I’m converting yoloe-11s-seg model to hef.
Using hailomz parse to convert onnx to har is successful.
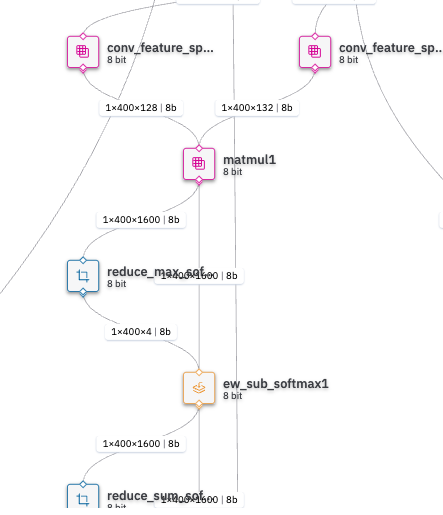
However, after quantizing the har file using hailomz optimize, the output of the Matmul1 layer changes to two during the hailomz compile process, resulting in the following error.
[error] Mapping Failed (allocation time: 8m 53s)
Failed to reach required FPS on the following layers:
Compilation failed with exception: More than one output is not supported for layer matmul1
[error] Failed to produce compiled graph
[error] BackendAllocatorException: Compilation failed: Failed to reach required FPS on the following layers:
Compilation failed with exception: More than one output is not supported for layer matmul1
My analysis of this issue that after optimization, the model’s structure changes so that matmul1’s output is split into two. So, if we can avoid this process, the conversion should succeed. Is there a way to do this?
- Before optimization har structure
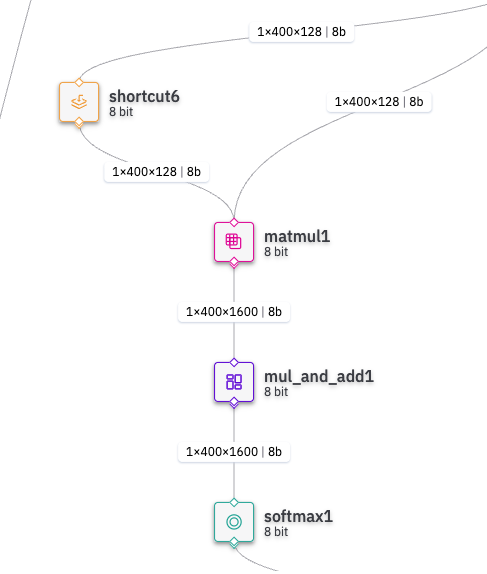
- After optimization har structure