Hello, i am trying to compile the vision embedding from clip with the DFC. I have seen that hailo provides a demo for clip. But for my application, i have to be able to fine tune the model.
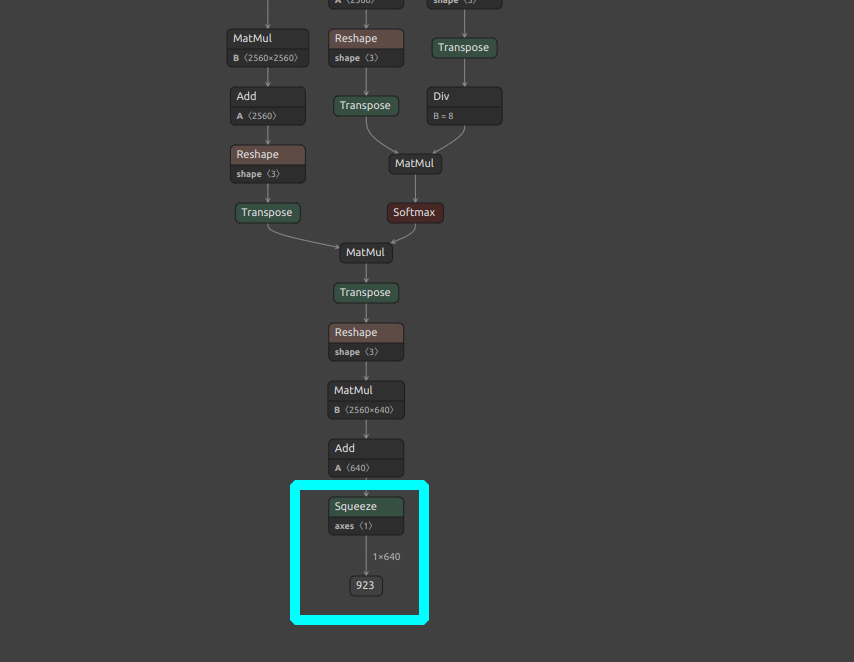
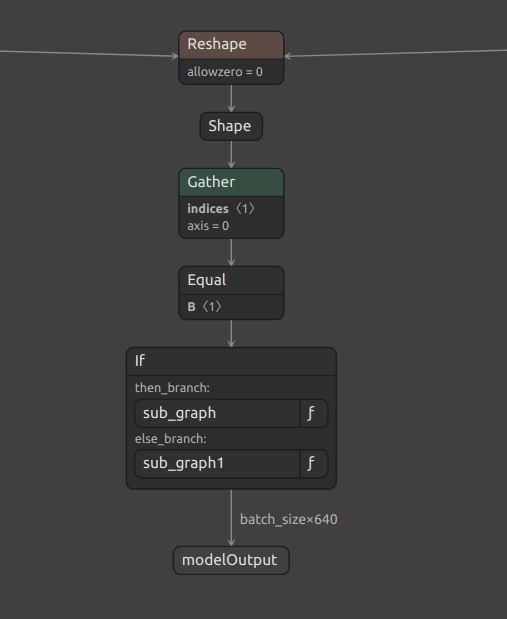
Currently i am getting a IndexError
in get_spatial_unflatten_reshape_info spatial_reshape_sizes = [output_shape[1], output_shape[2]] IndexError: list index out of range
I have read in a different post that hailo is working on the feature to compile Transformer.
However the demo for clip exists so there has to be a way to compile a vision transformer.
This is the code i use to get the onnx file of the ViT:
import torch
import clip
from PIL import Image
vision_arch = "ViT-B32"
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
print(clip.available_models())
vit = model.visual
textTransformer = model.token_embedding
image = preprocess(Image.open("CLIP/pics/constructionsite.png")).unsqueeze(0).to(device) # Picture input
# ==================== #
# Export Model as ONNX #
# ==================== #
torch.onnx.export(vit, # model being run
image, # model input (or a tuple for multiple inputs)
f"{vision_arch}.onnx", # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=15, # the ONNX version to export the model to
verbose=False, # print network to console
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['modelInput'], # the model's input names
output_names = ['modelOutput'], # the model's output names
dynamic_axes={'modelInput' : {0 : 'batch_size'}, # variable length axes
'modelOutput' : {0 : 'batch_size'}})
print(f"model saved as {vision_arch}.onnx")
Further this is the code i try to use to compile the ViT:
import onnx
# General imports used throughout the tutorial
import tensorflow as tf
from IPython.display import SVG
# import the ClientRunner class from the hailo_sdk_client package
from hailo_sdk_client import ClientRunner
chosen_hw_arch = "hailo8"
onnx_model_name = "ViT-B32"
onnx_path = f"models/{onnx_model_name}.onnx"
runner = ClientRunner(hw_arch=chosen_hw_arch)
_ = runner.translate_onnx_model(
onnx_path,
onnx_model_name,
start_node_names=["modelInput"],
end_node_names=["modelOutput"],
net_input_shapes={"modelInput": [1, 3, 224, 224]}
)
hailo_model_har_name = f"{onnx_model_name}_hailo_model.har"
runner.save_har(hailo_model_har_name)
Any help is welcome ![]() .
.