while using : yolo_stream_inference.py I am facing an error:
"2024-06-20 18:09:33.161493: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-06-20 18:09:33.896242: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
net_out (80, 80, 85)
Traceback (most recent call last):
File “./yolox_stream_inference.py”, line 87, in
hailo_preds = yolox_post_proc.yolo_postprocessing(endnodes)
File “/local/workspace/hailo_model_zoo/hailo_model_zoo/core/postprocessing/detection/yolo.py”, line 123, in yolo_postprocessing
detection_boxes, detection_scores = tf.numpy_function(self.yolo_postprocess_numpy,
File “/local/workspace/hailo_virtualenv/lib/python3.8/site-packages/tensorflow/python/util/traceback_utils.py”, line 153, in error_handler
raise e.with_traceback(filtered_tb) from None
File “/local/workspace/hailo_model_zoo/hailo_model_zoo/core/postprocessing/detection/yolo.py”, line 189, in yolo_postprocess_numpy
pred = net_out.transpose((0, 3, 1, 2)) # now dims are: [N,C,H,W] as in Gluon.
ValueError: axes don’t match array
"
note: I have observed that the dimensions of net_out are not what is expected by the function althought I am following requirement.txt and not using any custom code. please resolve the error , looking forward for your reply.
Hi @prateek.s, what platform are you running on?
I am using ubuntu OS , hailoRT H8
Thanks, and the host?
Can you please be more precise “host” , The current hailo environment contributed of Hailort dependencies and the local docker host of the virtual environment provided by hailo.
x86 (e.g. Atom, i5, Xeon, …), TDA4, Rpi4, Rpi5
ok we are using x86 (i5) for this purpose
Thanks for sharing all this info, what threw me a bit off was the CUDA error. I’ve went through it, and it seems a bit outdated (we’re almost finished rebuilding all YOLO examples). In the mean time, I’ll share here a simpler version of running YOLOX, that is not dependant on the model-zoo (thus removing heavey packages like pytorch etc.)
Start by importing some relevant packages:
#!/usr/bin/env python3
import numpy as np
import wget
from hailo_platform import (HEF, VDevice, HailoStreamInterface, InferVStreams, ConfigureParams, InputVStreamParams, OutputVStreamParams, FormatType)
from PIL import Image, ImageDraw, ImageFont
import os
import random
In this case, we’re using a pre-compiled HEF for Hailo-8 from the model-zoo, and a sample image from COCO.
hef_path = 'yolox_s_leaky.hef'
input_dir = '/data/coco/images/val2017/'
if not os.path.isfile(hef_path):
wget.download(f'https://hailo-model-zoo.s3.eu-west-2.amazonaws.com/ModelZoo/Compiled/v2.11.0/hailo8/{hef_path}')
Define some supporting methods:
def get_label(class_id):
with open('/data/coco/labels.json','r') as f:
labels = eval(f.read())
return labels[str(class_id)]
def draw_detection(draw, d, c, color, scale_factor_x, scale_factor_y):
"""Draw box and label for 1 detection."""
label = get_label(c)
ymin, xmin, ymax, xmax = d
font = ImageFont.truetype('LiberationSans-Regular.ttf', size=15)
draw.rectangle([(xmin * scale_factor_x, ymin * scale_factor_y), (xmax * scale_factor_x, ymax * scale_factor_y)], outline=color, width=2)
draw.text((xmin * scale_factor_x + 4, ymin * scale_factor_y + 4), label, fill=color, font=font)
return label
def annotate_image(image, results, thr=0.45, dim=640, offset_background=True):
COLORS = np.random.randint(0, 255, size=(90, 3), dtype=np.uint8)
draw = ImageDraw.Draw(image)
oh, ow, _ = np.asarray(img).shape
rh, rw = oh/dim, ow/dim
for idx, class_detections in enumerate(results[list(infer_results.keys())[0]][0]):
if class_detections.shape[0]>0:
color = tuple(int(c) for c in COLORS[idx])
for det in class_detections:
if det[4] > thr:
if offset_background:
label = draw_detection(draw, det[0:4] * dim , idx+1, color, rw, rh)
else:
label = draw_detection(draw, det[0:4] * dim , idx, color, rw, rh)
img = Image.open(input_dir + random.choice(os.listdir(input_dir)))
resized_image = np.asarray(img.resize((640, 640)))
if len(resized_image.shape)==1:
print('Please rerun this cell to get a color image')
This is the main block for executing on the Hailo device (using pyhailort):
hef = HEF(hef_path)
with VDevice() as target:
configure_params = ConfigureParams.create_from_hef(hef, interface=HailoStreamInterface.PCIe)
network_group = target.configure(hef, configure_params)[0]
network_group_params = network_group.create_params()
input_vstream_info = hef.get_input_vstream_infos()[0]
input_vstreams_params = InputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.UINT8)
output_vstreams_params = OutputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.FLOAT32)
with InferVStreams(network_group, input_vstreams_params, output_vstreams_params) as infer_pipeline:
input_data = {input_vstream_info.name: np.expand_dims(resized_image, axis=0).astype(np.uint8)}
with network_group.activate(network_group_params):
infer_results = infer_pipeline.infer(input_data)
Finally, you can annotate the image:
annotate_image(img, infer_results)
thank you @Nadav for the help, can you please provide this code in the sequence of coocurance and for “person” class specific
and I have to run this code for mostly rtsp inputs or multistream video sources so how can I acheive that
import cv2
import numpy as np
from hailo_platform import (HEF, VDevice, HailoStreamInterface, InferVStreams, ConfigureParams,
InputVStreamParams, OutputVStreamParams, FormatType)
from PIL import Image, ImageDraw, ImageFont
import os
import random
import time
import json
# Constants
INPUT_RES_H = 640
INPUT_RES_W = 640
# Paths
hef_path = './resources/hefs/yolox_s_leaky.hef'
input_dir = './resources/video/'
label_path = 'yolox_s_labels.json'
# Load labels
with open(label_path, 'r') as f:
labels = json.load(f)
# Initialize HEF and VDevice
hef = HEF(hef_path)
with VDevice() as target:
configure_params = ConfigureParams.create_from_hef(hef, interface=HailoStreamInterface.PCIe)
network_group = target.configure(hef, configure_params)[0]
network_group_params = network_group.create_params()
input_vstream_info = hef.get_input_vstream_infos()[0]
input_vstreams_params = InputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.UINT8)
output_vstreams_params = OutputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.FLOAT32)
# Video capture initialization
source = 'camera'
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("Could not open camera")
exit()
def get_label(class_id):
return labels[str(class_id)]
def draw_detection(draw, d, c, color, scale_factor_x, scale_factor_y):
label = get_label(c)
ymin, xmin, ymax, xmax = d
font = ImageFont.load_default()
draw.rectangle([(xmin * scale_factor_x, ymin * scale_factor_y),
(xmax * scale_factor_x, ymax * scale_factor_y)], outline=color, width=2)
draw.text((xmin * scale_factor_x + 4, ymin * scale_factor_y + 4), label, fill=color, font=font)
return label
def annotate_image(image, results, detections_list, thr=0.45, dim=640):
COLORS = np.random.randint(0, 255, size=(90, 3), dtype=np.uint8)
draw = ImageDraw.Draw(image)
oh, ow = image.size
rh, rw = oh / dim, ow / dim
# Initialize boxes, classes, and scores to empty arrays
boxes = np.empty((0, 4))
classes = np.empty((0,))
scores = np.empty((0,))
# Parse the inference results
for key, detections in results.items():
if "detection_classes" in key:
classes = detections[0]
if "detection_boxes" in key:
boxes = detections[0]
if "detection_scores" in key:
scores = detections[0]
# Debug print to verify parsed data
print("Classes:", classes)
print("Boxes:", boxes)
print("Scores:", scores)
# Iterate over the boxes and draw detections
for i in range(boxes.shape[0]):
class_id = int(classes[i])
if class_id == 1 and scores[i] > thr: # Ensure only 'person' class is processed
bbox = boxes[i] * [oh, ow, oh, ow]
score = scores[i]
draw_detection(draw, bbox, class_id, tuple(COLORS[class_id]), 1, 1)
detections_list.append({
'bbox': bbox.tolist(),
'score': float(score),
'class_id': class_id
})
detections_log = []
while True:
start_time = time.time()
ret, frame = cap.read()
orig_w = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
orig_h = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
if not ret:
print("Could not read frame")
break
if source == 'video' and not cap.get(cv2.CAP_PROP_POS_FRAMES) % cap.get(cv2.CAP_PROP_FRAME_COUNT):
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
resized_img = cv2.resize(frame, (INPUT_RES_H, INPUT_RES_W), interpolation=cv2.INTER_AREA)
with InferVStreams(network_group, input_vstreams_params, output_vstreams_params) as infer_pipeline:
input_data = {input_vstream_info.name: np.expand_dims(resized_img, axis=0).astype(np.uint8)}
with network_group.activate(network_group_params):
infer_results = infer_pipeline.infer(input_data)
# Debug print to verify inference results
print("Inference Results:", infer_results)
# Convert to PIL image for annotation
img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
frame_detections = []
annotate_image(img, infer_results, frame_detections)
detections_log.append({
'frame': len(detections_log) + 1,
'detections': frame_detections
})
# Display the frame with bounding boxes
cv2.imshow('frame', cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR))
# Calculate FPS]
end_time = time.time()
fps = 1 / (end_time - start_time)
print(f"FPS: {fps:.2f}")
key = cv2.waitKey(1)
if key == ord('c'):
source = 'camera'
cap.release()
cap = cv2.VideoCapture(0)
elif key == ord('v'):
source = 'video'
cap.release()
random_mp4 = random.choice(os.listdir(input_dir))
cap = cv2.VideoCapture(os.path.join(input_dir, random_mp4))
elif key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# Save detections log to a JSON file
with open('./resources/detections_log.json', 'w') as f:
json.dump(detections_log, f, indent=4)
hi moderator, from the given provided functions we have create a script for the purpose of running person detection on hailo device , but we are not able to get bboxes , scores , classes on the frames.
Result output that we are getting :
'yolox_s_leaky/conv55': array([[[[ 1.2509106 , 0.7322404 , 0.7932604 , 0.6102003 ],
[ 1.1288706 , 1.0373405 , 1.3729507 , 0.64071035],
[ 0.15255007, 1.2204006 , 1.4034607 , 0.7322404 ],
...,
[ 1.2204006 , 0.8237704 , 1.2204006 , 0.42714024],
[ 0.3661202 , 0.7627504 , 1.1593806 , 0.30510014],
[-0.24408013, 0.6102003 , 0.8542805 , 0.1830601 ]],
[[ 1.5865208 , 1.1593806 , 0.9458105 , 1.4339707 ],
[ 1.4949908 , 1.7390709 , 1.5865208 , 1.6780509 ],
[ 0.48816025, 1.6780509 , 1.5865208 , 1.6170309 ],
...,
[ 1.0373405 , -0.12204006, 1.0983605 , 0.42714024],
[ 0.24408013, -0.09153005, 1.2509106 , 0.3966302 ],
[-0.09153005, 0.09153005, 0.67122036, 0.42714024]],
[[ 1.0983605 , 1.0068306 , 0.64071035, 1.708561 ],
[ 1.5255008 , 1.4644808 , 1.6170309 , 1.922131 ],
[ 0.7017304 , 1.5255008 , 1.7390709 , 1.9831511 ],
...,
[ 0.67122036, -0.54918027, 1.4034607 , 0.7017304 ],
[ 0.33561018, -0.48816025, 1.1288706 , 0.7627504 ],
[ 0.48816025, 0.33561018, 0.06102003, 0.48816025]],
...,
[[ 1.5560108 , -0.9458105 , 1.0983605 , 2.105191 ],
[ 0.7627504 , -0.8847905 , 1.2814207 , 2.074681 ],
[ 0.8847905 , 0.06102003, 1.7390709 , 1.7390709 ],
...,
[ 0.1830601 , -1.1593806 , 1.7390709 , 2.105191 ],
[-0.7017304 , -1.0068306 , 1.6475408 , 2.044171 ],
[-0.9763205 , 0.27459013, 1.3119307 , 1.5865208 ]],
[[ 1.4644808 , -0.7322404 , 1.0373405 , 1.6475408 ],
[ 0.7932604 , -1.1288706 , 1.2814207 , 1.830601 ],
[ 0.3661202 , -0.6102003 , 1.4949908 , 1.6475408 ],
...,
[ 0.48816025, -0.45765024, 1.5865208 , 1.5560108 ],
[-0.3661202 , 0.30510014, 1.5255008 , 1.2204006 ],
[-1.0373405 , 0.6102003 , 1.3424407 , 1.0678506 ]],
[[ 1.0373405 , 0.03051002, 0.7932604 , 0.7017304 ],
[ 0.5796903 , -0.1830601 , 1.1898906 , 0.9153005 ],
[ 0.1830601 , 0.12204006, 1.3119307 , 0.7017304 ],
...,
[ 0.54918027, -0.06102003, 1.5560108 , 0.7932604 ],
[-0.21357012, -0.09153005, 1.4949908 , 0.8237704 ],
[-0.7322404 , 0.3661202 , 1.3119307 , 0.8847905 ]]]],
dtype=float32), 'yolox_s_leaky/conv70': array([[[[0. ],
[0. ],
[0. ],
...,
[0. ],
[0. ],
[0. ]],
[[0. ],
[0. ],
[0. ],
...,
[0. ],
[0. ],
[0. ]],
[[0. ],
[0. ],
[0. ],
...,
[0. ],
[0. ],
[0. ]],
...,
[[0. ],
[0. ],
[0. ],
...,
[0.00391513],
[0.01174537],
[0.00783025]],
[[0. ],
[0. ],
[0. ],
...,
[0. ],
[0.00783025],
[0.00783025]],
[[0. ],
[0. ],
[0. ],
...,
[0. ],
[0. ],
[0. ]]]], dtype=float32), 'yolox_s_leaky/conv56': array([[[[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]],
[[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]],
[[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]],
...,
[[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]],
[[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]],
[[0.],
[0.],
[0.],
...,
[0.],
[0.],
[0.]]]], dtype=float32)}
Classes: []
Boxes: []
Scores: []
FPS: 16.05
please provide updated script so that we can test our test case videos for person detection only.
Hey @prateek.s
You can check how we draw detection in the following example : Hailo-Application-Code-Examples/runtime/python/yolox_streaming_inference/yolox_stream_report_detections.py at main · hailo-ai/Hailo-Application-Code-Examples · GitHub
Also the following is a full example running on the camera of the pc or rtsp with yolox and detection that runs with only person class and confidence of 80% or higher :
import cv2
import numpy as np
from hailo_platform import (HEF, VDevice, HailoStreamInterface, InferVStreams, ConfigureParams,
InputVStreamParams, OutputVStreamParams, FormatType)
import time
import json
# Input source selection
INPUT_SOURCE = 'camera' # Change this to 'rtsp', 'video', or 'camera'
# Constants
INPUT_RES_H = 640
INPUT_RES_W = 640
# Paths
hef_path = './resources/hefs/yolox_s_leaky.hef'
label_path = 'yolox_s_labels.json'
# Input source parameters
rtsp_url = "rtsp://your_rtsp_stream_url_here"
video_path = './resources/video/your_video_file.mp4'
camera_id = 0
# Load labels
with open(label_path, 'r') as f:
labels = json.load(f)
def nms(boxes, scores, iou_threshold):
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1) * (y2 - y1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1)
h = np.maximum(0.0, yy2 - yy1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= iou_threshold)[0]
order = order[inds + 1]
return keep
def post_process(outputs, conf_threshold=0.8, iou_threshold=0.45):
all_boxes = []
all_scores = []
all_class_ids = []
for output in outputs:
boxes = output[:, :4]
scores = output[:, 4]
class_ids = output[:, 5]
mask = scores > conf_threshold
boxes = boxes[mask]
scores = scores[mask]
class_ids = class_ids[mask]
all_boxes.append(boxes)
all_scores.append(scores)
all_class_ids.append(class_ids)
if not all_boxes: # If no detections, return empty arrays
return np.array([]), np.array([]), np.array([])
all_boxes = np.concatenate(all_boxes)
all_scores = np.concatenate(all_scores)
all_class_ids = np.concatenate(all_class_ids)
keep = nms(all_boxes, all_scores, iou_threshold)
return all_boxes[keep], all_scores[keep], all_class_ids[keep]
def draw_detection(frame, box, score, color=(0, 255, 0)):
x1, y1, x2, y2 = box
frame_height, frame_width = frame.shape[:2]
# Check if the coordinates are within the frame
if x1 < 0 or y1 < 0 or x2 > frame_width or y2 > frame_height:
print(f"Warning: Box coordinates out of frame: ({x1}, {y1}, {x2}, {y2})")
print(f"Frame dimensions: {frame_width}x{frame_height}")
x1 = max(0, min(int(x1), frame_width - 1))
y1 = max(0, min(int(y1), frame_height - 1))
x2 = max(0, min(int(x2), frame_width - 1))
y2 = max(0, min(int(y2), frame_height - 1))
# Check if the box has a valid size
if x2 <= x1 or y2 <= y1:
print(f"Warning: Invalid box size: ({x1}, {y1}, {x2}, {y2})")
return frame
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
label = f"Person {score:.2f}"
cv2.putText(frame, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)
return frame
# Initialize HEF and VDevice
hef = HEF(hef_path)
with VDevice() as target:
configure_params = ConfigureParams.create_from_hef(hef, interface=HailoStreamInterface.PCIe)
network_group = target.configure(hef, configure_params)[0]
network_group_params = network_group.create_params()
input_vstream_info = hef.get_input_vstream_infos()[0]
output_vstream_info = hef.get_output_vstream_infos()[0]
input_vstreams_params = InputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.FLOAT32)
output_vstreams_params = OutputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.FLOAT32)
# Set up video capture based on input source
if INPUT_SOURCE == 'rtsp':
cap = cv2.VideoCapture(rtsp_url)
source_name = "RTSP Stream"
elif INPUT_SOURCE == 'video':
cap = cv2.VideoCapture(video_path)
source_name = "Video File"
elif INPUT_SOURCE == 'camera':
cap = cv2.VideoCapture(camera_id)
source_name = "Camera"
else:
raise ValueError("Invalid INPUT_SOURCE. Choose 'rtsp', 'video', or 'camera'.")
if not cap.isOpened():
print(f"Could not open {source_name}")
exit()
while True:
start_time = time.time()
ret, frame = cap.read()
if not ret:
print(f"End of {source_name}")
break
original_height, original_width = frame.shape[:2]
resized_img = cv2.resize(frame, (INPUT_RES_W, INPUT_RES_H), interpolation=cv2.INTER_AREA)
with InferVStreams(network_group, input_vstreams_params, output_vstreams_params) as infer_pipeline:
input_data = {input_vstream_info.name: np.expand_dims(resized_img, axis=0).astype(np.float32)}
with network_group.activate(network_group_params):
infer_results = infer_pipeline.infer(input_data)
# Prepare outputs
outputs = [
np.concatenate([
infer_results['yolox_s_leaky/conv55'], # reg
infer_results['yolox_s_leaky/conv56'], # obj
infer_results['yolox_s_leaky/conv54'] # cls
], axis=-1).reshape(-1, 85),
np.concatenate([
infer_results['yolox_s_leaky/conv69'], # reg
infer_results['yolox_s_leaky/conv70'], # obj
infer_results['yolox_s_leaky/conv68'] # cls
], axis=-1).reshape(-1, 85),
np.concatenate([
infer_results['yolox_s_leaky/conv82'], # reg
infer_results['yolox_s_leaky/conv83'], # obj
infer_results['yolox_s_leaky/conv81'] # cls
], axis=-1).reshape(-1, 85)
]
# Post-process with 80% confidence threshold
boxes, scores, class_ids = post_process(outputs, conf_threshold=0.8)
print(f"Number of detections: {len(boxes)}")
# Draw detections (only persons) once
for box, score, class_id in zip(boxes, scores, class_ids):
if int(class_id) == 0: # Assuming 0 is the person class
# Convert normalized coordinates to pixel coordinates
x1, y1, x2, y2 = box
x1 = int(x1 * original_width)
y1 = int(y1 * original_height)
x2 = int(x2 * original_width)
y2 = int(y2 * original_height)
print(f"Original box: {box}")
print(f"Scaled box: ({x1}, {y1}, {x2}, {y2})")
print(f"Frame dimensions: {original_width}x{original_height}")
frame = draw_detection(frame, (x1, y1, x2, y2), score)
# Display the frame with bounding boxes
cv2.imshow(source_name, frame)
# Calculate and display FPS
end_time = time.time()
fps = 1 / (end_time - start_time)
cv2.putText(frame, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Check for 'q' or 'c' key press
key = cv2.waitKey(1) & 0xFF
if key == ord('q') or key == ord('c'):
break
cap.release()
cv2.destroyAllWindows()
print("Program stopped.")
How can the same on a rpi5, using hailos on a custom yolov8.
thanks you @omria for the solution. I have tested the script and the it is working fine but the problem still arose while ploting the bounding boxing on frames we indeed get original boxes coordinates but also a warning i.e.
Frame dimensions: 1138x640
Warning: Invalid box size: (1137, 407, 1137, 639)
Original box: [0. 0.5438248 1.0099603 2.4472115]
Scaled box: (0, 348, 1149, 1566)
Frame dimensions: 1138x640
Warning: Box coordinates out of frame: (0, 348, 1149, 1566)
so how can we resolve it ?
Warning: Box coordinates out of frame: (122, 458, 775, 1193)
Frame dimensions: 640x480
Original box: [2.4222827 0.19123286 1.9123285 1.8804563 ]
Scaled box: (1550, 91, 1223, 902)
Frame dimensions: 640x480
Warning: Box coordinates out of frame: (1550, 91, 1223, 902)
Frame dimensions: 640x480
Warning: Invalid box size: (639, 91, 639, 479)
this was one another resolution source that I tested the script on .
This seems like mismatch with the frame size i used to yours
Will update the code to use any frame
First of all i would encourage you to look at this example that uses the yolox :
This is the updated code for the example i provided before :
import cv2
import numpy as np
from hailo_platform import (HEF, VDevice, HailoStreamInterface, InferVStreams, ConfigureParams,
InputVStreamParams, OutputVStreamParams, FormatType)
import time
import json
# Input source selection
INPUT_SOURCE = 'camera' # Change this to 'rtsp', 'video', or 'camera'
# Constants
INPUT_RES_H = 640
INPUT_RES_W = 640
# Paths
hef_path = './resources/hefs/yolox_s_leaky.hef'
label_path = 'yolox_s_labels.json'
# Input source parameters
rtsp_url = "rtsp://your_rtsp_stream_url_here"
video_path = './resources/video/your_video_file.mp4'
camera_id = 0
# Load labels
with open(label_path, 'r') as f:
labels = json.load(f)
def nms(boxes, scores, iou_threshold):
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1) * (y2 - y1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1)
h = np.maximum(0.0, yy2 - yy1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter + 1e-10)
inds = np.where(ovr <= iou_threshold)[0]
order = order[inds + 1]
return keep
def post_process(outputs, conf_threshold=0.3, iou_threshold=0.45, input_shape=(640, 640)):
all_boxes = []
all_scores = []
all_class_ids = []
for output in outputs:
boxes = output[:, :4]
scores = output[:, 4]
class_ids = output[:, 5]
mask = scores > conf_threshold
boxes = boxes[mask]
scores = scores[mask]
class_ids = class_ids[mask]
# Ensure boxes are within [0, 1] range
boxes = np.clip(boxes, 0, 1)
all_boxes.append(boxes)
all_scores.append(scores)
all_class_ids.append(class_ids)
if not all_boxes: # If no detections, return empty arrays
return np.array([]), np.array([]), np.array([])
all_boxes = np.concatenate(all_boxes)
all_scores = np.concatenate(all_scores)
all_class_ids = np.concatenate(all_class_ids)
# Filter out boxes with zero width or height
valid_mask = (all_boxes[:, 2] > all_boxes[:, 0]) & (all_boxes[:, 3] > all_boxes[:, 1])
all_boxes = all_boxes[valid_mask]
all_scores = all_scores[valid_mask]
all_class_ids = all_class_ids[valid_mask]
keep = nms(all_boxes, all_scores, iou_threshold)
return all_boxes[keep], all_scores[keep], all_class_ids[keep]
def draw_detection(frame, box, score, color=(0, 255, 0)):
frame_height, frame_width = frame.shape[:2]
x1, y1, x2, y2 = box
x1 = int(x1 * frame_width)
y1 = int(y1 * frame_height)
x2 = int(x2 * frame_width)
y2 = int(y2 * frame_height)
# Ensure coordinates are within frame boundaries
x1 = max(0, min(x1, frame_width - 1))
y1 = max(0, min(y1, frame_height - 1))
x2 = max(0, min(x2, frame_width - 1))
y2 = max(0, min(y2, frame_height - 1))
# Check if the box has a valid size
if x2 <= x1 or y2 <= y1:
return frame
cv2.rectangle(frame, (x1, y1), (x2, y2), color, 2)
label = f"Person {score:.2f}"
cv2.putText(frame, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)
return frame
def process_frame(frame, network_group, input_vstreams_params, output_vstreams_params, network_group_params, input_vstream_info):
original_height, original_width = frame.shape[:2]
resized_img = cv2.resize(frame, (INPUT_RES_W, INPUT_RES_H), interpolation=cv2.INTER_AREA)
with InferVStreams(network_group, input_vstreams_params, output_vstreams_params) as infer_pipeline:
input_data = {input_vstream_info.name: np.expand_dims(resized_img, axis=0).astype(np.float32)}
with network_group.activate(network_group_params):
infer_results = infer_pipeline.infer(input_data)
# Prepare outputs
outputs = [
np.concatenate([
infer_results['yolox_s_leaky/conv55'], # reg
infer_results['yolox_s_leaky/conv56'], # obj
infer_results['yolox_s_leaky/conv54'] # cls
], axis=-1).reshape(-1, 85),
np.concatenate([
infer_results['yolox_s_leaky/conv69'], # reg
infer_results['yolox_s_leaky/conv70'], # obj
infer_results['yolox_s_leaky/conv68'] # cls
], axis=-1).reshape(-1, 85),
np.concatenate([
infer_results['yolox_s_leaky/conv82'], # reg
infer_results['yolox_s_leaky/conv83'], # obj
infer_results['yolox_s_leaky/conv81'] # cls
], axis=-1).reshape(-1, 85)
]
# Post-process with 30% confidence threshold
boxes, scores, class_ids = post_process(outputs, conf_threshold=0.3, input_shape=(INPUT_RES_W, INPUT_RES_H))
# Limit the number of detections to 10
max_detections = 10
if len(boxes) > max_detections:
top_indices = np.argsort(scores)[-max_detections:]
boxes = boxes[top_indices]
scores = scores[top_indices]
class_ids = class_ids[top_indices]
# Draw detections (only persons with confidence > 80%)
high_conf_detections = 0
for box, score, class_id in zip(boxes, scores, class_ids):
if int(class_id) == 0 and score > 0.8: # Assuming 0 is the person class
frame = draw_detection(frame, box, score)
high_conf_detections += 1
return frame, high_conf_detections
# Initialize HEF and VDevice
hef = HEF(hef_path)
with VDevice() as target:
configure_params = ConfigureParams.create_from_hef(hef, interface=HailoStreamInterface.PCIe)
network_group = target.configure(hef, configure_params)[0]
network_group_params = network_group.create_params()
input_vstream_info = hef.get_input_vstream_infos()[0]
output_vstream_info = hef.get_output_vstream_infos()[0]
input_vstreams_params = InputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.FLOAT32)
output_vstreams_params = OutputVStreamParams.make_from_network_group(network_group, quantized=False, format_type=FormatType.FLOAT32)
# Set up video capture based on input source
if INPUT_SOURCE == 'rtsp':
cap = cv2.VideoCapture(rtsp_url)
source_name = "RTSP Stream"
elif INPUT_SOURCE == 'video':
cap = cv2.VideoCapture(video_path)
source_name = "Video File"
elif INPUT_SOURCE == 'camera':
cap = cv2.VideoCapture(camera_id)
source_name = "Camera"
else:
raise ValueError("Invalid INPUT_SOURCE. Choose 'rtsp', 'video', or 'camera'.")
if not cap.isOpened():
print(f"Could not open {source_name}")
exit()
# Get the actual frame rate of the video source
fps = cap.get(cv2.CAP_PROP_FPS)
if fps <= 0:
fps = 30 # Default to 30 fps if unable to determine
frame_time = 1 / fps
prev_time = time.time()
fps_update_interval = 1.0 # Update FPS display every second
fps_last_update = time.time()
frame_count = 0
displayed_fps = 0
while True:
ret, frame = cap.read()
if not ret:
print(f"End of {source_name}")
break
current_time = time.time()
elapsed_time = current_time - prev_time
if elapsed_time >= frame_time:
# Process the frame
frame, num_detections = process_frame(frame, network_group, input_vstreams_params, output_vstreams_params, network_group_params, input_vstream_info)
# Add debugging print
print(f"Frame processed. High confidence detections: {num_detections}")
# Update FPS calculation
frame_count += 1
if current_time - fps_last_update >= fps_update_interval:
displayed_fps = frame_count / (current_time - fps_last_update)
fps_last_update = current_time
frame_count = 0
# Display FPS and number of detections
cv2.putText(frame, f"FPS: {displayed_fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.putText(frame, f"High Conf Detections: {num_detections}", (10, 70), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# Display the frame
cv2.imshow(source_name, frame)
prev_time = current_time
# Check for 'q' key press
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
print("Program stopped.")```Hey @shubhamprasad7777,
For C++ examples, you can check out the following repository:
Regarding Python examples, the release of the Python API support for Raspberry Pi is coming soon. We’ll make sure to update you once it’s pushed to the Hailo package in the Raspberry Pi OS.
Please let us know if you have any other questions or if there’s anything else we can assist you with.
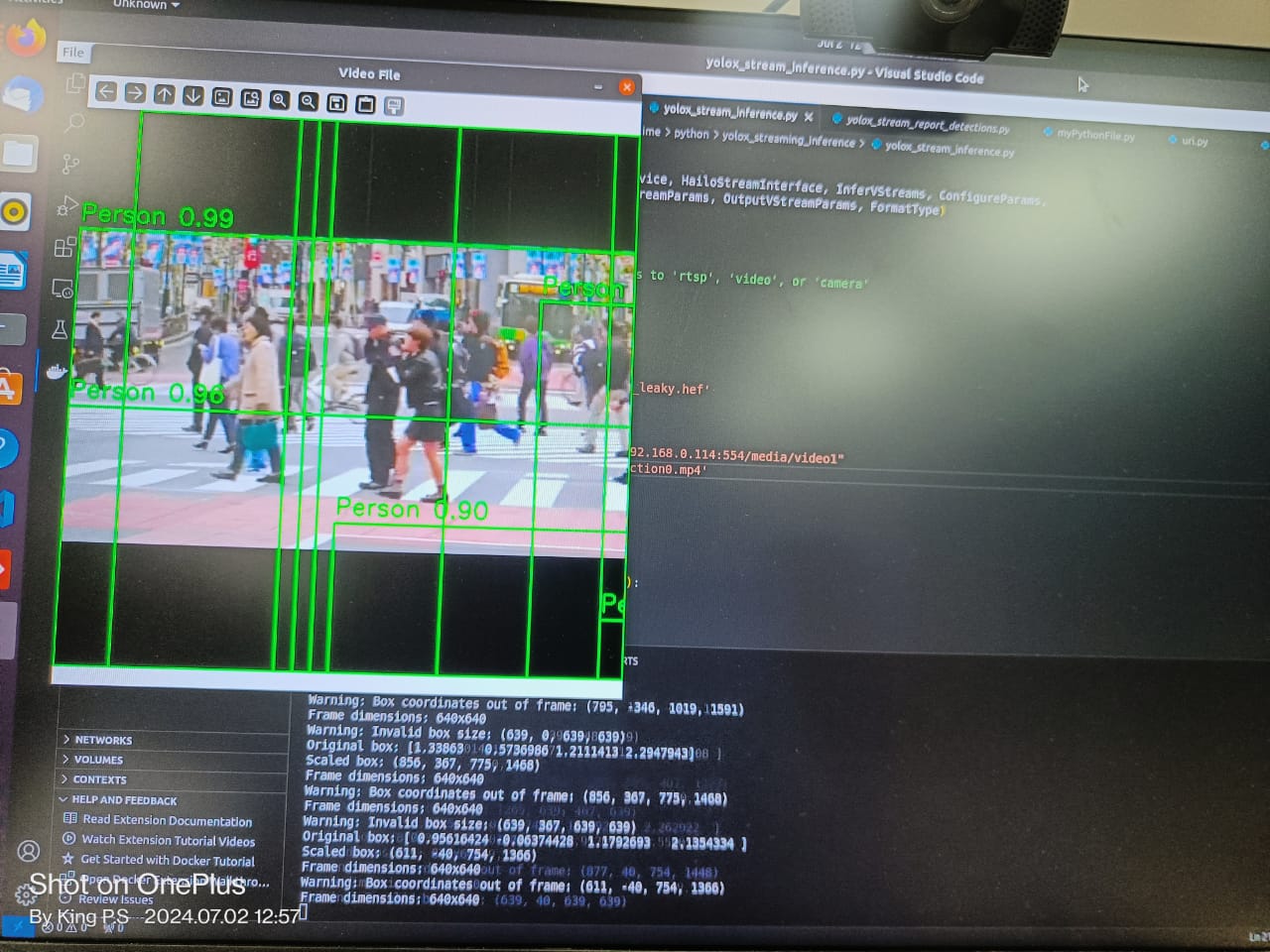
thanks @omria I have tested the above provided script but, It is providing quite same results where bounding boxes are getting out of frame. please refer to attached img and drive link to see the video
video : WhatsApp Video 2024-07-02 at 21.20.47.mp4 - Google Drive