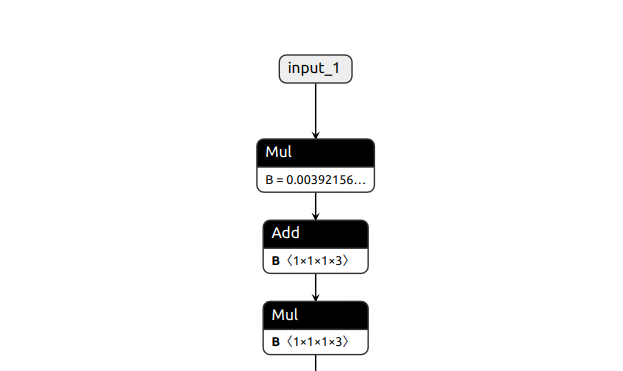
Yes indeed the first Mul is used for rescaling and Add, Mul operators correspond to normalization. This happens when you use Keras to create your model. The normalization operations are automatically folded into your model. Here is such an example for efficientnet: keras/keras/applications/efficientnet.py at v2.9.0 · keras-team/keras · GitHub
The advantage of doing so is that the CPU doesn’t need to normalize the data before inference.
The Hailo parser can support these operations as well but it is more efficient to skip these operations during parsing and add a normalization layer with the model modification command during optimization. This way, the normalization will be performed on-chip in an optimized manner.
Here are the steps:
When using Hailo parser, you must skip these operations during parsing by setting the start_node to be equal to the node below the last Mul operator and the parsed model won’t contain these operations. Note that the subsequent node could be some other operators such as transpose that is not supported so you might have to skip it as well. Transpose operator at the beginning of a model is generally used to reformat the ordering of the pixels from NCHW to NHWC and it usually can be skipped because the CPU can easily prepare an image in this format.
After parsing, you can add the normalization back to the model as a model modification command normalization().
The modification command is written to the model script file with extension *.alls, Example:
'normalization1 = normalization([123.675, 116.28, 103.53], [58.395, 57.12, 57.375])\n',
The first array is the mean array and the second array is the standard deviation array. These values are relative to the range of the data fed to the model. Here the input data is an image in the [0 255] range.
How do you find out the values to pass in these arrays from the original model ?
If you have the original Kera model, to display the weights value of the normalization layers, use the following code:
model = keras.models.load_model(hdf5_path)
model.summary()
Here, the model used as example will give you:
Model: "functional_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 224, 224, 3) 0
__________________________________________________________________________________________________
rescaling (Rescaling) (None, 224, 224, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
normalization (Normalization) (None, 224, 224, 3) 7 rescaling[0][0]
__________________________________________________________________________________________________
stem_conv_pad (ZeroPadding2D) (None, 225, 225, 3) 0 normalization[0][0]
__________________________________________________________________________________________________
stem_conv (Conv2D) (None, 112, 112, 40) 1080 stem_conv_pad[0][0]
__________________________________________________________________________________________________
…
This allows you to get the name of the normalization layer which is “normalization”
Next you do:
print(model.get_layer("normalization").get_weights())
which gives you the mean and std values:
[array([0.485, 0.456, 0.406], dtype=float32), array([0.229, 0.224, 0.225], dtype=float32), 0]
Note that there is a rescaling layer before with coefficient 1/255= 0.000392156 and it is displayed as coefficient B in the first Mul operation of the ONNX graph shown above. But you can also run print(model.get_layer(“rescaling”).get_weights())
So the normalization values you need are:
'normalization1 = normalization([255*0.485, 255*0.456, 255*0.406], [255*0.229, 255*0.224, 255*0.225])\n',