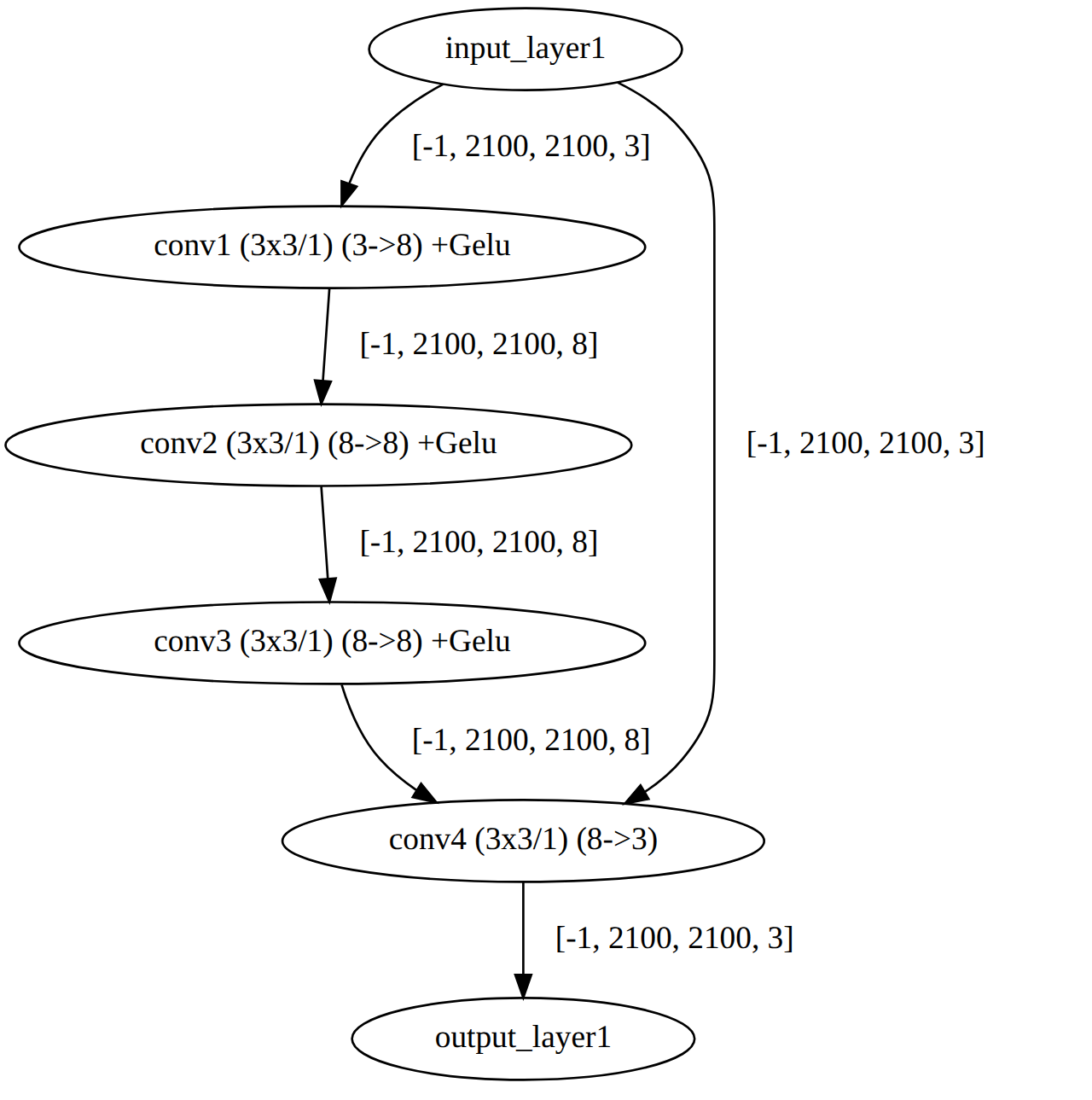
Hi, I have a custom model with few convolution layers. The input is RGB image and output is also RGB image (usually 16 bit but even 8 bit images are not working).
I had convert the model to hef using the below workflow
Parsing
hailo parser onnx /local/workspace/hap/ImgEnhanceNet_2blocks.onnx --net-name ImgEnhanceNet_2blocks --har-path /local/workspace/hap/ImgEnhanceNet_2blocks.parsed.har --input-format input=NCHW --tensor-shapes input=[1,3,2100,2100] --hw-arch hailo8 -y --parsing-report-path /local/workspace/hap/parsing_report.json
optimizing
hailo optimize /local/workspace/hap/ImgEnhanceNet_2blocks.parsed.har --calib-set-path /local/workspace/hap/calibration_data.npy --output /local/workspace/hap/ImgEnhanceNet_2blocks.optimized.har --hw-arch hailo8
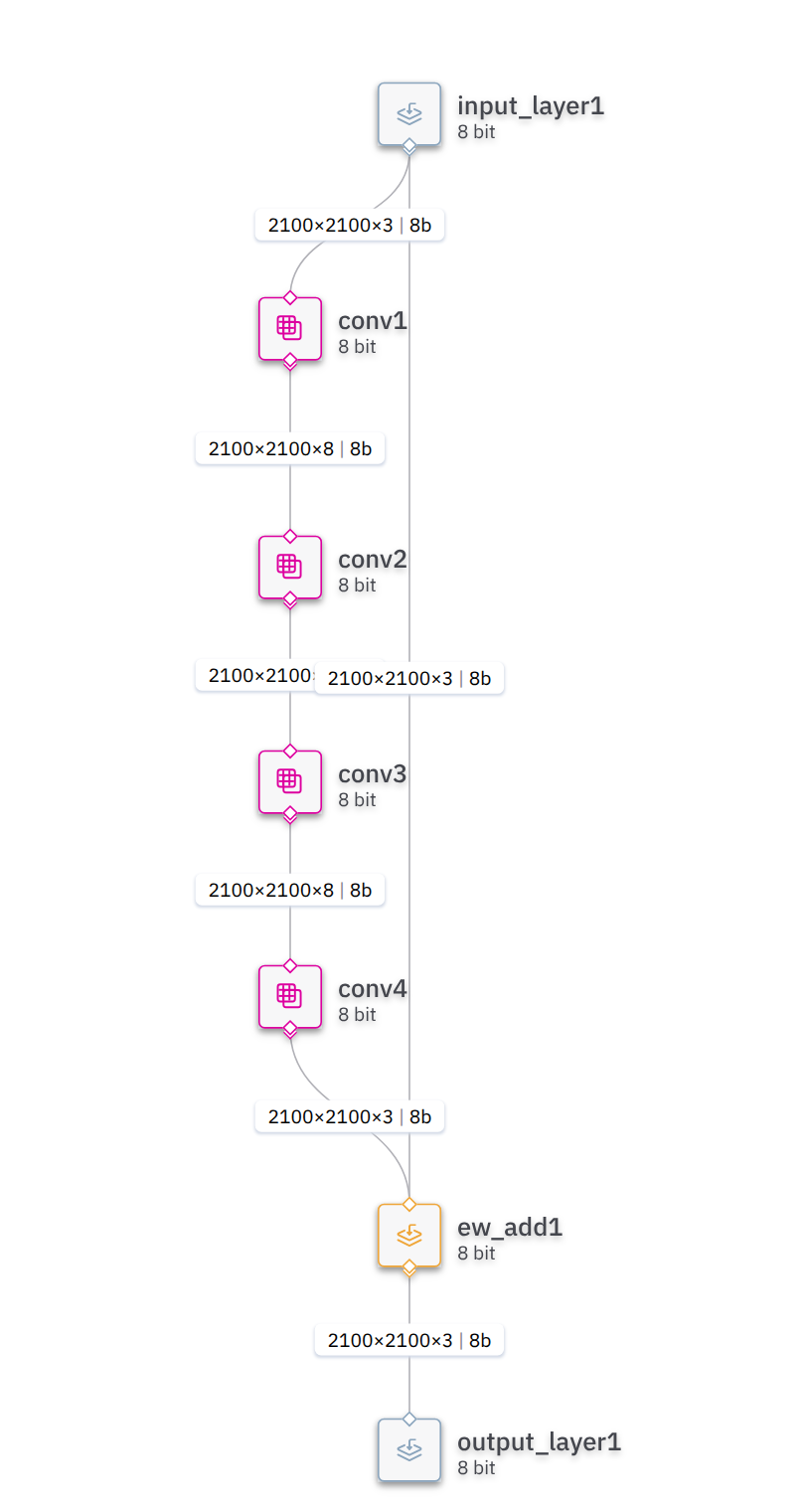
(I have attached the image from visualizer for optimized .har in this post
)
compiling
hailo compiler /local/workspace/hap/ImgEnhanceNet_2blocks.optimized.har --output-dir /local/workspace/hap --hw-arch hailo8.
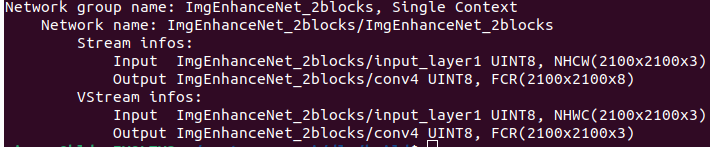
Using the hailortcli, when I check the network, I get : hailortcli parse-hef ../ImgEnhanceNet_2blocks.hef
Architecture HEF was compiled for: HAILO8
Network group name: ImgEnhanceNet_2blocks, Single Context
Network name: ImgEnhanceNet_2blocks/ImgEnhanceNet_2blocks
VStream infos:
Input ImgEnhanceNet_2blocks/input_layer1 UINT8, NHWC(2100x2100x3)
Output ImgEnhanceNet_2blocks/conv4 UINT8, FCR(2100x2100x3)
---------------> first, what is FCR ?? should it not be NHWC(2100x2100x3) at output as well ?
############
Now when I load the hef file in my c++ program, my log is : hap@hap:~/Image_Processing/HAP/hailo_hef/C++/build$ ./hailo_inference
[HailoRT] [warning] Desc page size value (1024) is not optimal for performance.
[Sun Jul 27 19:00:50 2025] [INFO] Input stream: ImgEnhanceNet_2blocks/input_layer1, Output stream: ImgEnhanceNet_2blocks/conv4
[Sun Jul 27 19:00:50 2025] [INFO] Input stream info: Name=ImgEnhanceNet_2blocks/input_layer1, Shape=[2100,2100,3], Format=UINT8
[Sun Jul 27 19:00:50 2025] [INFO] Output stream info: Name=ImgEnhanceNet_2blocks/conv4, Shape=[2100,2100,3], Format=UINT8
[Sun Jul 27 19:00:50 2025] [INFO] Allocated buffers: Input shape=[1,3,2100,2100], Output shape=[1,3,2100,2100]
[Sun Jul 27 19:00:50 2025] [INFO] Hailo HEF file loaded successfully
[Sun Jul 27 19:00:50 2025] [INFO] Output directory created at /home/hap/Image_Processing/HAP/hailo_hef/C++/processed_hailo/
[Sun Jul 27 19:00:50 2025] [INFO] Processing image: /home/hap/Image_Processing/HAP/Images/00010_042223313_800.tiff
[Sun Jul 27 19:00:50 2025] [INFO] Loading image: /home/hap/Image_Processing/HAP/Images/00010_042223313_800.tiff, Channels: 3, Width: 13376, Height: 9528
[Sun Jul 27 19:00:52 2025] [WARN] Failed to get GeoTransform, using default
[Sun Jul 27 19:00:52 2025] [INFO] Image load time: 1.904000 seconds
[Sun Jul 27 19:00:52 2025] [INFO] Applying white balancing…
[Sun Jul 27 19:00:55 2025] [INFO] White balance time: 2.932000 seconds
[Sun Jul 27 19:00:55 2025] [INFO] Processing 00010_042223313_800 with crops
[Sun Jul 27 19:00:55 2025] [INFO] Generated 35 crop locations
[Sun Jul 27 19:00:55 2025] [INFO] Number of crops: 35
[Sun Jul 27 19:00:55 2025] [DEBUG] Reading output stream with buffer size: 13230000 bytes
[HailoRT] [error] CHECK failed - Read size 13230000 must be 35280000
[Sun Jul 27 19:00:55 2025] [ERROR] Failed to read from output stream: Invalid argument
terminate called after throwing an instance of ‘std::runtime_error’
what(): Output stream read failed
Aborted (core dumped)
– The output streams expects 35280000 which is 8x2100x2100 but the output of my model should have only 3 channels. Is there a bug in hailort version 4.22 ??
The class of my C++ code is : // Helper function to convert hailo_status to string
std::string status_to_string(hailo_status status) {
switch (status) {
case HAILO_SUCCESS: return “SUCCESS”;
case HAILO_INVALID_ARGUMENT: return “Invalid argument”;
case HAILO_UNINITIALIZED: return “Not initialized”;
case HAILO_OUT_OF_FW_MEMORY: return “Out of memory”;
case HAILO_NOT_FOUND: return “Device or resource not found”;
case HAILO_INVALID_HEF: return “Invalid HEF file”;
case HAILO_INTERNAL_FAILURE: return “Internal failure”;
case HAILO_OUT_OF_HOST_MEMORY: return “Out of host memory”;
case HAILO_STREAM_ABORT: return “Stream aborted”;
case HAILO_INVALID_OPERATION: return “Invalid operation”;
default: return “Unknown error (” + std::to_string(status) + “)”;
}
}
// Helper function to convert hailo_format_type_t to string
std::string format_type_to_string(hailo_format_type_t format) {
switch (format) {
case HAILO_FORMAT_TYPE_UINT8: return “UINT8”;
case HAILO_FORMAT_TYPE_UINT16: return “UINT16”;
case HAILO_FORMAT_TYPE_FLOAT32: return “FLOAT32”;
default: return “Unknown format (” + std::to_string(static_cast(format)) + “)”;
}
}
// Hailo Inference Class
class HailoInference {
private:
std::unique_ptrhailort::VDevice vdevice;
std::shared_ptrhailort::Hef hef;
std::vector<std::shared_ptrhailort::ConfiguredNetworkGroup> network_groups;
std::string input_name;
std::string output_name;
std::vector<int64_t> input_shape;
std::vector<int64_t> output_shape;
std::vector<std::vector<uint8_t>> input_buffers;
std::vector<std::vector<uint8_t>> output_buffers;
std::vector<std::reference_wrapperhailort::InputStream> input_streams;
std::vector<std::reference_wrapperhailort::OutputStream> output_streams;
int batch_size;
int output_channels;
public:
HailoInference(const std::string& hef_path, int batch_size) : batch_size(batch_size), output_channels(3) {
auto start = std::chrono::high_resolution_clock::now();
// Create VDevice
auto vdevice_exp = hailort::VDevice::create();
if (!vdevice_exp) {
log_message("ERROR", "Failed to create Hailo VDevice: " + status_to_string(vdevice_exp.status()));
throw std::runtime_error("VDevice creation failed");
}
vdevice = std::move(vdevice_exp.value());
// Load HEF file
auto hef_exp = hailort::Hef::create(hef_path);
if (!hef_exp) {
log_message("ERROR", "Failed to load HEF file: " + hef_path + " - " + status_to_string(hef_exp.status()));
throw std::runtime_error("HEF load failed");
}
hef = std::make_shared<hailort::Hef>(std::move(hef_exp.value()));
// Configure network group
auto configure_exp = vdevice->configure(*hef);
if (!configure_exp) {
log_message("ERROR", "Failed to configure network group: " + status_to_string(configure_exp.status()));
throw std::runtime_error("Network group configuration failed");
}
network_groups = std::move(configure_exp.value());
// Get input and output streams
input_streams = network_groups[0]->get_input_streams();
output_streams = network_groups[0]->get_output_streams();
if (input_streams.empty() || output_streams.empty()) {
log_message("ERROR", "Input or output streams not found");
throw std::runtime_error("Stream error");
}
input_name = input_streams[0].get().name();
output_name = output_streams[0].get().name();
log_message("INFO", "Input stream: " + input_name + ", Output stream: " + output_name);
// Log stream info
for (const auto& stream : input_streams) {
auto info = stream.get().get_info();
log_message("INFO", "Input stream info: Name=" + std::string(info.name) + ", Shape=[" +
std::to_string(info.shape.height) + "," + std::to_string(info.shape.width) + "," +
std::to_string(info.shape.features) + "], Format=" + format_type_to_string(info.format.type));
}
for (const auto& stream : output_streams) {
auto info = stream.get().get_info();
log_message("INFO", "Output stream info: Name=" + std::string(info.name) + ", Shape=[" +
std::to_string(info.shape.height) + "," + std::to_string(info.shape.width) + "," +
std::to_string(info.shape.features) + "], Format=" + format_type_to_string(info.format.type));
output_channels = info.shape.features;
}
// Set shapes
input_shape = {batch_size, 3, 2100, 2100};
output_shape = {batch_size, output_channels, 2100, 2100};
size_t input_size = std::accumulate(input_shape.begin(), input_shape.end(), 1, std::multiplies<int64_t>());
size_t output_size = std::accumulate(output_shape.begin(), output_shape.end(), 1, std::multiplies<int64_t>());
// Allocate buffers for UINT8
input_buffers.resize(batch_size, std::vector<uint8_t>(input_size / batch_size));
output_buffers.resize(batch_size, std::vector<uint8_t>(output_size / batch_size));
log_message("INFO", "Allocated buffers: Input shape=[" + std::to_string(input_shape[0]) + "," +
std::to_string(input_shape[1]) + "," + std::to_string(input_shape[2]) + "," +
std::to_string(input_shape[3]) + "], Output shape=[" + std::to_string(output_shape[0]) + "," +
std::to_string(output_shape[1]) + "," + std::to_string(output_shape[2]) + "," +
std::to_string(output_shape[3]) + "]");
if (PROFILE_PROGRAM) {
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start).count() / 1000.0;
log_message("PROFILE", "HailoInference constructor time: " + std::to_string(duration) + " seconds");
}
}
std::pair<std::vector<uint8_t>, double> infer(const std::vector<uint8_t>& input_data) {
auto start = std::chrono::high_resolution_clock::now();
if (DETAILED_LOG) {
log_message("DEBUG", "Starting inference with input size: " + std::to_string(input_data.size()) + " bytes");
}
size_t single_input_size = input_data.size() / batch_size;
size_t single_output_size = std::accumulate(output_shape.begin() + 1, output_shape.end(), 1, std::multiplies<int64_t>());
std::vector<uint8_t> output_data(single_output_size * batch_size);
// Split input data into per-batch buffers
for (int b = 0; b < batch_size; ++b) {
std::copy(input_data.begin() + b * single_input_size,
input_data.begin() + (b + 1) * single_input_size,
input_buffers[b].begin());
}
// Write input data to stream
for (int b = 0; b < batch_size; ++b) {
auto status = input_streams[0].get().write(hailort::MemoryView(input_buffers[b].data(), single_input_size * sizeof(uint8_t)));
if (status != HAILO_SUCCESS) {
log_message("ERROR", "Failed to write to input stream: " + status_to_string(status));
throw std::runtime_error("Input stream write failed");
}
}
// Read output data from stream
for (int b = 0; b < batch_size; ++b) {
size_t expected_output_size = single_output_size * sizeof(uint8_t);
log_message("DEBUG", "Reading output stream with buffer size: " + std::to_string(expected_output_size) + " bytes");
auto status = output_streams[0].get().read(hailort::MemoryView(output_buffers[b].data(), expected_output_size));
if (status != HAILO_SUCCESS) {
log_message("ERROR", "Failed to read from output stream: " + status_to_string(status));
throw std::runtime_error("Output stream read failed");
}
}
// Copy outputs
for (int b = 0; b < batch_size; ++b) {
std::copy(output_buffers[b].begin(), output_buffers[b].end(),
output_data.begin() + b * single_output_size);
}
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now() - start).count() / 1000.0;
if (DETAILED_LOG) {
log_message("DEBUG", "Inference completed, output size: " + std::to_string(output_data.size()) + " bytes");
}
if (PROFILE_PROGRAM) {
log_message("PROFILE", "Inference time: " + std::to_string(duration) + " seconds");
}
return {output_data, duration};
}
int get_output_channels() const { return output_channels; }
~HailoInference() {
network_groups.clear();
hef.reset();
vdevice.reset();
}
};
###############
Also, originally my model (onnx) is suppose to process aerial and satellite images at RGB 16 bit, but I am not able to optimize and covert the onnx to 16 .har and then convert to 16 bit .hef file. Any recommendation to do this conversion so that I can run my inference code on raw 16 bit rgb images. --full-precision-only in the hailo optimize do work but when given the output of this to hailo compiler, it throws error that it needs the quantized model.
Any help is very much appreciated as we want to deploy with hailo8 accelerator on High Altitude Platform drone.