Hello, we have been working with DFC 3.23 in WSL2 with Ubuntu 20.04 environment for a while. But since we require our in-house learnt model of YOLOv8 to be compiled with DFC, it seems that 3.23 does not support in model script to call nms_postprocess() with the meta_arch arguement of yolov8.
So, we decided to install another virtual machine, with the Ubuntu-22.04, CUDA 11.8 and cuDNN of 8.9. DFC version is up to date with 3.29.
the thing is, everytime we try to compile our custom yolov8 model, following error message appears on the log and it automatically operates with the device of CPU. Here is the part of the logs that mention the situation.
![]()
and here’s the part of the logs showing it’s working with CPU only

We can verify that CUDA driver and GPU are working just fine by following methods
- verify it with tensorflow python API
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
print("Num GPUs Available: ", len(tf.config.list_physical_devices(‘GPU’)))
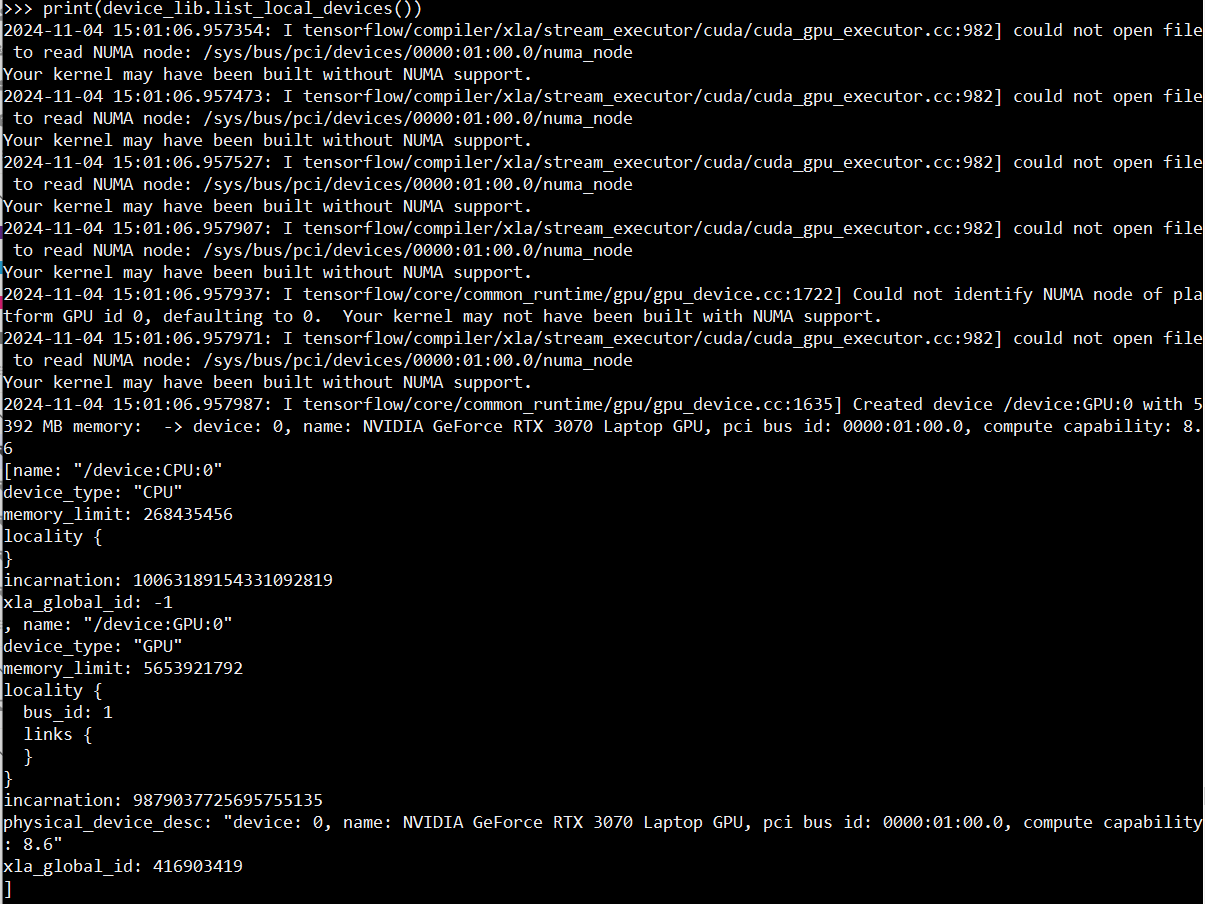
as you can see, GPU is recognized by tensorflow
- by building the CUDA sample app of deviceQuery and run it
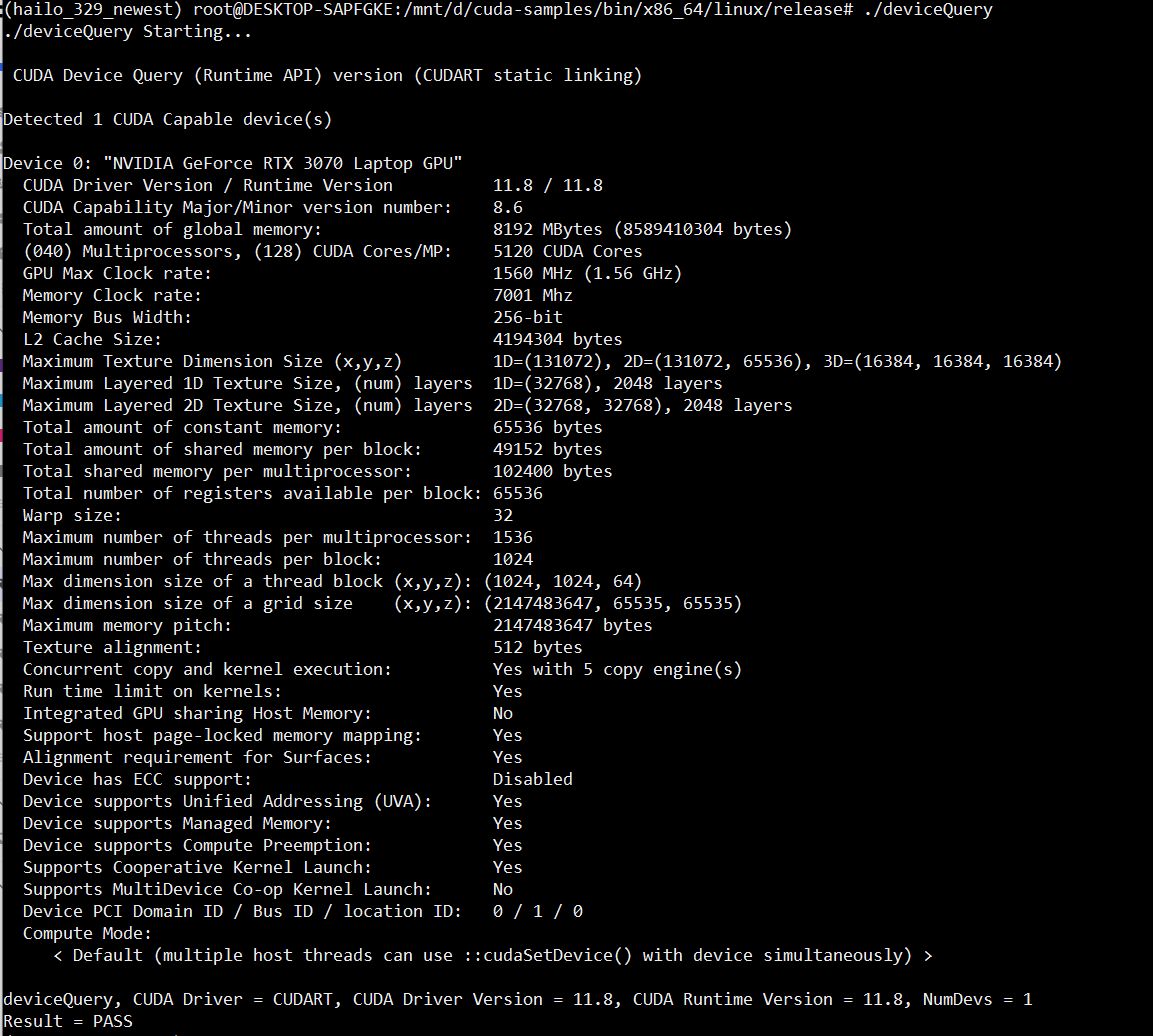
device is queried
- by learning the simple network with Tensorflow and see the GPU is utilized
→ succeeded
- WSL2 of Ubuntu-20.04, lower version of CUDA, CUDNN and DFC of 3.23
→ CUDA and CUDNN is loaded and working fine with the DFC
Right now, we are on a sort of test-the-water phase for the YOLOv8 so, it does not require us to run the optimization level other than 0. But, if it goes higher, not utilizing GPU would be a problem.
is this known nature of the 3.29? To be more specific, with the combination with the WSL2 environment? If so, could you give us any pointer to solve the problem?