I compiled PIPs BasicEncoder net into the HEF file, but the network did not meet my expectations.
BasicEncoder worked on 320x320x3 images normalized to [-1, 1] interval and created 40x40x128 representation of that image.
I created a calibration set that is normalized (deliberately ommited normalization in model_script.alls for debugging purposes) so I’d expect the net to have input and output layers to be of floating point type. Also while the input layer is named pips/input_layer1 (the same as in pips_compiled_model.html produced by hailo profiler pips_compiled.har) the output layer seem to be pips/conv22 (the one just before pips/output_layer1).
I checked that using the command:
docker-user@quczer-seagle:/mnt/ml-infra$ hailo parse-hef pips.hef
[info] Current Time: 11:44:12, 12/20/24
[info] CPU: Architecture: x86_64, Model: Intel(R) Core(TM) i9-10885H CPU @ 2.40GHz, Number Of Cores: 16, Utilization: 0.4%
[info] Memory: Total: 30GB, Available: 18GB
[info] System info: OS: Linux, Kernel: 6.8.0-49-generic
[info] Hailo DFC Version: 3.29.0
[info] HailoRT Version: 4.19.0
[info] PCIe: No Hailo PCIe device was found
[info] Running `hailo parse-hef pips.hef`
(hailo) Running command 'parse-hef' with 'hailortcli'
Architecture HEF was compiled for: HAILO8L
Network group name: pips, Multi Context - Number of contexts: 9
Network name: pips/pips
VStream infos:
Input pips/input_layer1 UINT8, NHWC(320x320x3)
Output pips/conv22 UINT8, FCR(40x40x128)
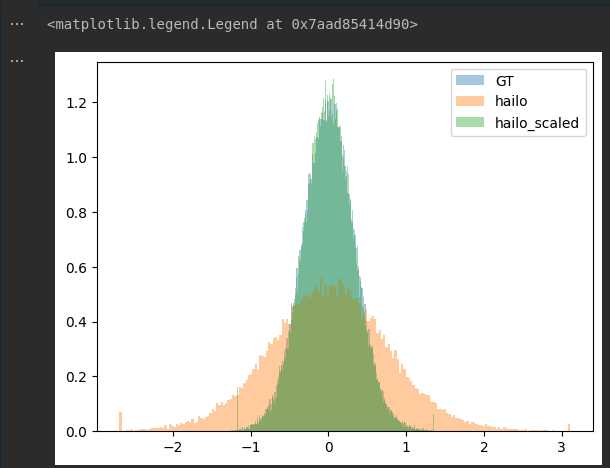
I looked at the 1D distribution of outputs and indeed it is of by some factor (GT - ground truth, hailo - net output, hailo_scaled output manyally rescaled)
Another problem is that both pips/input_layer1 and pips/conv22 are of UINT8 type, not FLOAT32 which was expected. I can then manually change it when creating hailo_platform.ConfiguredInferModel but this is a hint that something is wrong.
Do you have an idea why is the output layer missing and if that’s a problem?
Thanks in advance,
Michał