Hello, I have an UNet network used for infrared image reconstruction. After training, I exported the ONNX model and tested it, achieving a PSNR of up to 39 dB.
My DFC conversion and test code is as follows. The converted PSNR is only 32 dB, as shown in the code. I also used the highest optimization level and the lowest compression rate. Is the converted result normal?
runner = ClientRunner(hw_arch=HW_ARCH)
hn, npz = runner.translate_onnx_model(
onnx_path,
onnx_model_name,
net_input_shapes={"input": [8,1,480, 640]},
start_node_names=["input"],
end_node_names=["output"],
)
def prepare_calibration_data( num_images=1024):
calib_data = []
image_files = [f for f in os.listdir(CALIB_DIR) if f.endswith('.bmp')][:num_images]
for img_name in image_files:
img_path = os.path.join(CALIB_DIR, img_name)
with Image.open(img_path) as img:
img = img.resize((640, 480))
img_array = np.array(img, dtype=np.uint8)
calib_data.append(img_array)
return np.array(calib_data).reshape(num_images,480, 640,1)
def optimize_model(runner, logger):
calib_dataset = prepare_calibration_data(logger, num_images=1024)
np.random.shuffle(calib_dataset)
model_script = f"""
normalization1 = normalization([127.5], [127.5])
post_quantization_optimization(adaround, policy=enabled,shuffle=False,batch_size=16,learning_rate=0.001)
model_optimization_flavor(optimization_level=4,compression_level=0)
"""
with tempfile.NamedTemporaryFile(mode='w', suffix='.alls', delete=False) as f:
f.write(model_script)
script_path = f.name
runner.load_model_script(script_path)
runner.optimize(calib_dataset)
runner.save_har(QUANT_HAR_PATH)
def compile_to_hef():
runner = ClientRunner(har=QUANT_HAR_PATH)
hef = runner.compile()
with open(HEF_PATH, "wb") as f:
f.write(hef)
def validate_quantized_model(logger):
runner = ClientRunner(har=QUANT_HAR_PATH)
test_image = prepare_test_data(num_images=1)[0:1] # 单张测试图像
with runner.infer_context(InferenceContext.SDK_QUANTIZED) as ctx:
quant_output = runner.infer(ctx, test_image)
output_array = (quant_output[0] * 0.5 + 0.5) * 255 # 反归一化
output_array = np.clip(output_array, 0, 255).astype(np.uint8).squeeze()
output_img = Image.fromarray(output_array)
output_img.save("test_out.bmp")
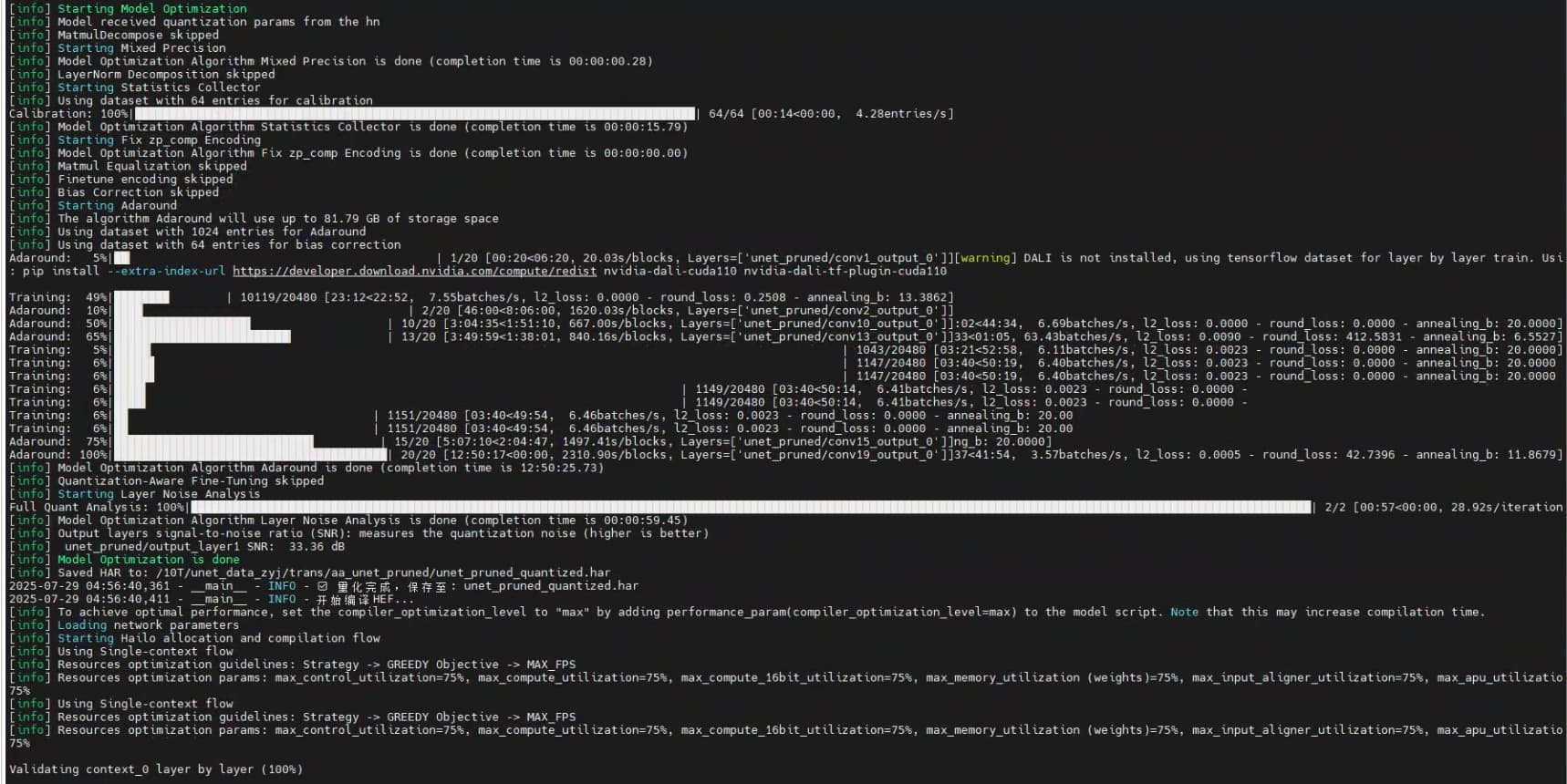
Some print information during the conversion process is as follows.n
It is worth noting that the results obtained by my use of full 16-bit quantization are quite similar to those obtained by full int8 quantization.
So, how can I improve the converted PSNR?
[info] Model Optimization Algorithm Layer Noise Analysis is done (completion time is 00:00:59.45)
[info] Output layers signal-to-noise ratio (SNR): measures the quantization noise (higher is better)
[info] unet_pruned/output_layer1 SNR: 33.36 dB
[info] Model Optimization is done