Hi everyone! I’m a college student who just ran LSTM and GRU models on the Hailo-8L for my graduation project.
I noticed there’s some LSTM info out there but hardly any ready-to-use code or guidance, so I put together a quick set of guidelines—I hope it helps. The rest of the post is in Korean for my own convenience, so feel free to translate or skim as needed.
And if you’re convinced your own way is the right way, then go for it! I just want fewer people to get hopelessly lost during the compile process—haha.
(Here’s hoping this post goes viral!)
LSTM이나 GRU가 컴파일 안되는 방법이랑 컴파일에 성공했는데 Hailort에 안돌아가는 이유에 대해서 자세히 적어보려고 합니다.
먼저 환경입니다.
실행 환경: wsl2, vscode, HailoRT 4.21, Hailo Dataflow Compiler(DFC) 3.31
python의 pytorch를 사용하여 모델을 .csv 파일로 학습시킨후 .pth → .onnx로 변환
docker를 사용해서 따로 만들어진 image를 사용해서 hailoRT를 운영하였음.
- raspberry-pi의 Hailo-8L을 사용했는데요 여기서는 당연히 DFC 컴파일이 안되기에 성능 좋은 PC에서 컴파일 진행 후 .hef 파일을 raspberry-pi의 Hailo-8L에 넘겨줬습니다.
시작 전에 사진 하나 보고 가시죠 이거 기억하죠? 저는 DFC 쓰면 안되는 이유가 뭘까 찾아보면서 3000번 정도 마주친 사진인데요 이 구조를 진행하면서 발생하는 문제들을 적어보겠습니다.
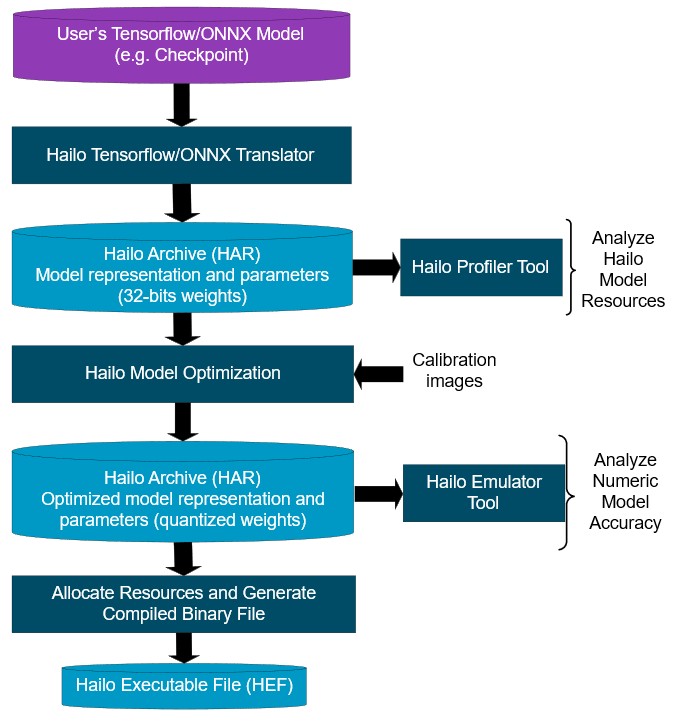
- DFC 컴파일 과정에서 element 요소가 안 맞는다
.onnx로 변환하시고 넘길 때 문제가 생긴겁니다. 맨 아래 코드 참고하시면 됩니다. 참고로 여기 코드 다 올리기엔 길이 이슈 때문에 깃헙에 해당 링크 참고하시는 걸 추천!
- DFC 과정을 거쳤는데 실행이나 version 에러가 난다.
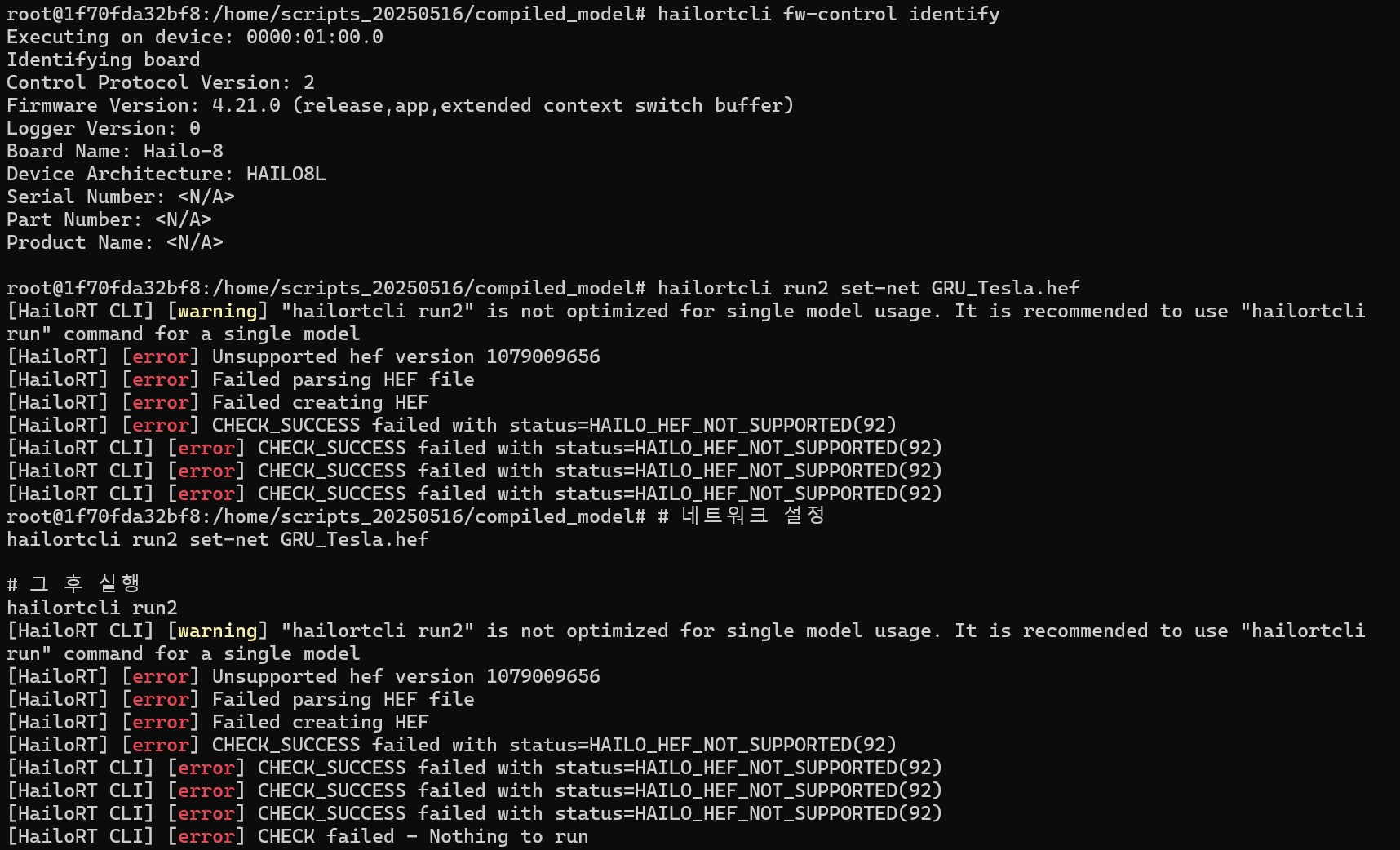
지금 상황은 HailoRT에 장치 스캔은 잘 되는데 버전이 지원 안된다는 오류 남
→ 이거는 100% 확률로 .har 파일이 not optimized 된 것임 DFC 오류 로그 보면 왜 오류 났는지 알려줄텐데 아마 높은 확률로 LSTM과 GRU가 애초에 호환이 잘 되는 모델들도 아닌데 왜 DFC에 맞지도 않는걸 넣어서 그러냐 이런식임. 컴파일에 형식이 정해져 있는데 이거는 공식 문서에서 찾아 맞는 레이어로 구성하는 걸 추천~
모델 레이어 관련 사진은 이겁니다.
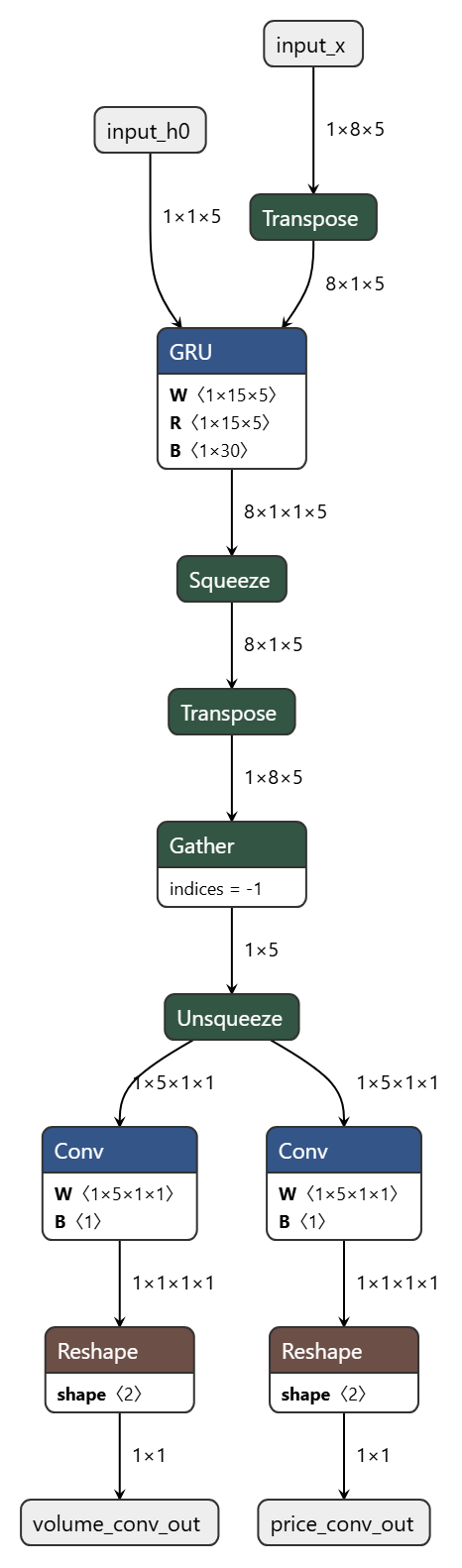
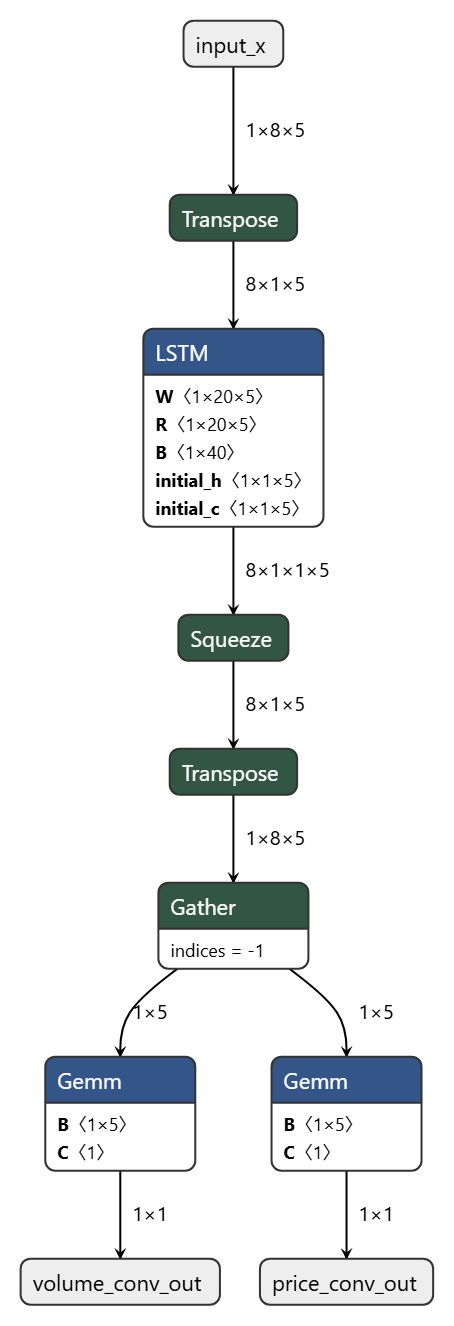
보시면 LSTM은 .onnx 파일로 변환되면서 simplifed 작업을 거쳤는데요
그럴수밖에 없는게 그냥 LSTM을 쓰면 모델 자체가 용량이 크다보니 적은 SEQ_LEN = 5에도 컴파일 시간을 3시간을 잡아먹는 기염을 토하기에 뭐 저렇게 되었습니다 ㅋㅋ
GRU는 그나마 나아서 그냥 냅 뒀는데 얘도 사이즈가 큰건 매한가지
아 그리고 저거 그대로 만들게 되면 문제가
아마 benchmark cli를 사용하면 Latency 측정하는 거에서 막힐텐데요 그거는 input이 hidden이랑 그냥 x랑 둘다 동시에 들어가야 하는데 HailoRT 지원은 하나의 input에 관한 benchmark만 지원하기에 Latency 측정은 따로 하셔야 될 겁니다 ㅠ (그래도 HailoRT 공식 문서 찾으면서 python 함수 찾으면 지연량 측정 가능!, 일단 전 성공함 ㅋㅋ)
- 기타 다른 예상가는 문제
HailoRT 에러가 계속 나요
→ docker안이나, 바깥에서 scan 부터 해보고 둘다 안되면 바깥에 라즈베리 파이랑 연결부터 하고 이후 사용권한 docker안에 운영체제에 넘겨주셈
HailoRT 연결은 했는데 측정은 어캐 하셨나요?
→ 저는 HailoRT Monitor를 사용했습니다. 아마 도커 작동시키고 들어가셔서 매번 실험하실때마다 환경변수 1로 설정해주셔야 제대로 작동할 겁니다.
한가지 아쉬운건 이거 측정을 monitor로 하면 CLI 화면이 뻑이 나간다? 측정 실험 끝나고 로그를 위에 올려다볼 수 없음
돌아보니 코드를 참 이쁘게 짜 놨네요 ㅠㅠ
하나 꼭 얘기하고 떠나라 하면
굳이 LSTM, GRU, 시계열 데이터를 NPU로 해야할 필요가 있을까요..? 하드웨어적으로 pipeline 한계가 있는거 같아요 ㅎ
그래도 프로젝트를 끝까지 진행한 입장으로써 이건 시도해본 사람이 거의 없어 데이터적으로 의미가 있다고 생각합니다. 값도 싸고 크기도 작은데 이정도 속도까지?(고성능 GPU보다 빠르진 않지만) 가성비로 굿입니다.
아래는 convert_to_onnx.py이고 여기서 여러분이 막히신 DFC 파트 잘 해결 나셨음 좋겠습니다. 정 이해가 안가시면 맨 아래 깃헙 찾아보시는걸 추천드려요 ㅎㅎ 화이팅입니다!
import os
import onnx
import torch
import torch.nn as nn
from onnxsim import simplify
from train_gru import GRUModel
from train_lstm import LSTMModel, CustomLSTM
from train_bilstm import BiLSTMModel
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
MODEL_ROOT = "./models"
ONNX_ROOT = "./onnx_models"
TICKERS = ["KOSPI", "Apple", "NASDAQ", "Tesla", "Samsung"]
TICKERS = ["Apple"]
SEQ_LEN_GRU = 8
SEQ_LEN_LSTM = 8
SEQ_LEN_BiLSTM = 8
INPUT_SIZE = 5
INPUT_SIZE_GRU = 5
INPUT_SIZE_LSTM = 5
INPUT_SIZE_BiLSTM = 5
HIDDEN_SIZE = 5 # 히든 유닛 수, Hailo에서 지원하는 크기(in_channels=out_channels)
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
# gru 모델을 torchscript로 변환하고 onnx로 변환
def export_onnx_gru(model, model_name, output_dir, input_tensor, input_names, output_names):
"""모델을 ONNX 형식으로 변환하고 Simplifier 적용"""
os.makedirs(output_dir, exist_ok=True)
onnx_path = os.path.join(output_dir, f"{model_name}.onnx")
try:
# # ONNX Export
torch.onnx.export(
model,
input_tensor,
onnx_path,
input_names=input_names,
output_names=output_names,
opset_version=11,
export_params=True
)
print(f"✅ ONNX model exported: {onnx_path}")
# # ONNX Simplifier 적용
try:
model_onnx = onnx.load(onnx_path)
model_simp, check = simplify(model_onnx)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, onnx_path)
print(f"✅ ONNX model simplified: {onnx_path}")
except Exception as e:
print(f"❌ Simplification failed: {e}")
print_onnx_node_names(onnx_path)
find_conv_layers(onnx_path)
print_onnx_graph_info(onnx_path)
except Exception as e:
print(f"❌ ONNX export failed: {e}")
# lstm 모델을 torchscript로 변환하고 onnx로 변환
def export_lstm_to_onnx(model, dummy_input, export_path, input_names, output_names):
model.eval()
torch.onnx.export(
model,
dummy_input,
export_path,
export_params=True, # Store the trained parameter weights inside the model file
opset_version=12, # Use opset 12 or higher
do_constant_folding=True, # Optimize constant folding
input_names=input_names,
output_names=output_names,
# Avoid dynamic_axes for sequence length if possible
# dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}
)
print(f"Exported LSTM model to {export_path}")
# semi final version
def export_onnx(model, model_name, output_dir, input_tensor, input_names, output_names):
"""모델을 ONNX 형식으로 변환"""
os.makedirs(output_dir, exist_ok=True)
onnx_path = os.path.join(output_dir, f"{model_name}.onnx")
try:
# Only set batch dimension as dynamic for input_x and outputs
torch.onnx.export(
model,
input_tensor,
onnx_path,
input_names=input_names,
output_names=output_names,
opset_version=11, # Use opset 11 for LSTM compatibility
dynamic_axes={
input_names[0]: {0: "batch_size"}, # input_x
output_names[0]: {0: "batch_size"},
output_names[1]: {0: "batch_size"},
},
export_params=True,
do_constant_folding=True,
use_external_data_format=False
)
print(f"✅ ONNX model exported: {onnx_path}")
# # ONNX Simplifier 적용
try:
model_onnx = onnx.load(onnx_path)
model_simp, check = simplify(model_onnx)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, onnx_path)
print(f"✅ ONNX model simplified: {onnx_path}")
except Exception as e:
print(f"❌ Simplification failed: {e}")
# print_onnx_node_names(onnx_path)
# find_conv_layers(onnx_path)
print_onnx_graph_info(onnx_path)
except Exception as e:
print(f"❌ ONNX export failed: {e}")
# Create a simple MLP model that can be used for exporting instead of LSTM/BiLSTM
class SimplifiedModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimplifiedModel, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(input_size * SEQ_LEN_LSTM, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x shape is [batch_size, seq_len, input_size]
batch_size = x.size(0)
x = self.flatten(x) # [batch_size, seq_len*input_size]
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
# Split output into two parts for price and volume
price_out = x[:, :x.size(1)//2]
volume_out = x[:, x.size(1)//2:]
return price_out, volume_out
class LSTMModel(nn.Module):
def __init__(self, input_size=5, hidden_size=5, num_layers=1, output_size=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True
)
# Hailo에서 Linear의 in_features=hidden_size, out_features=output_size 권장
self.fc_price = nn.Linear(hidden_size, output_size)
self.fc_volume = nn.Linear(hidden_size, output_size)
def forward(self, x, h0=None, c0=None):
# x: [batch, seq_len, input_size]
batch_size = x.size(0)
device = x.device
if h0 is None:
h0 = torch.zeros(self.lstm.num_layers, batch_size, self.lstm.hidden_size, device=device)
if c0 is None:
c0 = torch.zeros(self.lstm.num_layers, batch_size, self.lstm.hidden_size, device=device)
out, _ = self.lstm(x, (h0, c0)) # out: [batch, seq_len, hidden_size]
last_out = out[:, -1, :] # [batch, hidden_size]
price = self.fc_price(last_out) # [batch, output_size]
volume = self.fc_volume(last_out)
return price, volume
class BiLSTMModel(nn.Module):
def __init__(self, input_size=5, hidden_size=5, num_layers=1, output_size=1):
super(BiLSTMModel, self).__init__()
self.bilstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=True
)
# Bidirectional이므로 hidden_size*2
self.fc_price = nn.Linear(hidden_size * 2, output_size)
self.fc_volume = nn.Linear(hidden_size * 2, output_size)
def forward(self, x, h0=None, c0=None):
# x: [batch, seq_len, input_size]
batch_size = x.size(0)
num_directions = 2
device = x.device
if h0 is None:
h0 = torch.zeros(self.bilstm.num_layers * num_directions, batch_size, self.bilstm.hidden_size, device=device)
if c0 is None:
c0 = torch.zeros(self.bilstm.num_layers * num_directions, batch_size, self.bilstm.hidden_size, device=device)
out, _ = self.bilstm(x, (h0, c0)) # out: [batch, seq_len, hidden_size*2]
last_out = out[:, -1, :] # [batch, hidden_size*2]
price = self.fc_price(last_out) # [batch, output_size]
volume = self.fc_volume(last_out)
return price, volume
def process_model_org(model_class, model_dir, output_dir, input_tensor, input_names, output_names):
"""디렉터리 내의 모든 모델(.pth)을 ONNX로 변환"""
model_files = [f for f in os.listdir(model_dir) if f.endswith('.pth')]
for model_file in model_files:
model_path = os.path.join(model_dir, model_file)
model_name = os.path.splitext(model_file)[0]
# 모델 초기화 및 가중치 로드 - 각 모델 클래스에 맞게 초기화
if model_class.__name__ == "GRUModel":
model = model_class().to(DEVICE) # GRUModel has its own initialization
elif model_class.__name__ == "LSTMModel":
model = model_class(INPUT_SIZE_LSTM, 5, 1, 1).to(DEVICE)
elif model_class.__name__ == "CustomLSTM":
model = model_class(INPUT_SIZE_LSTM, 5, SEQ_LEN_LSTM).to(DEVICE)
elif model_class.__name__ == "BiLSTMModel":
model = model_class().to(DEVICE) # BiLSTMModel has its own initialization
else:
raise ValueError(f"Unsupported model class: {model_class.__name__}")
# Load state dict with strict=False to handle key mismatches
state_dict = torch.load(model_path, map_location=DEVICE)
model.load_state_dict(state_dict, strict=False)
model.eval()
print(f"=== Exporting {model_name} ===")
if model_class.__name__ == "GRUModel":
print("---- GRUModel ----")
export_onnx_gru(model, model_name, output_dir, input_tensor, input_names, output_names)
elif model_class.__name__ == "LSTMModel":
# LSTMModel의 forward는 (x, h0, c0) 받음
# Ensure only (x, h0, c0) are passed as input_tensor
export_onnx(model, model_name, output_dir, input_tensor, input_names, output_names)
else:
export_onnx(model, model_name, output_dir, input_tensor, input_names, output_names)
def process_model(model_class, model_dir, output_dir, input_tensor, input_names, output_names):
"""TICKERS에 해당하는 모델(.pth)만 ONNX로 변환"""
model_files = [f for f in os.listdir(model_dir) if f.endswith('.pth')]
for ticker in TICKERS:
# ticker 이름이 파일명에 포함된 모델만 변환
matched_files = [f for f in model_files if ticker in f]
for model_file in matched_files:
model_path = os.path.join(model_dir, model_file)
model_name = os.path.splitext(model_file)[0]
# 모델 초기화 및 가중치 로드 - 각 모델 클래스에 맞게 초기화
if model_class.__name__ == "GRUModel":
model = model_class().to(DEVICE)
elif model_class.__name__ == "LSTMModel":
model = model_class(INPUT_SIZE_LSTM, 5, 1, 1).to(DEVICE)
elif model_class.__name__ == "CustomLSTM":
model = model_class(INPUT_SIZE_LSTM, 5, SEQ_LEN_LSTM).to(DEVICE)
elif model_class.__name__ == "BiLSTMModel":
model = model_class().to(DEVICE)
else:
raise ValueError(f"Unsupported model class: {model_class.__name__}")
state_dict = torch.load(model_path, map_location=DEVICE)
model.load_state_dict(state_dict, strict=False)
model.eval()
print(f"=== Exporting {model_name} ===")
if model_class.__name__ == "GRUModel":
print("---- GRUModel ----")
export_onnx_gru(model, model_name, output_dir, input_tensor, input_names, output_names)
elif model_class.__name__ == "LSTMModel":
export_onnx(model, model_name, output_dir, input_tensor, input_names, output_names)
else:
export_onnx(model, model_name, output_dir, input_tensor, input_names, output_names)
def print_onnx_node_names(onnx_path):
model = onnx.load(onnx_path)
print("=== Node Names in ONNX Model ===")
for node in model.graph.node:
print(node.name)
def find_conv_layers(onnx_path):
model = onnx.load(onnx_path)
print("=== Conv Layers in ONNX Model ===")
for node in model.graph.node:
if "Conv" in node.op_type:
print(node.name)
# The model is represented as a protobuf structure and it can be accessed
# using the standard python-for-protobuf methods
def print_onnx_graph_info(onnx_path):
model = onnx.load(onnx_path)
# iterate through inputs of the graph
for input in model.graph.input:
print (input.name, end=": ")
# get type of input tensor
tensor_type = input.type.tensor_type
# check if it has a shape:
if (tensor_type.HasField("shape")):
# iterate through dimensions of the shape:
for d in tensor_type.shape.dim:
# the dimension may have a definite (integer) value or a symbolic identifier or neither:
if (d.HasField("dim_value")):
print (d.dim_value, end=", ") # known dimension
elif (d.HasField("dim_param")):
print (d.dim_param, end=", ") # unknown dimension with symbolic name
else:
print ("?", end=", ") # unknown dimension with no name
else:
print ("unknown rank", end="")
print()
def convert_gru_to_onnx():
"""GRU 모델을 ONNX로 변환"""
# GRU 모델 변환
gru_dir = os.path.join(MODEL_ROOT, "GRU")
gru_output_dir = os.path.join(ONNX_ROOT, "GRU")
if (os.path.exists(gru_dir)):
# GRU의 입력 텐서 (batch_size=1, seq_len=32, input_size=5)
input_x = torch.randn(1, SEQ_LEN_GRU, INPUT_SIZE_GRU).to(DEVICE)
h0 = torch.zeros(1, 1, HIDDEN_SIZE).to(DEVICE) # (num_layers, batch_size, hidden_size=5)
input_tensor = (input_x, h0) # GRU의 입력은 (x, h0) 튜플
process_model(
GRUModel, gru_dir, gru_output_dir,
input_tensor,
["input_x", "input_h0"],
["price_conv_out", "volume_conv_out"])
def convert_lstm_to_onnx():
"""LSTM 모델을 ONNX로 변환"""
# LSTM 모델들 변환
lstm_dir = os.path.join(MODEL_ROOT, "LSTM")
lstm_output_dir = os.path.join(ONNX_ROOT, "LSTM")
if os.path.exists(lstm_dir):
# For LSTM, we'll use a simplified model that Hailo can handle
# Create a simplified model for LSTM inference
simplified_model = SimplifiedModel(INPUT_SIZE_LSTM, 64, 10).to(DEVICE)
# LSTM의 입력 텐서 (batch_size=1, seq_len=32, input_size=5)
input_x = torch.randn(1, SEQ_LEN_LSTM, INPUT_SIZE_LSTM).to(DEVICE)
# Export simplified model with just input_x
process_model_files = [f for f in os.listdir(lstm_dir) if f.endswith('.pth')]
for model_file in process_model_files:
model_name = os.path.splitext(model_file)[0]
onnx_path = os.path.join(lstm_output_dir, f"{model_name}.onnx")
os.makedirs(lstm_output_dir, exist_ok=True)
# Export using simple model with only one input tensor
torch.onnx.export(
# simplified_model,
LSTMModel(INPUT_SIZE_LSTM, 5, 1, 1).to(DEVICE),
input_x, # Single input tensor
onnx_path,
input_names=["input_x"],
output_names=["price_conv_out", "volume_conv_out"],
opset_version=11,
export_params=True,
do_constant_folding=True
)
print(f"✅ Simplified ONNX model exported: {onnx_path}")
# Apply ONNX Simplifier
try:
model_onnx = onnx.load(onnx_path)
model_simp, check = simplify(model_onnx)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, onnx_path)
print(f"✅ ONNX model optimized: {onnx_path}")
except Exception as e:
print(f"❌ Simplification failed: {e}")
print_onnx_graph_info(onnx_path)
def convert_bilstm_to_onnx():
"""BiLSTM 모델을 ONNX로 변환"""
# BiLSTM 모델들 변환
bilstm_dir = os.path.join(MODEL_ROOT, "BiLSTM")
bilstm_output_dir = os.path.join(ONNX_ROOT, "BiLSTM")
if os.path.exists(bilstm_dir):
# For BiLSTM, also use a simplified model that Hailo can handle
# Create a simplified model for BiLSTM inference (slightly larger than LSTM one)
simplified_model = SimplifiedModel(INPUT_SIZE_BiLSTM, 128, 10).to(DEVICE)
# BiLSTM의 입력 텐서 (batch_size=1, seq_len=32, input_size=5)
input_x = torch.randn(1, SEQ_LEN_BiLSTM, INPUT_SIZE_BiLSTM).to(DEVICE)
# Export simplified model with just input_x
process_model_files = [f for f in os.listdir(bilstm_dir) if f.endswith('.pth')]
for model_file in process_model_files:
model_name = os.path.splitext(model_file)[0]
onnx_path = os.path.join(bilstm_output_dir, f"{model_name}.onnx")
os.makedirs(bilstm_output_dir, exist_ok=True)
# Export using simple model with only one input tensor
torch.onnx.export(
# simplified_model,
BiLSTMModel(INPUT_SIZE_BiLSTM, 5, 1, 1).to(DEVICE),
input_x, # Single input tensor
onnx_path,
input_names=["input_x"],
output_names=["price_conv_out", "volume_conv_out"],
opset_version=11,
export_params=True,
do_constant_folding=True
)
print(f"✅ Simplified ONNX model exported for BiLSTM: {onnx_path}")
# Apply ONNX Simplifier
try:
model_onnx = onnx.load(onnx_path)
model_simp, check = simplify(model_onnx)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, onnx_path)
print(f"✅ ONNX model optimized: {onnx_path}")
except Exception as e:
print(f"❌ Simplification failed: {e}")
print_onnx_graph_info(onnx_path)
def main():
os.makedirs(ONNX_ROOT, exist_ok=True)
# GRU 모델 변환
convert_gru_to_onnx()
convert_lstm_to_onnx()
convert_bilstm_to_onnx()
# 모든 모델을 ONNX로 변환 완료
print("모든 모델을 ONNX로 변환 완료!")
if __name__ == "__main__":
main()```
code for github: https://github.com/samuel426/CSE40500/tree/main/project2/scripts
search train_LSTM.py & convert_to_onnx.py