I understand how the scheduling is done for a single Hailo chip. The scheduler will schedule each model using round-robin and by following the constraints set by a model’s batch-size, threshold, timeout and priority.
But for multiple chips running in parallel, how is the scheduling is done ?
Imagine I have 4 models: (A), (B), (C) & (D) and two Hailo#0 and Hailo#1.
Are (A) and (B) scheduled on Hailo#0 and (C) and (D) scheduled on Hailo#1 ?
Or does it follow the same roundrobin technique ? For example (A) is scheduled first and then (B) is ready. The scheduler has two choices:
Wait for (A) to finish before running (B) on Hailo#0
Run (B) on Hailo#1 immediately.
Which choice it will take ?
Another question is when the multiplexer is enabled. Imagine we have one model A and two Hailo chips. We have multiple processes wanting to execute model A. Is model A loaded on the two chips to spread the load of multiple processes ?
For example, if I just have 2 processes wanting to execute model (A) at the same time. Will one process executes model A on Hailo#0 and the other process executes model A on Hailo#1 ?
Hi Victor,
For multiple chip, the Hailo model Scheduler is also built to locate if there are “idle” chips in case it is defined under the same VDevice (VDevice can represent one or more physical chips). If we take the scenario you mentioned, let’s assume that model A is loaded to device #0. The scheduler seems that device #1 is idle, so it loads the next model in line according to the Round Robin algorithm, let’s say it’s model B. Now it’s model C’s turn, so first the model scheduler looks for an idle devices. If it find one - it would be loaded to it, if not (like in out case that we have only 2 devices and they are both in use) - we continue with the Round Robin.
So, the Scheduler would check to see which device is “ready”, meaning that it finished inference on an image (or several if batch size>1) for the current model. Once it finds the “ready” device, the model switching will occur.
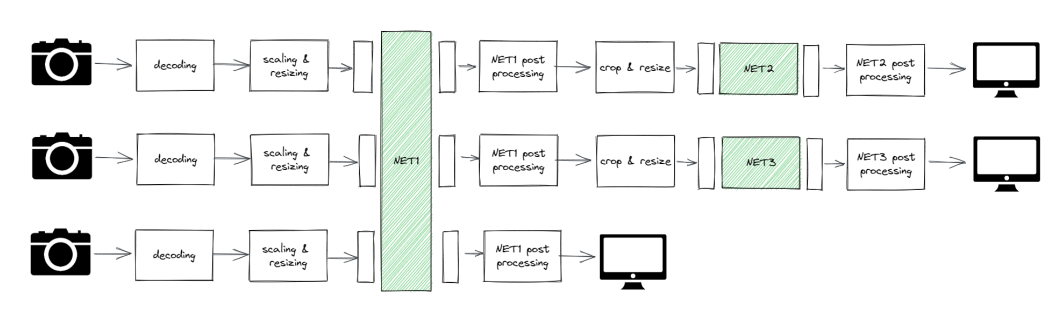
For the second question - The propose of the Multiplexer is to save time and resources in case we are using the same model for different streams:
In the image here, you can see that there are 3 streams for NET1, so in order to use the existing metadata and avoid the overhead of activation\de-activation, the Multiplexer recognize that this is the same model and uses the model’s resources.
The scenario you mentioned is not really relevant to the Multiplexer as it is not related to the distribution of networks on the Hailo chips.
Basically, the answer to your question is that you can have multiple applications running by different processes that shares a single device or have different processes running on two different devices that run the same model.