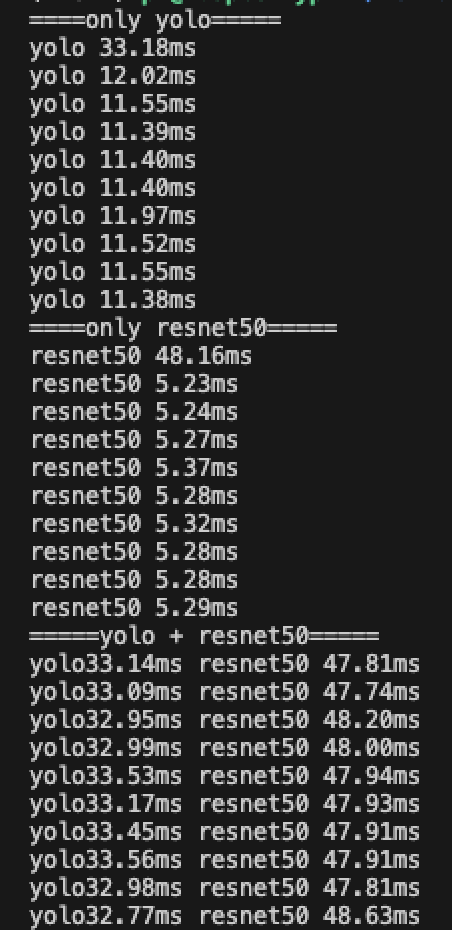
I initialize the device and vstreams only when the program starts in init().
I attach the C code and Python code.
#include <stdio.h>
#include <stdint.h>
#include <assert.h>
#include <math.h>
#include "hailo/hailort.h"
#define HEF_COUNT (2)
#define MAX_HEF_PATH_LEN (255)
#define MAX_EDGE_LAYERS (32)
// #define SCHEDULER_TIMEOUT_MS (0)
// #define SCHEDULER_THRESHOLD (0)
static char HEF_FILES[HEF_COUNT][MAX_HEF_PATH_LEN] = {"yolov5s_personface.hef", "resnet50.hef"};
static hailo_vdevice vdevice = NULL;
static hailo_hef hef[HEF_COUNT] = {NULL};
static hailo_configure_params_t config_params = {0};
static hailo_configured_network_group network_groups[HEF_COUNT] = {NULL};
static size_t network_groups_size = 1;
static hailo_vstream_info_t output_vstreams_info[HEF_COUNT][MAX_EDGE_LAYERS] = {0};
static hailo_input_vstream input_vstreams[HEF_COUNT][MAX_EDGE_LAYERS] = {NULL};
static hailo_output_vstream output_vstreams[HEF_COUNT][MAX_EDGE_LAYERS] = {NULL};
static size_t num_input_vstreams[HEF_COUNT];
static size_t num_output_vstreams[HEF_COUNT];
#define READ_AND_DEQUANTIZE(hef_idx, out_idx, type, out, size) \
do \
{ \
type buf[size]; \
hailo_status status = HAILO_UNINITIALIZED; \
status = hailo_vstream_read_raw_buffer(output_vstreams[hef_idx][out_idx], buf, size * sizeof(type)); \
assert(status == HAILO_SUCCESS); \
float scale = output_vstreams_info[hef_idx][out_idx].quant_info.qp_scale; \
float zp = output_vstreams_info[hef_idx][out_idx].quant_info.qp_zp; \
for (int i = 0; i < size; i++) \
*out++ = scale * (buf[i] - zp); \
} while (0)
void infer_personface(
unsigned char *input0,
float *pred80,
float *pred40,
float *pred20)
{
hailo_status status = HAILO_UNINITIALIZED;
/* Feed Data */
status = hailo_vstream_write_raw_buffer(input_vstreams[0][0], input0, 640 * 640 * 3);
assert(status == HAILO_SUCCESS);
status = hailo_flush_input_vstream(input_vstreams[0][0]);
assert(status == HAILO_SUCCESS);
READ_AND_DEQUANTIZE(0, 0, uint8_t, pred80, 80*80*21);
READ_AND_DEQUANTIZE(0, 1, uint8_t, pred40, 40*40*21);
READ_AND_DEQUANTIZE(0, 2, uint8_t, pred20, 20*20*21);
}
void infer_resnet50(
unsigned char *input0,
float *output0)
{
hailo_status status = HAILO_UNINITIALIZED;
/* Feed Data */
status = hailo_vstream_write_raw_buffer(input_vstreams[1][0], input0, 224 * 224 * 3);
assert(status == HAILO_SUCCESS);
status = hailo_flush_input_vstream(input_vstreams[1][0]);
assert(status == HAILO_SUCCESS);
READ_AND_DEQUANTIZE(1, 0, uint8_t, output0, 1);
}
int init()
{
hailo_status status = HAILO_UNINITIALIZED;
hailo_vdevice_params_t params = {0};
params.scheduling_algorithm = HAILO_SCHEDULING_ALGORITHM_ROUND_ROBIN;
params.device_count = 1;
status = hailo_create_vdevice(¶ms, &vdevice);
assert(status == HAILO_SUCCESS);
for (size_t hef_index = 0; hef_index < HEF_COUNT; hef_index++)
{
status = hailo_create_hef_file(&hef[hef_index], HEF_FILES[hef_index]);
assert(status == HAILO_SUCCESS);
status = hailo_init_configure_params(hef[hef_index], HAILO_STREAM_INTERFACE_PCIE, &config_params);
assert(status == HAILO_SUCCESS);
status = hailo_configure_vdevice(vdevice, hef[hef_index], &config_params, &network_groups[hef_index], &network_groups_size);
assert(status == HAILO_SUCCESS);
// Set scheduler's timeout and threshold for the first network group, in order to give priority to the second network group
/*if (0 == hef_index) {
status = hailo_set_scheduler_timeout(network_groups[hef_index], SCHEDULER_TIMEOUT_MS, NULL);
status = hailo_set_scheduler_threshold(network_groups[hef_index], SCHEDULER_THRESHOLD, NULL);
}*/
// Make sure it can hold amount of vstreams for hailo_make_input/output_vstream_params
hailo_input_vstream_params_by_name_t input_vstream_params[MAX_EDGE_LAYERS];
hailo_output_vstream_params_by_name_t output_vstream_params[MAX_EDGE_LAYERS];
size_t input_vstream_size = MAX_EDGE_LAYERS;
size_t output_vstream_size = MAX_EDGE_LAYERS;
status = hailo_make_input_vstream_params(network_groups[hef_index], true, HAILO_FORMAT_TYPE_AUTO,
input_vstream_params, &input_vstream_size);
assert(status == HAILO_SUCCESS);
num_input_vstreams[hef_index] = input_vstream_size;
status = hailo_make_output_vstream_params(network_groups[hef_index], true, HAILO_FORMAT_TYPE_AUTO,
output_vstream_params, &output_vstream_size);
assert(status == HAILO_SUCCESS);
num_output_vstreams[hef_index] = output_vstream_size;
status = hailo_create_input_vstreams(network_groups[hef_index], input_vstream_params, input_vstream_size, input_vstreams[hef_index]);
assert(status == HAILO_SUCCESS);
status = hailo_create_output_vstreams(network_groups[hef_index], output_vstream_params, output_vstream_size, output_vstreams[hef_index]);
assert(status == HAILO_SUCCESS);
for (size_t i = 0; i < output_vstream_size; i++)
{
hailo_get_output_vstream_info(output_vstreams[hef_index][i], &output_vstreams_info[hef_index][i]);
}
}
return status;
}
void destroy()
{
for (size_t hef_index = 0; hef_index < HEF_COUNT; hef_index++)
{
(void)hailo_release_output_vstreams(output_vstreams[hef_index], num_output_vstreams[hef_index]);
(void)hailo_release_input_vstreams(input_vstreams[hef_index], num_input_vstreams[hef_index]);
}
for (size_t hef_index = 0; hef_index < HEF_COUNT; hef_index++)
{
if (NULL != hef[hef_index])
{
(void)hailo_release_hef(hef[hef_index]);
}
}
(void)hailo_release_vdevice(vdevice);
}
from ctypes import cdll
import numpy as np
import time
def run_yolov5(lib, input):
t1 = time.time()
out0 = np.zeros((80, 80, 3, 7), dtype=np.float32)
out1 = np.zeros((40, 40, 3, 7), dtype=np.float32)
out2 = np.zeros((20, 20, 3, 7), dtype=np.float32)
lib.infer_personface(
input.ctypes.data,
out0.ctypes.data,
out1.ctypes.data,
out2.ctypes.data)
t2 = time.time()
return t2 - t1
def run_resnet50(lib, input):
t1 = time.time()
out = np.zeros((1), dtype=np.float32)
lib.infer_resnet50(
input.ctypes.data,
out.ctypes.data)
t2 = time.time()
return t2 - t1
lib = cdll.LoadLibrary("./libhailomodels.so")
input1 = np.zeros((640, 640, 3))
input2 = np.zeros((224, 224, 3))
lib.init()
print("====only yolo=====")
for i in range(10):
time1 = run_yolov5(lib, input1)
print("yolo {:.2f}ms".format(time1*1000))
print("====only resnet50=====")
for i in range(10):
time1 = run_resnet50(lib, input1)
print("resnet50 {:.2f}ms".format(time1*1000))
print("=====yolo + resnet50=====")
for i in range(10):
time1 = run_yolov5(lib, input1)
time2 = run_resnet50(lib, input2)
print("yolo{:.2f}ms resnet50 {:.2f}ms".format(time1*1000, time2*1000))
lib.destroy()