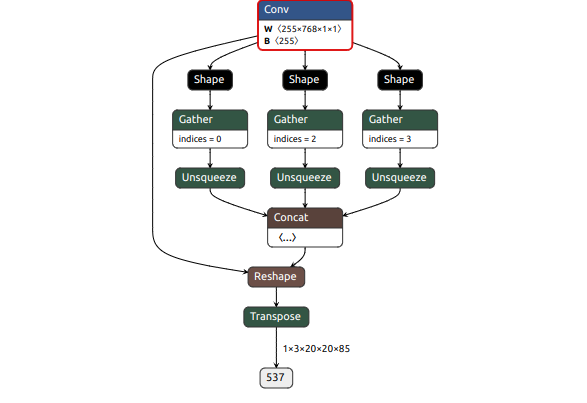
For example, in yolov5m, this would be an end node:
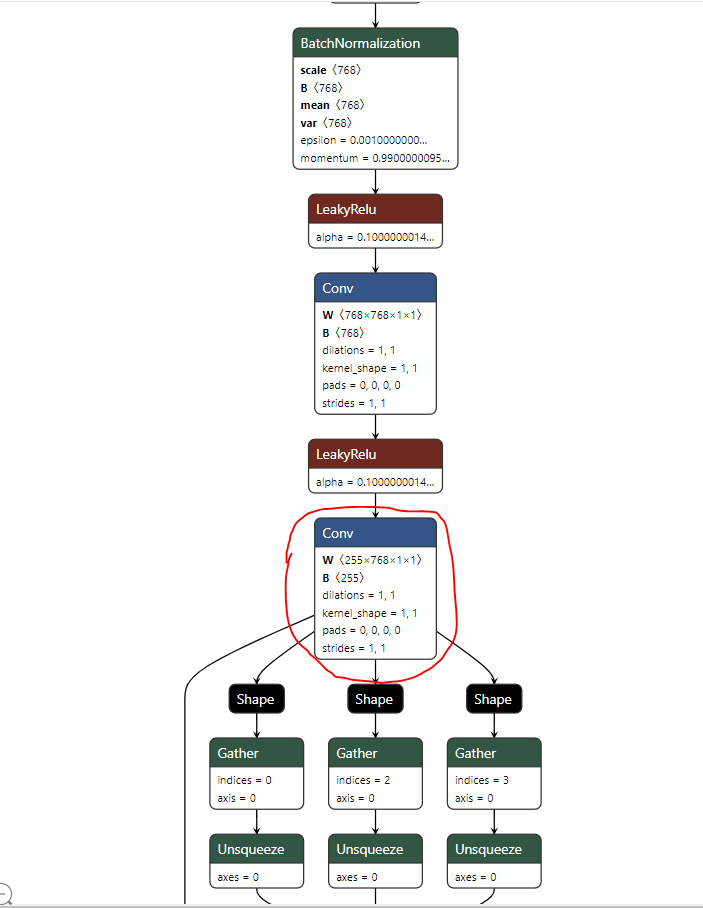
As it holds the bboxes and scores data of that branch, where after it comes only postprocessing ops.
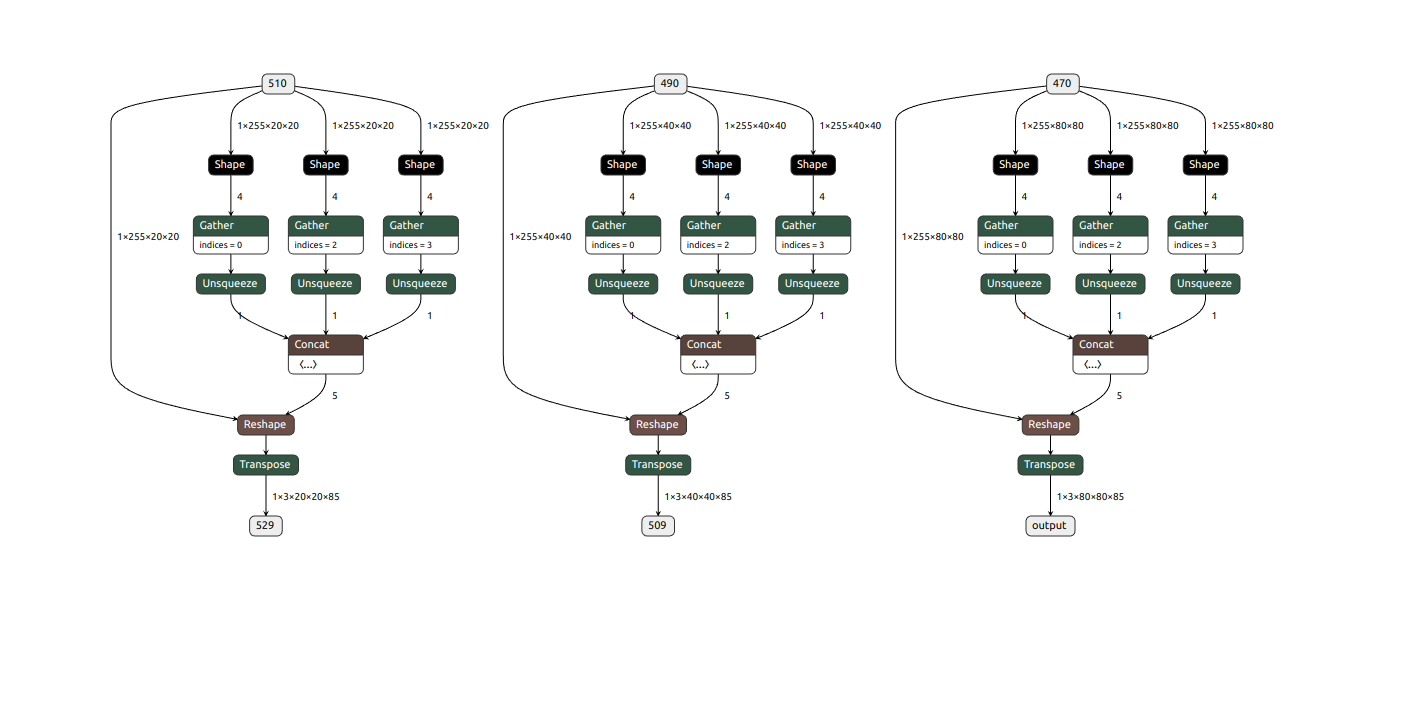
In total, for yolov5 (and yolov7) we’ll have 3 output nodes when running the Hailo Parser.
Yolov8
Yolov8 is an anchor free model, so it’s architecture is a bit different than that of yolov5.
While yolov5 have 3 branches containing each (in one node)
In this case, instead of 3 branches with 1 node containing the bboxes and scores data of that branch, yolov8 have 3 branches, each containing two nodes - one for the bbox data of the branch and the other with the scores data of it.
So, while for yolov5 we’ll have 3 end nodes in Hailo, for yolov8 we’ll have 6. An example for yolov8 branch for parsing would look like this:
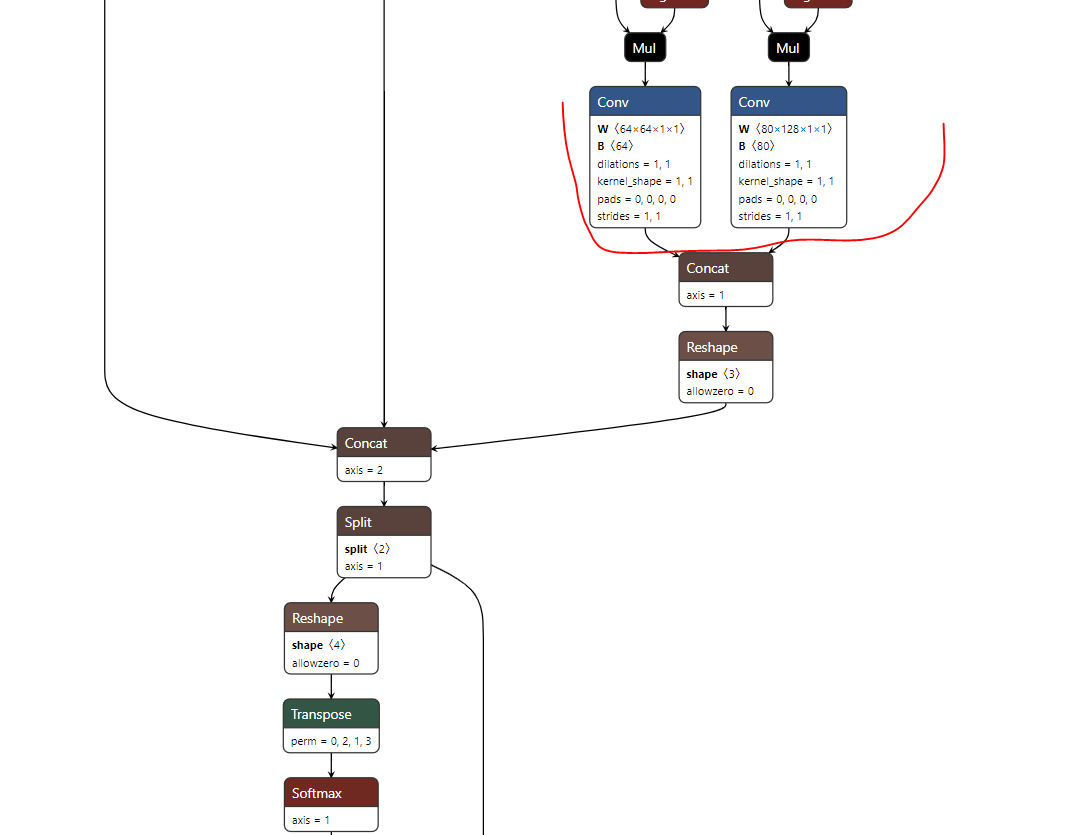
You can see that after it there are only postprocessing ops (for anyone checking, the convolution layer there after the Sofmax acts practically like a ReduceSum layer).
Of course, there are model with different number of end nodes for Hailo, but the rule of thumb is always the same - the end nodes would be the last neural ops, just before the postprocessing part of the model starts.