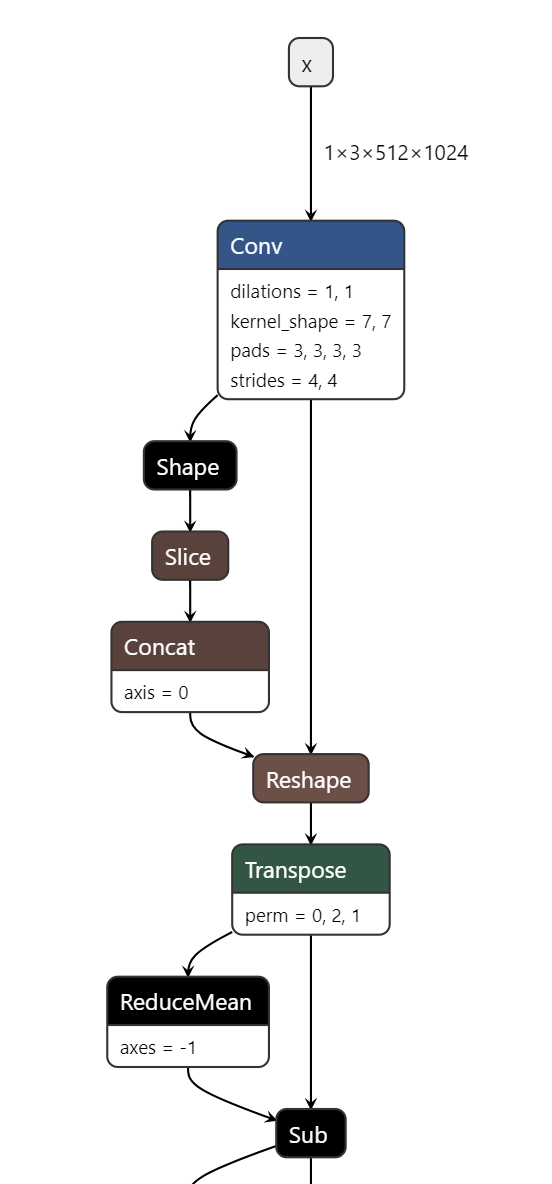
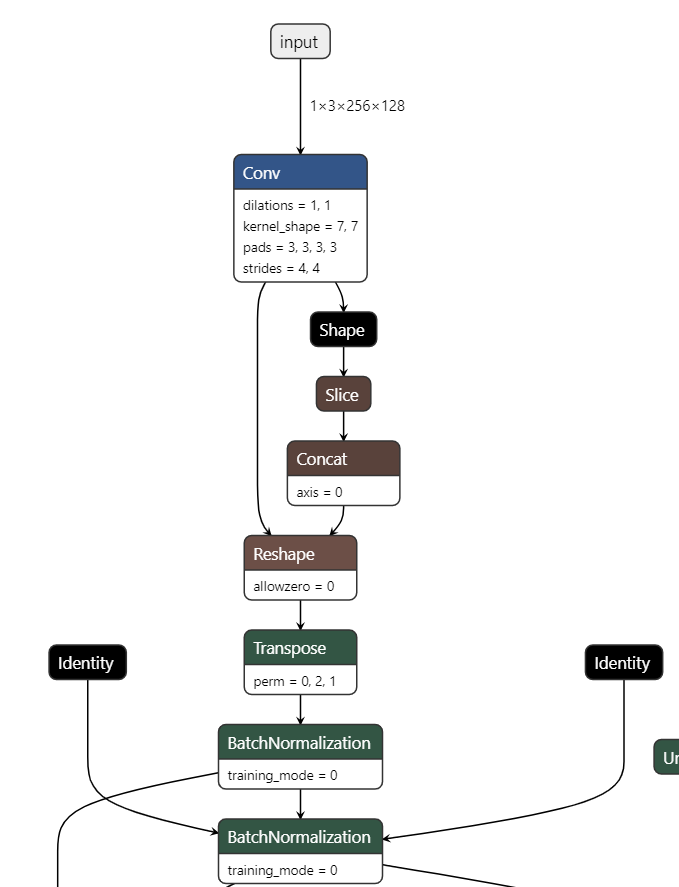
Moreover, I cannot find any BatchNormalization block in the .onnx downloadable from the model_zoo. But mainly ReduceMean blocks. So I guess some custom nn.Module was created that uses torch.mean() under the hood.
First ONNX layers in model_zoo’s model:
First ONNX layer in my custom model:
My Custom model:
# ---------------------------------------------------------------
# Copyright (c) 2021, NVIDIA Corporation. All rights reserved.
#
# This work is licensed under the NVIDIA Source Code License
# ---------------------------------------------------------------
import collections
import math
import warnings
from itertools import repeat
from typing import Optional, Tuple
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
def _trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
# Computes standard normal cumulative distribution function
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
if (mean < a - 2 * std) or (mean > b + 2 * std):
warnings.warn(
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
"The distribution of values may be incorrect.",
stacklevel=2,
)
# Values are generated by using a truncated uniform distribution and
# then using the inverse CDF for the normal distribution.
# Get upper and lower cdf values
l = norm_cdf((a - mean) / std) # noqa
u = norm_cdf((b - mean) / std)
# Uniformly fill tensor with values from [l, u], then translate to
# [2l-1, 2u-1].
tensor.uniform_(2 * l - 1, 2 * u - 1)
# Use inverse cdf transform for normal distribution to get truncated
# standard normal
tensor.erfinv_()
# Transform to proper mean, std
tensor.mul_(std * math.sqrt(2.0))
tensor.add_(mean)
# Clamp to ensure it's in the proper range
tensor.clamp_(min=a, max=b)
return tensor
def trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0):
# type: (Tensor, float, float, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \leq \text{mean} \leq b`.
NOTE: this impl is similar to the PyTorch trunc_normal_, the bounds [a, b] are
applied while sampling the normal with mean/std applied, therefore a, b args
should be adjusted to match the range of mean, std args.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
"""
with torch.no_grad():
return _trunc_normal_(tensor, mean, std, a, b)
class Mlp(nn.Module):
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(
self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0,
sr_ratio=1,
norm_layer: str = "LayerNorm",
num_patches: Optional[int] = None
):
super().__init__()
assert (
dim % num_heads == 0
), f"dim {dim} should be divided by num_heads {num_heads}."
assert norm_layer in ("LayerNorm", "BatchNorm1d")
if norm_layer == "BatchNorm1d":
assert num_patches is not None
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
if norm_layer == "LayerNorm":
self.norm = nn.LayerNorm(normalized_shape=dim)
elif norm_layer == "BatchNorm1d":
assert (num_patches % sr_ratio ** 2) == 0
self.norm = nn.BatchNorm1d(num_features=num_patches // sr_ratio**2)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
B, N, C = x.shape
q = (
self.q(x)
.reshape(B, N, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = (
self.kv(x_)
.reshape(B, -1, 2, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
)
else:
kv = (
self.kv(x)
.reshape(B, -1, 2, self.num_heads, C // self.num_heads)
.permute(2, 0, 3, 1, 4)
)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def drop_path(
x, drop_prob: float = 0.0, training: bool = False, scale_by_keep: bool = True
):
if drop_prob == 0.0 or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (
x.ndim - 1
) # work with diff dim tensors, not just 2D ConvNets
random_tensor = x.new_empty(shape).bernoulli_(keep_prob)
if keep_prob > 0.0 and scale_by_keep:
random_tensor.div_(keep_prob)
return x * random_tensor
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
def __init__(self, drop_prob: float = 0.0, scale_by_keep: bool = True):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
self.scale_by_keep = scale_by_keep
def forward(self, x):
return drop_path(x, self.drop_prob, self.training, self.scale_by_keep)
def extra_repr(self):
return f"drop_prob={round(self.drop_prob,3):0.3f}"
class Block(nn.Module):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=False,
qk_scale=None,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer: str = "LayerNorm",
num_features: Optional[int] = None,
sr_ratio=1,
):
super().__init__()
if norm_layer == "LayerNorm":
self.norm1 = nn.LayerNorm(normalized_shape=dim)
elif norm_layer == "BatchNorm1d":
self.norm1 = nn.BatchNorm1d(num_features=num_features)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
sr_ratio=sr_ratio,
norm_layer=norm_layer,
num_patches=num_features
)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
if norm_layer == "LayerNorm":
self.norm2 = nn.LayerNorm(normalized_shape=dim)
elif norm_layer == "BatchNorm1d":
self.norm2 = nn.BatchNorm1d(num_features=num_features)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop,
)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class OverlapPatchEmbed(nn.Module):
"""Image to Patch Embedding"""
def __init__(
self,
img_size=224,
patch_size=7,
stride=4,
in_chans=3,
embed_dim=768,
norm_layer: str = "LayerNorm",
):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
padding_h, padding_w = patch_size[0] // 2, patch_size[1] // 2
self.H, self.W = (
(img_size[0] - patch_size[0] + 2 * padding_h) // stride + 1,
(img_size[1] - patch_size[1] + 2 * padding_w) // stride + 1,
) # changed it from original implementation mg_size[0] // patch_size, img_size[1] // patch_size
self.num_patches = (
self.H * self.W
) # computed but not used in original implementation.
self.proj = nn.Conv2d(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
padding=(padding_h, padding_w),
)
if norm_layer == "LayerNorm":
self.norm = nn.LayerNorm(normalized_shape=embed_dim)
elif norm_layer == "BatchNorm1d":
self.norm = nn.BatchNorm1d(num_features=self.num_patches)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
def to_2tuple(x) -> Tuple[int, int]:
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
return tuple(x)
if isinstance(x, np.ndarray) and len(x) == 2:
return tuple(x)
return tuple(repeat(x, 2))
class MixVisionTransformer(
nn.Module
): # https://github.com/NVlabs/SegFormer/blob/master/mmseg/models/backbones/mix_transformer.py
def __init__(
self,
img_size: np.ndarray = np.array([224, 224]).astype(np.uint32),
patch_size=16, # FIXME: unused. I will leave it here since this is the original implementation.
# (will be removed once Hailo will support all the layers we need)
in_chans=3,
num_classes=1000,
embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8],
mlp_ratios=[4, 4, 4, 4],
qkv_bias=False,
qk_scale=None,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.0,
norm_layer: str = "LayerNorm",
depths=[3, 4, 6, 3],
sr_ratios=[8, 4, 2, 1],
):
super().__init__()
assert norm_layer in ("LayerNorm", "BatchNorm1d")
self.num_classes = num_classes
self.depths = depths
# patch_embed
self.patch_embed1 = OverlapPatchEmbed(
img_size=img_size,
patch_size=7,
stride=4,
in_chans=in_chans,
embed_dim=embed_dims[0],
norm_layer=norm_layer,
)
self.patch_embed2 = OverlapPatchEmbed(
img_size=img_size // 4,
patch_size=3,
stride=2,
in_chans=embed_dims[0],
embed_dim=embed_dims[1],
norm_layer=norm_layer,
)
self.patch_embed3 = OverlapPatchEmbed(
img_size=img_size // 8,
patch_size=3,
stride=2,
in_chans=embed_dims[1],
embed_dim=embed_dims[2],
norm_layer=norm_layer,
)
self.patch_embed4 = OverlapPatchEmbed(
img_size=img_size // 16,
patch_size=3,
stride=2,
in_chans=embed_dims[2],
embed_dim=embed_dims[3],
norm_layer=norm_layer,
)
# transformer encoder
dpr = [
x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
] # stochastic depth decay rule
cur = 0
self.block1 = nn.ModuleList(
[
Block(
dim=embed_dims[0],
num_heads=num_heads[0],
mlp_ratio=mlp_ratios[0],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[0],
num_features=(
np.prod(img_size // 4) if norm_layer == "BatchNorm1d" else None
),
)
for i in range(depths[0])
]
)
if norm_layer == "LayerNorm":
self.norm1 = nn.LayerNorm(normalized_shape=embed_dims[0])
elif norm_layer == "BatchNorm1d":
self.norm1 = nn.BatchNorm1d(num_features=np.prod(img_size // 4))
cur += depths[0]
self.block2 = nn.ModuleList(
[
Block(
dim=embed_dims[1],
num_heads=num_heads[1],
mlp_ratio=mlp_ratios[1],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[1],
num_features=(
np.prod(img_size // 8) if norm_layer == "BatchNorm1d" else None
),
)
for i in range(depths[1])
]
)
if norm_layer == "LayerNorm":
self.norm2 = nn.LayerNorm(normalized_shape=embed_dims[1])
elif norm_layer == "BatchNorm1d":
self.norm2 = nn.BatchNorm1d(num_features=np.prod(img_size // 8))
cur += depths[1]
self.block3 = nn.ModuleList(
[
Block(
dim=embed_dims[2],
num_heads=num_heads[2],
mlp_ratio=mlp_ratios[2],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[2],
num_features=(
np.prod(img_size // 16) if norm_layer == "BatchNorm1d" else None
),
)
for i in range(depths[2])
]
)
if norm_layer == "LayerNorm":
self.norm3 = nn.LayerNorm(normalized_shape=embed_dims[2])
elif norm_layer == "BatchNorm1d":
self.norm3 = nn.BatchNorm1d(num_features=np.prod(img_size // 16))
cur += depths[2]
self.block4 = nn.ModuleList(
[
Block(
dim=embed_dims[3],
num_heads=num_heads[3],
mlp_ratio=mlp_ratios[3],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[3],
num_features=(
np.prod(img_size // 32) if norm_layer == "BatchNorm1d" else None
),
)
for i in range(depths[3])
]
)
if norm_layer == "LayerNorm":
self.norm4 = nn.LayerNorm(normalized_shape=embed_dims[3])
elif norm_layer == "BatchNorm1d":
self.norm4 = nn.BatchNorm1d(num_features=np.prod(img_size // 32))
# classification head
# self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for i in range(self.depths[0]):
self.block1[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[0]
for i in range(self.depths[1]):
self.block2[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[1]
for i in range(self.depths[2]):
self.block3[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[2]
for i in range(self.depths[3]):
self.block4[i].drop_path.drop_prob = dpr[cur + i]
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
return {
"pos_embed1",
"pos_embed2",
"pos_embed3",
"pos_embed4",
"cls_token",
} # has pos_embed may be better
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=""):
self.num_classes = num_classes
self.head = (
nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
)
def forward_features(self, x):
B = x.shape[0]
outs = []
# stage 1
x, H, W = self.patch_embed1(x)
for i, blk in enumerate(self.block1):
x = blk(x, H, W)
x = self.norm1(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# stage 2
x, H, W = self.patch_embed2(x)
for i, blk in enumerate(self.block2):
x = blk(x, H, W)
x = self.norm2(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# stage 3
x, H, W = self.patch_embed3(x)
for i, blk in enumerate(self.block3):
x = blk(x, H, W)
x = self.norm3(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# stage 4
x, H, W = self.patch_embed4(x)
for i, blk in enumerate(self.block4):
x = blk(x, H, W)
x = self.norm4(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
def forward(self, x):
x = self.forward_features(x)
# x = self.head(x)
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class MiTB0(MixVisionTransformer):
def __init__(self, in_channels: int, img_size: np.ndarray, norm_layer: str):
super().__init__(
in_chans=in_channels,
img_size=img_size,
patch_size=4,
embed_dims=[32, 64, 160, 256],
num_heads=[1, 2, 5, 8],
mlp_ratios=[4, 4, 4, 4],
qkv_bias=True,
norm_layer=norm_layer,
depths=[2, 2, 2, 2],
sr_ratios=[8, 4, 2, 1],
drop_rate=0.0,
drop_path_rate=0.1,
)
class MLPDecoder(nn.Module):
def __init__(
self,
embed_dims: List[int],
decoder_embed_dim: int,
num_classes: int,
dropout_prob: float = 0.0,
):
super().__init__()
self.linear_layers = nn.ModuleList(
[MLP(embedding_dim, decoder_embed_dim) for embedding_dim in embed_dims]
)
self.relu = nn.ReLU()
n_stages = len(embed_dims)
self.linear_fuse = nn.Conv2d(
in_channels=decoder_embed_dim * n_stages,
out_channels=decoder_embed_dim,
kernel_size=1,
)
self.dropout = nn.Dropout(dropout_prob)
self.linear_pred = nn.Conv2d(decoder_embed_dim, num_classes, kernel_size=1)
def forward(self, features: List[torch.Tensor]):
new_features = []
target_resolution = features[0].shape[2:] # In the original implementation
# this resolution corresponds to (H/4,W/4), where H and W are the height and width of the original image.
for i in range(len(features)):
encoder_output = features[i]
n, _, h, w = encoder_output.shape
out = self.linear_layers[i](encoder_output)
out = nlc_to_nchw(out, h, w)
up_sampled_out = F.interpolate(
out, size=target_resolution, mode="bilinear", align_corners=False
)
new_features.append(up_sampled_out)
x = torch.cat(new_features, 1)
x = self.relu(self.linear_fuse(x))
x = self.dropout(x)
x = self.linear_pred(x)
return x
class SegFormerOriginalWithBatchNorm(torch.nn.Module):
def __init__(self, in_channels: int, img_size_hw: Tuple[int, int], num_classes: int):
super().__init__()
if isinstance(img_size_hw, list):
img_size_hw = tuple(img_size_hw)
assert isinstance(img_size_hw, tuple) and len(img_size_hw) == 2
self.encoder = MiTB0(in_channels=in_channels, img_size=np.array(img_size_hw), norm_layer="BatchNorm1d")
self.decoder = MLPDecoder(
embed_dims=[32, 64, 160, 256], decoder_embed_dim=256, num_classes=num_classes
)
def forward(self, x: torch.Tensor):
features = self.encoder(x)
out = self.decoder(features)
logits_mask = F.interpolate(out, size=x.shape[2:], mode="bilinear", align_corners=False)
return logits_mask
How I export the model:
model = SegFormerOriginalWithBatchNorm(in_channels=3, num_classes=2, img_size_hw=(256, 128))
input_shape_bchw = (1, 3, 256, 128)
tmp_onnx_output_path = "SegFormerOriginalWithBatchNorm.onnx"
# Export .ONNX succesfully.
convert_pytorch_2_onnx(torch_model=model, input_shape_bchw=input_shape_bchw, output_path=tmp_onnx_output_path)
tmp_har_path = "SegFormerOriginalWithBatchNorm.har"
# Crashes here
convert_onnx_2_har(onnx_path=tmp_onnx_output_path, har_path=tmp_har_path, input_shape_bchw=input_shape_bchw)
convert_torch_module_2_hef(
torch_module=model,
hef_path="MyTest.hef",
npy_rgb_unnormalized_bhwc_calibration_dataset_path=npy_calibration_dataset_path,
input_shape_bchw=input_shape_bchw,
apply_normalization=True
)
Conversion functions:
import os
import pathlib
import numpy as np
from typing import Union, Tuple, Optional, List, Dict
import onnx # ==1.14.0
import torch # ==2.3.0
def convert_pytorch_2_onnx(torch_model: torch.nn.Module, input_shape_bchw: Tuple[int, int, int, int], output_path: Union[str, pathlib.Path]) -> None:
torch_input = torch.randn(input_shape_bchw)
torch_model.eval()
with torch.no_grad():
torch.onnx.export(
torch_model,
torch_input,
str(output_path),
verbose=False,
do_constant_folding=False,
opset_version=15, # Use the appropriate ONNX opset version
input_names=["input"],
output_names=['output']
)
onnx_model = onnx.load(str(output_path))
onnx.checker.check_model(onnx_model)
def convert_onnx_2_har(
onnx_path: Union[str, pathlib.Path],
har_path: Union[str, pathlib.Path],
input_shape_bchw: Tuple[int, int, int, int],
hw_arch: str = "hailo8",
):
from hailo_sdk_client import ClientRunner, InferenceContext # noqa hailo_sdk_client==3.27.0
onnx_model_name = pathlib.Path(onnx_path).stem
onnx_model = onnx.load(onnx_path)
onnx_inputs = onnx_model.graph.input
onnx_outputs = onnx_model.graph.output
start_node_name = onnx_inputs[0].name
end_node_name = onnx_outputs[0].name
runner = ClientRunner(hw_arch=hw_arch)
_ = runner.translate_onnx_model(
str(onnx_path),
onnx_model_name,
start_node_names=[start_node_name],
end_node_names=[end_node_name],
net_input_shapes={start_node_name: input_shape_bchw}
)
runner.save_har(str(har_path))
test_images_bchw = np.random.randint(0, 255, size=input_shape_bchw)
b,c,h,w = input_shape_bchw
# test_images_bhwc = np.random.randint(0, 255, size=(b,h,w,c))
with runner.infer_context(InferenceContext.SDK_NATIVE) as ctx:
# CRASHES here.
native_res = runner.infer(ctx, test_images_bchw)