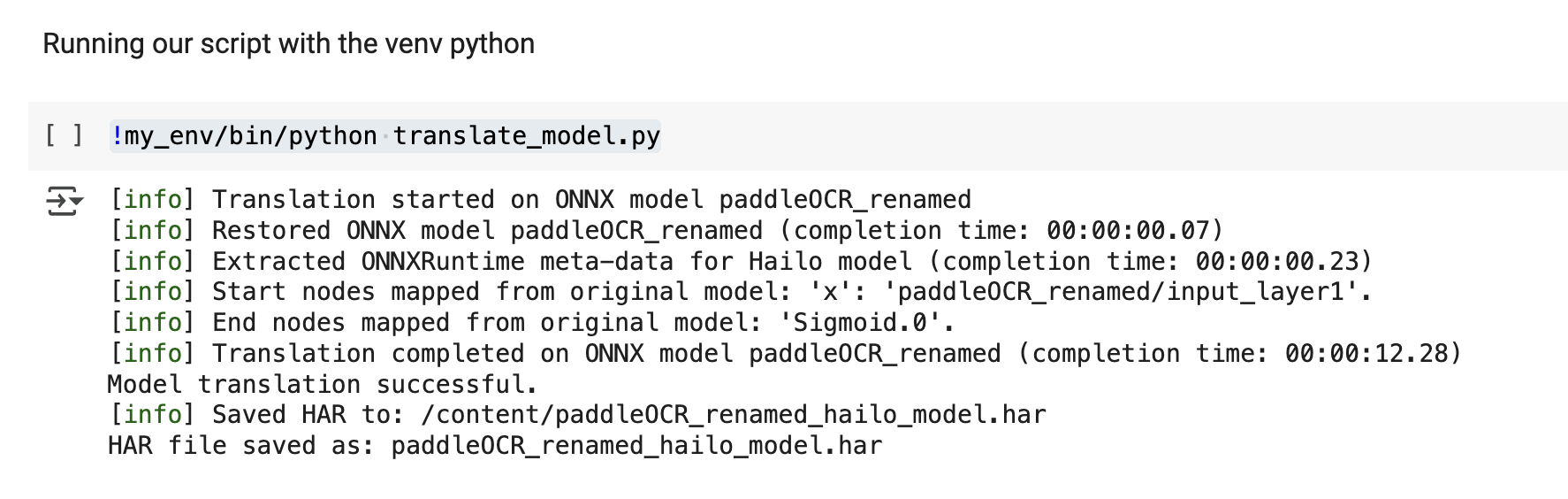
I was just wondering if anyone has / is able to compile PaddleOCR into a HEF file. I want to use PaddleOCR since it’s reliable and very accurate, however even though I have a successful compilation with the DFC, in the final step it resulted in a noise analysis of -3dB, which I assume is pretty bad. This is probably due to the compilation step, I’m not really sure what goes in the .alls file, and nms_config if that’s applicable in this case.
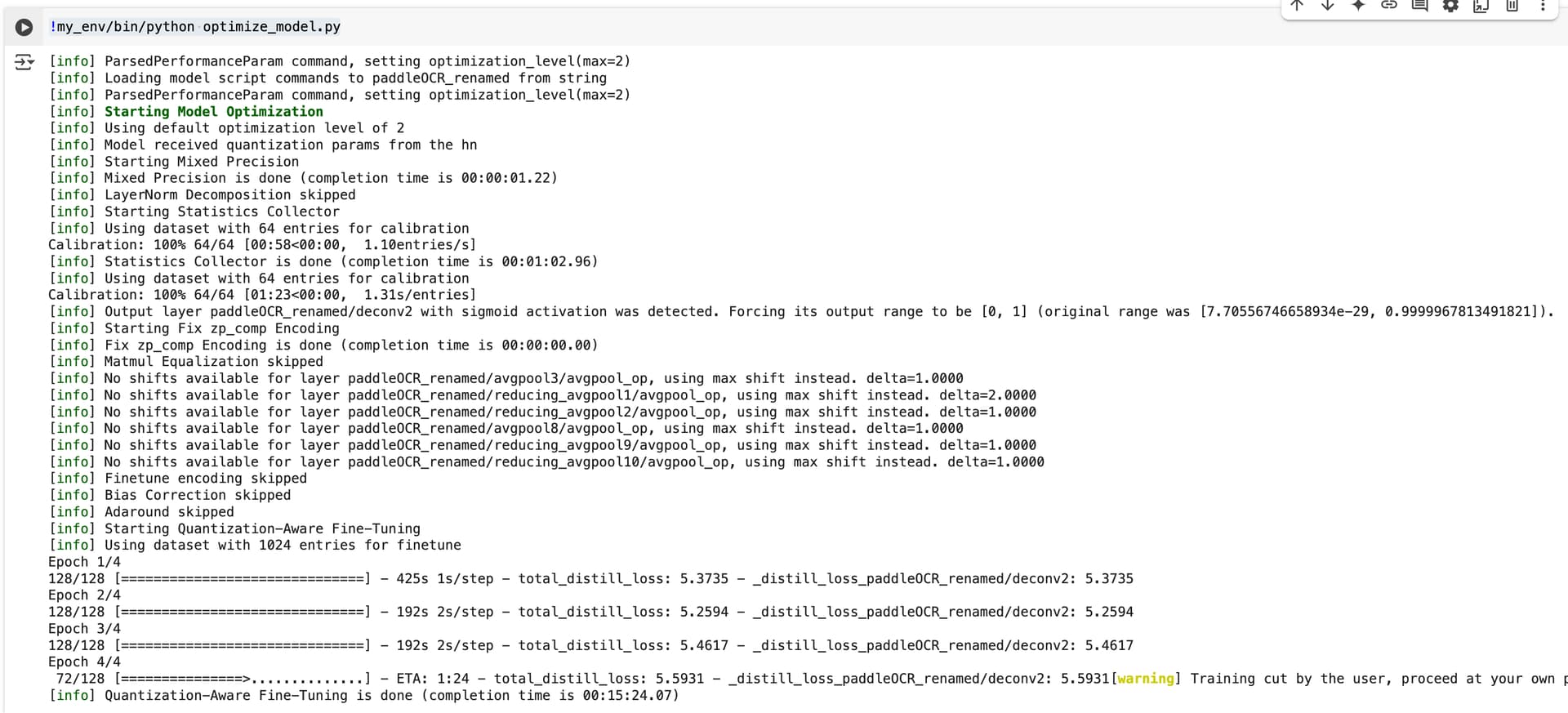
The purpose of this is similar to the LPR use case here, but for a different set of objects including letters. I was also having a lot of trouble with the calibration dataset, as I’m not sure what to pass there, where I normalized and unnormalized the calibration data, and got many errors shown below:
!my_env/bin/python optimize_model.py
[info] ParsedPerformanceParam command, setting optimization_level(max=2)
[info] Loading model script commands to paddleOCR_renamed from string
[info] ParsedPerformanceParam command, setting optimization_level(max=2)
[info] Starting Model Optimization
[info] Using default optimization level of 2
[info] Model received quantization params from the hn
[info] Starting Mixed Precision
[info] Mixed Precision is done (completion time is 00:00:01.22)
[info] LayerNorm Decomposition skipped
[info] Starting Statistics Collector
[info] Using dataset with 64 entries for calibration
Calibration: 100% 64/64 [00:58<00:00, 1.10entries/s]
[info] Statistics Collector is done (completion time is 00:01:02.96)
[info] Using dataset with 64 entries for calibration
Calibration: 100% 64/64 [01:23<00:00, 1.31s/entries]
[info] Output layer paddleOCR_renamed/deconv2 with sigmoid activation was detected. Forcing its output range to be [0, 1] (original range was [7.70556746658934e-29, 0.9999967813491821]).
[info] Starting Fix zp_comp Encoding
[info] Fix zp_comp Encoding is done (completion time is 00:00:00.00)
[info] Matmul Equalization skipped
[info] No shifts available for layer paddleOCR_renamed/avgpool3/avgpool_op, using max shift instead. delta=1.0000
[info] No shifts available for layer paddleOCR_renamed/reducing_avgpool1/avgpool_op, using max shift instead. delta=2.0000
[info] No shifts available for layer paddleOCR_renamed/reducing_avgpool2/avgpool_op, using max shift instead. delta=1.0000
[info] No shifts available for layer paddleOCR_renamed/avgpool8/avgpool_op, using max shift instead. delta=1.0000
[info] No shifts available for layer paddleOCR_renamed/reducing_avgpool9/avgpool_op, using max shift instead. delta=1.0000
[info] No shifts available for layer paddleOCR_renamed/reducing_avgpool10/avgpool_op, using max shift instead. delta=1.0000
[info] Finetune encoding skipped
[info] Bias Correction skipped
[info] Adaround skipped
Here is my alls script, these were the arguments that allowed it to compile, not sure if they are right:
normalization = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool1, division_factors=[2, 2])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool2, division_factors=[2, 2])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool9, division_factors=[2, 2])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool10, division_factors=[4, 4])
performance_param(compiler_optimization_level=max)
My primary question is just to see if anyone was able to compile PaddleOCR with accurate results, and what data should be in the calibration set, should it match the original training data of the model, normalized or unnormalized?