Dear Hailo-Team,
I am currently looking into the deployment of the Dinov2_vits14 model provided by torch hub (torch.hub.load(“facebookresearch/dinov2”, ‘dinov2_vits14’). Converting the .onnx-file into the .har-representation worked out as well as the quantization of the model. However, the compliation step into the.hef-file fails during the execution of the following code snippet: #compile into .hef-format based on .har-file
onnx_model_name = ‘dino’
quantized_model_har_path = f"{onnx_model_name}_quantized_model.har"
runner = ClientRunner(har=quantized_model_har_path)
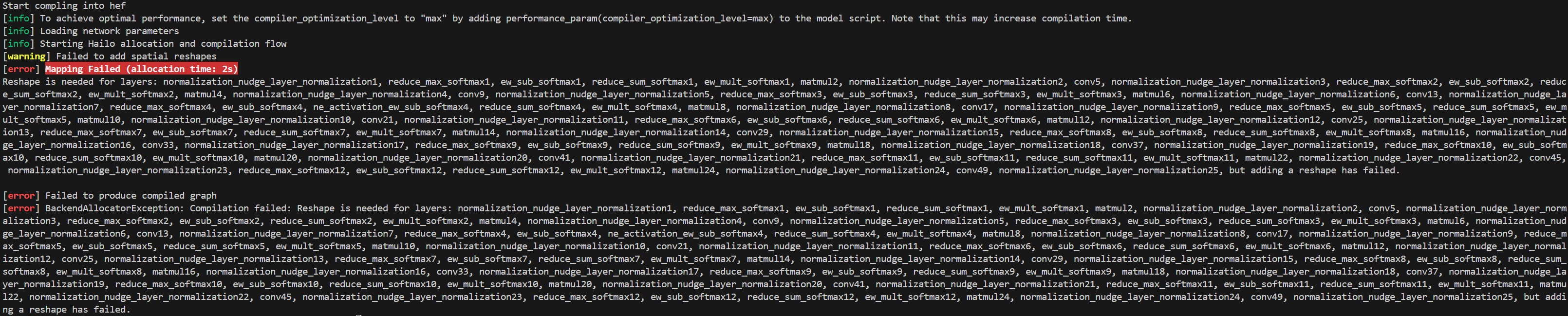
print(‘Start compling into hef’)
hef = runner.compile()
with open(quantized_model_har_path, “wb”) as f:
f.write(hef)
The error was as follows:
Verify Parameter Names: The error suggests the parameter name “normalization_nudge_layer_normalization” is invalid. Check the API documentation for the correct names.
Use Valid Names: Refer to the error message for valid options like “normalization1”, “normalization2”, “conv1”, or “normalization_nudge_layer_normalization1”. Update your code accordingly.
Update Naming Convention: If using older or incorrect formats, replace them with the recommended valid names (e.g., use “normalization1” instead of “normalization_nudge_layer_normalization”).
Set Optimization Level: Ensure the compiler_optimization_level is set to “max” by including performance_params(compiler_optimization_level=max) in your model script.
Consider Trade-offs: While setting optimization to “max” can improve inference performance, it might increase compilation time. Choose the optimization level based on your performance and time requirements.
By aligning parameter names with the valid options and properly configuring the optimization level, you can resolve this issue effectively.
@omria ’m encountering compilation issues with the dinovit2 model, similar to what I’ve experienced with other Vision Transformer models. I’ve examined the model zoo configuration through hailo8/base/vit_base.alls, but I’m still unsure how to proceed.
While quantization and .har file extraction were successful, the HEF compilation fails. Based on my research, I believe the issue might be related to the ViT’s tensor shape flow and incompatible dimensions:
After Patch Embed: (N, 768, 16, 16) — Conv-like 4D shape, no issues here.
Subsequent LayerNorm, MatMul, Softmaxblocks continue using this 3D shape.
The compiler tries to automatically insert 2D ↔ 4D reshapes around MatMul for precision_change layers, but fails to find compatible intermediate shapes, resulting in the error: “Reshape is needed… but adding a reshape has failed.”
This appears to be independent of input dimensions (224×224×3), output dimensions (16×16×768), or batch size. Even though the output is already in a 4D Conv-like format, the intermediate 3D token tensors seem to be causing the issue.
But why hailo_model_zoo/cfg/alls/hailo8/base/vit_base.alls can works well though problem that I have? I don’t know what problem cause exactly..
Could you please guide me on which documentation sections I should read or what approaches I should explore to resolve this compilation problem with Vision Transformer architectures?
The following code is for generating an alls file that is taken/modified from the vit_small.alls. This should allow you to compile dinov2_vits14, I have tested and it compiles fine.
model_name = "ONNXFILENAME" # If your onnx is named dinov2.onnx, this should be "dinov2"
alls_lines = [
"norm_layer1 = normalization([109.125, 116.28, 103.53], [58.395, 57.12, 57.375])",
"context_switch_param(mode=enabled)",
"allocator_param(enable_partial_row_buffers=disabled)",
"allocator_param(automatic_reshapes=disabled)",
"model_optimization_config(calibration, batch_size=16, calibset_size=1024)",
"pre_quantization_optimization(equalization, policy=enabled)",
"pre_quantization_optimization(ew_add_fusing, policy=disabled)",
f"model_optimization_flavor(optimization_level=0, compression_level=0)",
"pre_quantization_optimization(matmul_correction, layers={matmul*}, correction_type=zp_comp_block)",
"model_optimization_config(negative_exponent, layers={*}, rank=0)",
f"quantization_param({{{model_name}/ew_add*}}, precision_mode=a16_w16)",
f"quantization_param({{{model_name}/ew_add1}}, precision_mode=a8_w8)",
"resources_param(max_apu_utilization=0.9, max_compute_16bit_utilization=0.9, max_compute_utilization=0.9, max_control_utilization=0.9, max_input_aligner_utilization=0.9, max_memory_utilization=0.85)"
]
runner.load_model_script("\n".join(alls_lines))