I am trying to convert a YOLOv8m model to HEF and I am running into an issue on the Quantization-Aware Fine-Tuning step. It will run for a minute or two and then gets killed:
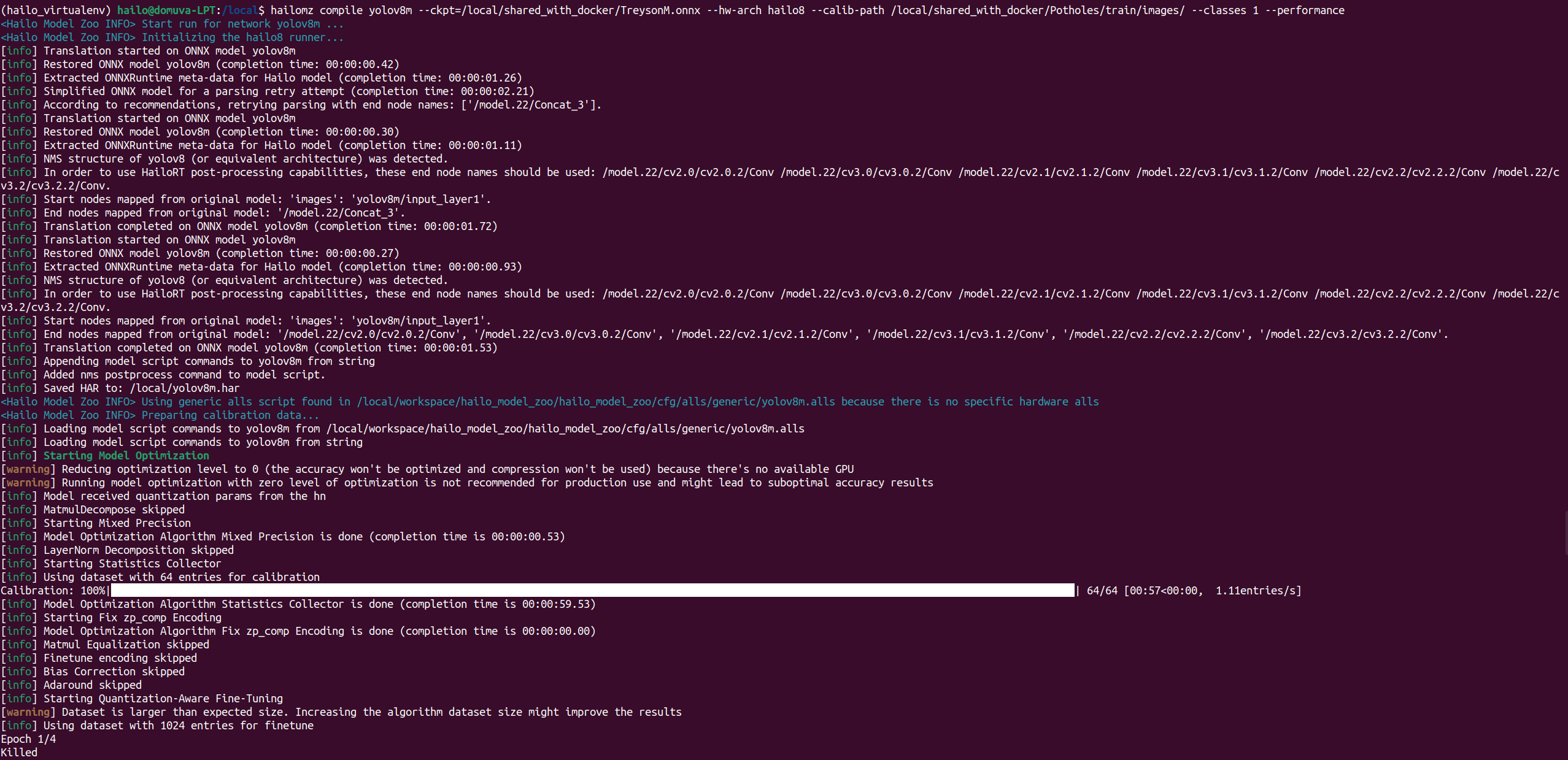
This has worked in the past with a YOLOv8n model, so I went back to check and it looks like the Quantization-Aware Fine-Tuning was skipped for the nano:
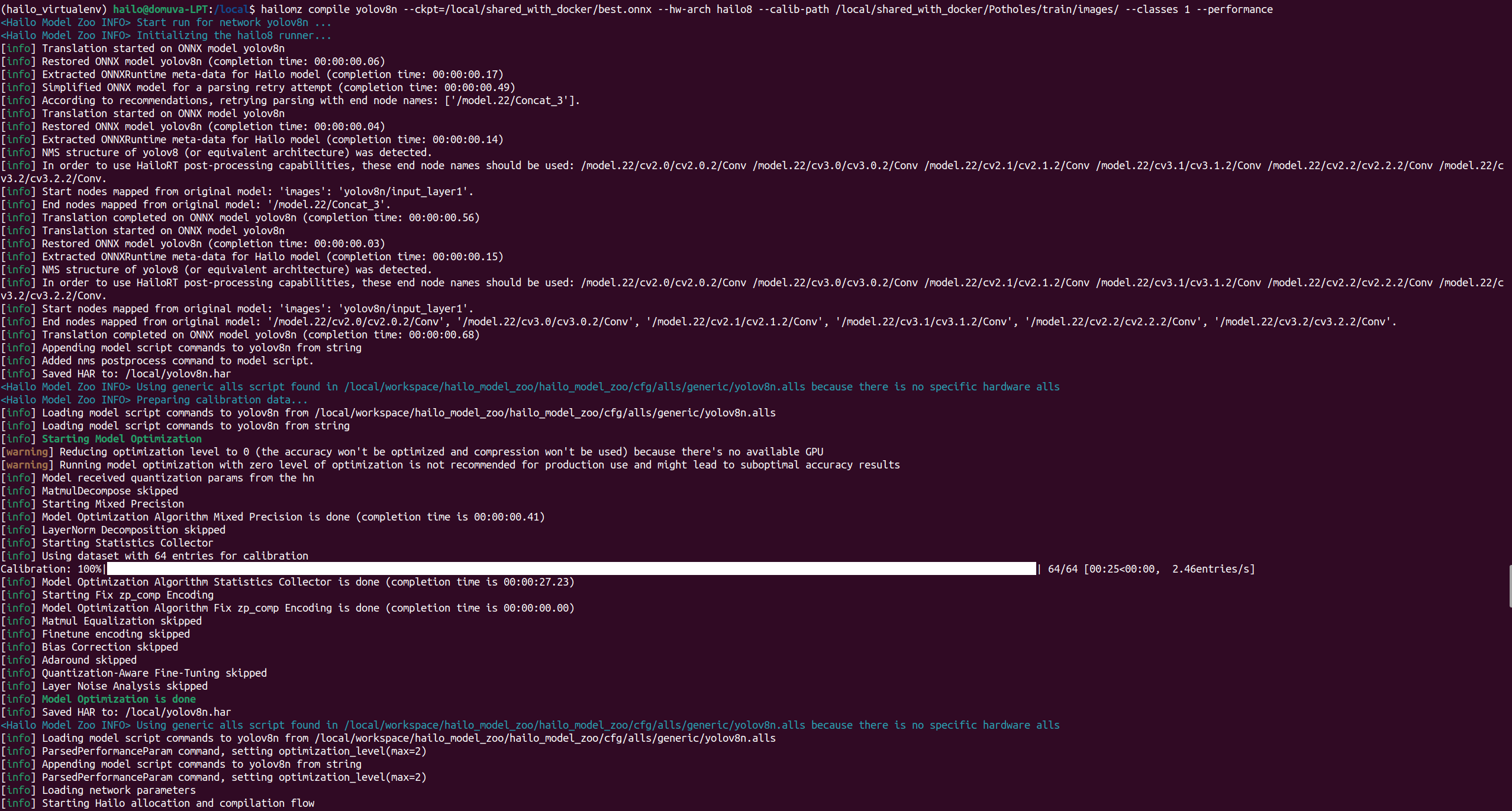
Any idea why this would be happening or how to fix it/skip it?