Hi everyone,
I have a question regarding the parsing step for YOLO models—specifically YOLOv5m and YOLOv9m. I read Parsing YOLO models with the Hailo Dataflow Compiler tool on converting an ONNX YOLO model to a HEF model using Hailo’s Dataflow Compiler tool.
My main concern is whether omitting the final layers of the architecture (such as Gather, Shape, Unsqueeze, Concat, etc.)—and stopping at the convolutional blocks—affects the mAP performance. For example, with YOLOv5, the parsed model only processes up to the convolutional blocks at scales of 80×80, 40×40, and 20×20 (see attached image).
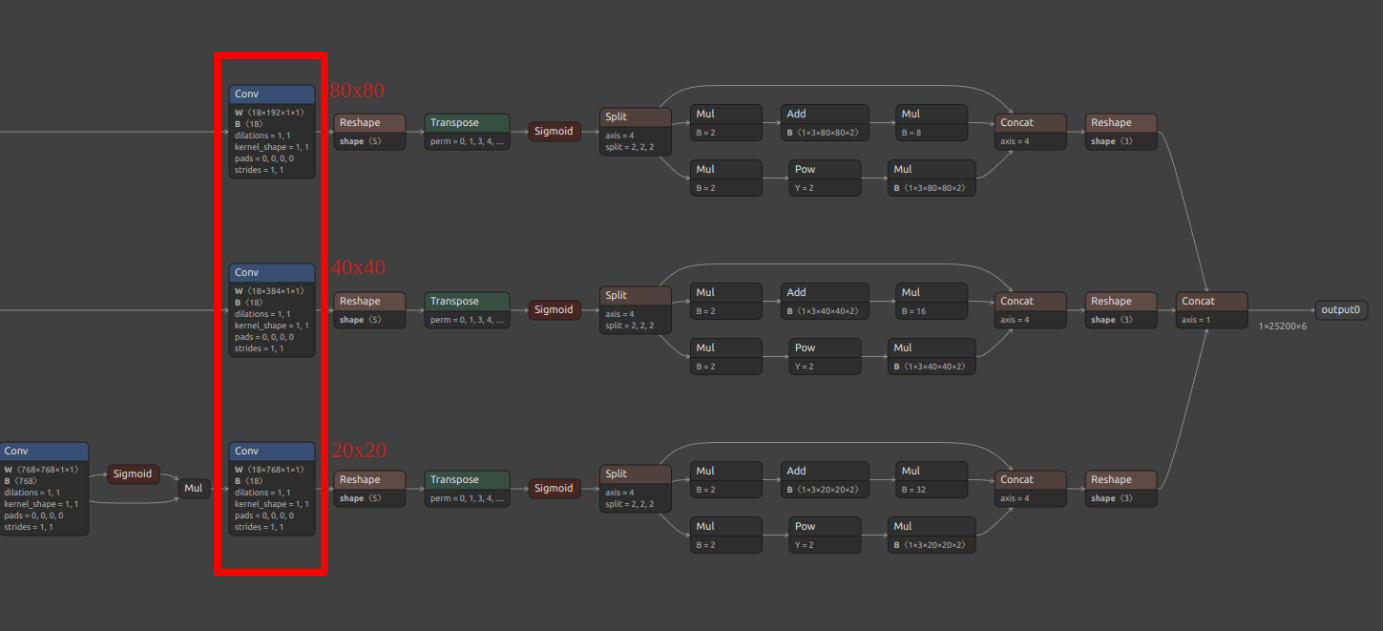
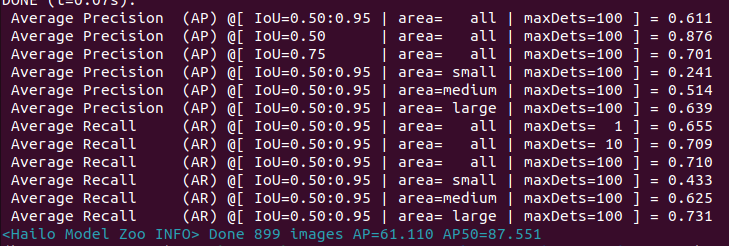
In evaluation, the ONNX model achieves a 0.648 mAP, but after parsing (and before quantization), the mAP drops to 0.611—a reduction of about 3%.
I have ensured that:
- The same validation dataset and preprocessing (normalization and resizing to 640×640) are used.
- The same NMS filter values are applied. (conf_thres = 0.25, iou_thres=0.45 and scores_thres=0.2 )
Thus, the only difference is that the parsed model uses Hailo’s NMS filter instead of the final architecture layers. (Correct me if there is something else I forgot or wrong)
My questions are:
- Is the removal of the final architectural layers the likely cause of the mAP degradation?
- What other factors might contribute to this drop in performance?
- Are there any strategies or solutions to minimize this degradation?
Thanks in advance for your insights and suggestions!