I’ve pretty easily implemented the Facial Recognition system documented here Facial Recognition with PySDK and it’s working great. My one concern is that the very first time I use the facial detection model it takes about 1.5 seconds. Same for the first time I use the facial vectoring model (again about 1.5 seconds). After that first use though the inferencing goes to 0.02 or so. Huge difference. Is this a known thing where we should be doing some sort of initialization before using it in real-time frame analysis? Should we just run a blank inference on start-up to “prime” it? Images show times on first inference and second.
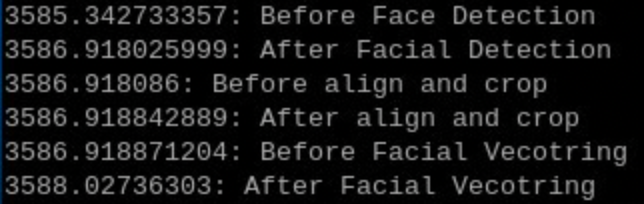
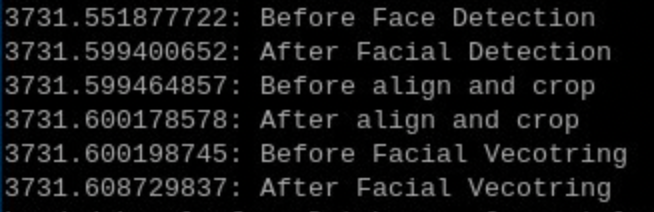
Code:
face_rec_model_name = "arcface_mobilefacenet--112x112_quant_hailort_hailo8l_1"
face_det_model_name = "scrfd_500m--640x640_quant_hailort_hailo8l_1"
# Face Model
FaceModel = dg.load_model(
model_name=face_det_model_name,
inference_host_address=your_host_address,
zoo_url=your_model_zoo,
token=your_token,
device_type=device_type,
overlay_color=[(255,255,0),(0,255,0)]
)
# Face Recognition Model
FaceVectorModel = dg.load_model(
model_name=face_rec_model_name,
inference_host_address=your_host_address,
zoo_url=your_model_zoo,
token=your_token,
device_type=device_type,
)
##. INSIDE SOME FUNCTION....
print(f"{time.monotonic()}: Before Face Detection")
faceDetectResult = FaceModel(imageForFaceRec)
print(f"{time.monotonic()}: After Facial Detection")
if len(faceDetectResult.results) > 0:
face = faceDetectResult.results[0]
if "label" in face and face["label"] == "face":
if "score" in face and face["score"] > min_confidence:
# Extract bounding box (assumed in [x1, y1, x2, y2] format)
x1, y1, x2, y2 = map(int, face["bbox"]) # Convert bbox coordinates to integers
cropped_face, _ = self.crop_with_context(imageForFaceRec, [x1, y1, x2, y2])
# Display cropped faces for testing
if DEBUG:
cv2.imshow('Face', cropped_face)
# align and crop face.
landmarks = [landmark["landmark"] for landmark in face["landmarks"]]
print(f"{time.monotonic()}: Before align and crop")
aligned_face, _ = self.align_and_crop(imageForFaceRec, landmarks)
print(f"{time.monotonic()}: After align and crop")
#
# Display the aligned face
if DEBUG:
cv2.imshow('Aligned Face', aligned_face)
# Get the embeddings
print(f"{time.monotonic()}: Before Facial Vecotring")
face_embedding = FaceVectorModel(aligned_face).results[0]["data"][0]
print(f"{time.monotonic()}: After Facial Vecotring")
self.faceVector = face_embedding
Thank you.