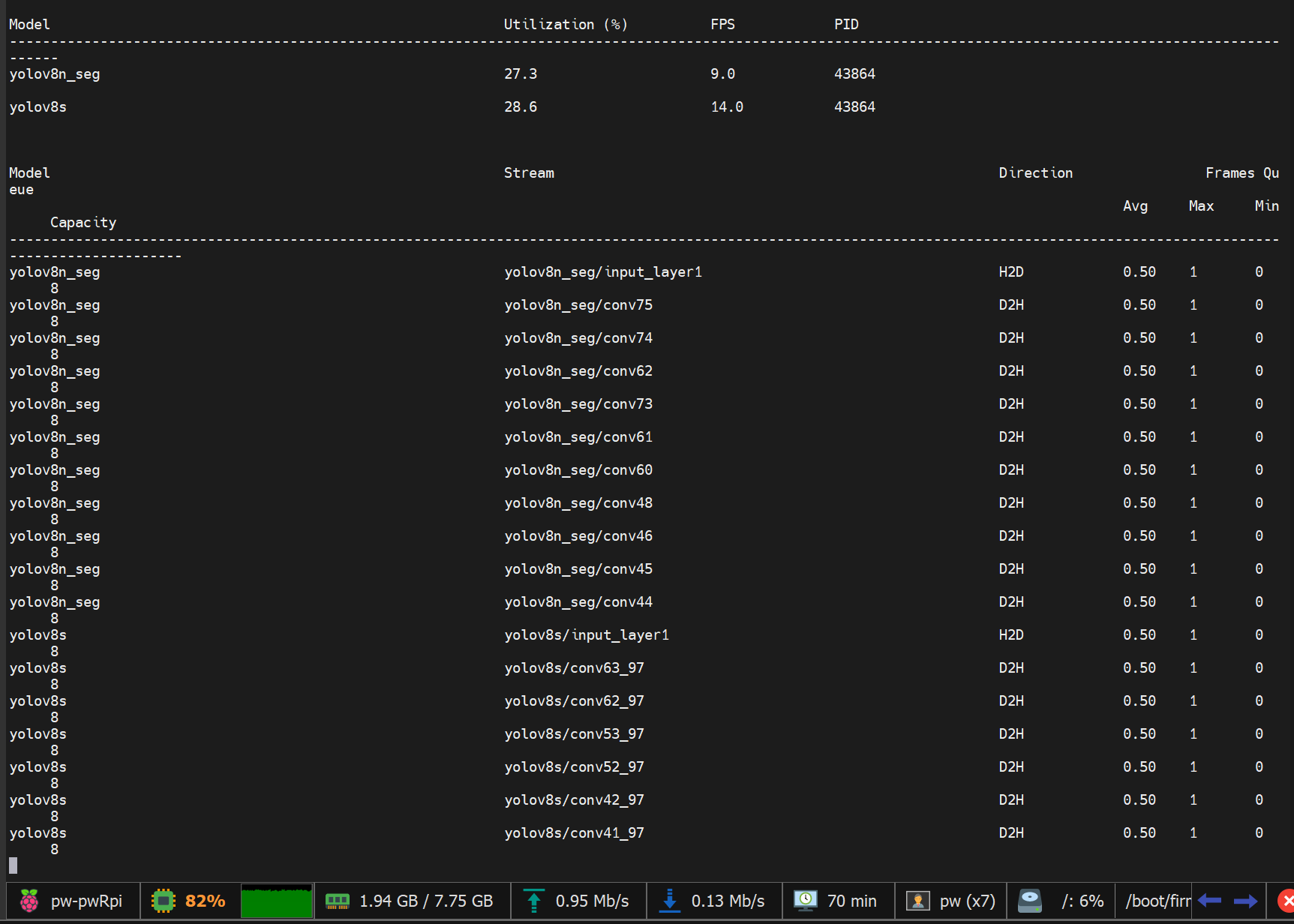
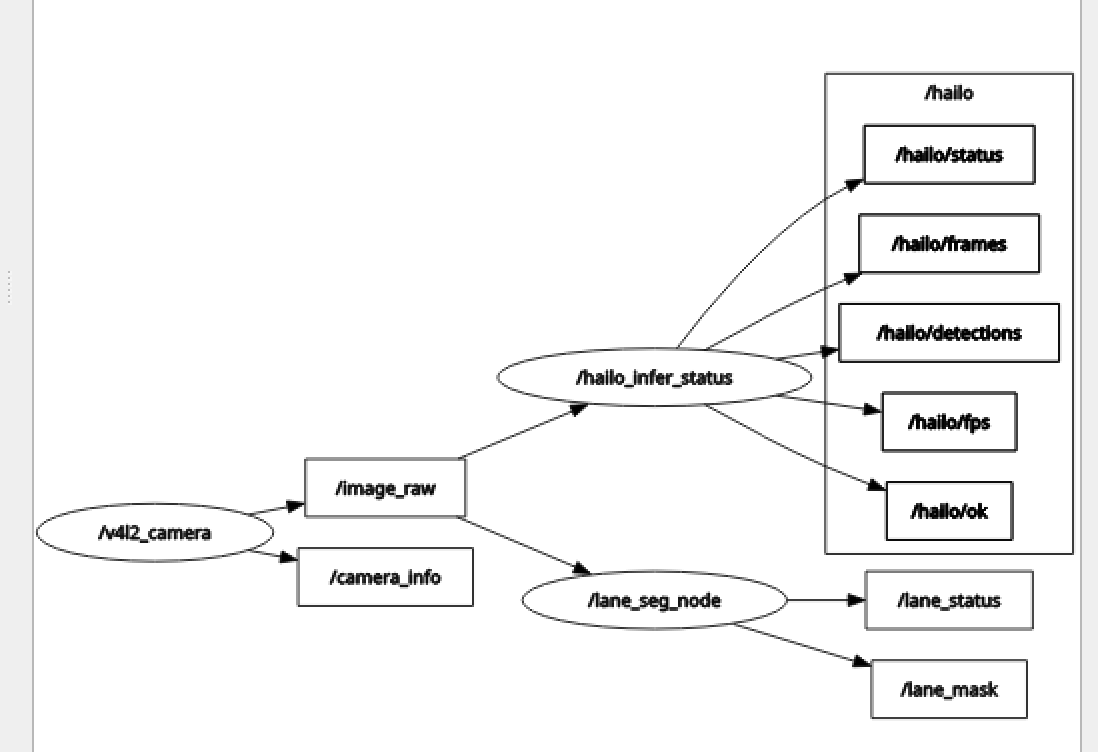
Thank you everyone, I have succesfully set up my parallel inference and publishing topic in ros2 environment
It was just simple as suggested,
adding this line under hailo_inference.py
params.multi_process_service = True
Nothing else since i utilized a lot of the framework already provided with the HailoRT Application examples
Now comese the problem, very slow fps, maybe we are cpu bound?
When running just the object detection model (yolov8s) i get stable 30FPS, hailo utilization at around 25%, but with both enabled their performance is very slow.
Am I doing something wrong with my post processing or something?
Here are some of my codes
import numpy as np, cv2, queue, time
from .hailo_inference import HailoInfer
def sigmoid(x): return 1.0 / (1.0 + np.exp(-x))
def softmax(x, axis=-1):
x = x - np.max(x, axis=axis, keepdims=True)
e = np.exp(x)
return e / np.sum(e, axis=axis, keepdims=True)
def as_nhwc(arr, expect_c):
if isinstance(arr, np.ndarray) and arr.ndim == 3:
arr = arr[None, ...]
if not isinstance(arr, np.ndarray) or arr.ndim != 4:
raise ValueError("Expected 3D/4D tensor, got {}".format(getattr(arr, "shape", None)))
n, a, b, c = arr.shape
if c == expect_c: return arr
if a == expect_c: return arr.transpose(0,2,3,1)
if b == expect_c: return arr.transpose(0,3,1,2).transpose(0,2,3,1)
raise ValueError("Cannot convert to NHWC with C={}, got {}".format(expect_c, arr.shape))
def letterbox_bgr(img, dst_wh):
dh, dw = dst_wh[1], dst_wh[0]
h, w = img.shape[:2]
r = min(dw / w, dh / h)
nw, nh = int(round(w*r)), int(round(h*r))
resized = cv2.resize(img, (nw, nh), interpolation=cv2.INTER_LINEAR)
out = np.zeros((dh, dw, 3), dtype=np.uint8)
top = (dh - nh) // 2
left = (dw - nw) // 2
out[top:top+nh, left:left+nw] = resized
return out, (top, left)
def xywh2xyxy(x):
y = x.copy()
y[:,0] = x[:,0] - x[:,2]/2; y[:,1] = x[:,1] - x[:,3]/2
y[:,2] = x[:,0] + x[:,2]/2; y[:,3] = x[:,1] + x[:,3]/2
return y
def nms_cpu(boxes, scores, iou_th, max_det):
if boxes.shape[0] == 0: return np.empty((0,), dtype=np.int64)
x1,y1,x2,y2 = [boxes[:,i] for i in range(4)]
areas = (x2-x1)*(y2-y1)
order = scores.argsort()[::-1]
keep = []
while order.size>0 and len(keep)<max_det:
i = order[0]; keep.append(i)
if order.size==1: break
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2-xx1); h = np.maximum(0.0, yy2-yy1)
inter = w*h
ovr = inter/(areas[i] + areas[order[1:]] - inter + 1e-9)
inds = np.where(ovr <= iou_th)[0]
order = order[inds+1]
return np.array(keep, dtype=np.int64)
def _assemble_heads(outputs):
boxes_scales, scores_scales, coeff_scales, proto = [], [], [], None
for _, arr in outputs.items():
for c_try in (64,32,1):
try:
nhwc = as_nhwc(arr, c_try)
except Exception:
continue
n,h,w,c = nhwc.shape
if c==64 and h in (20,40,80): boxes_scales.append(nhwc.astype(np.float32,copy=False)); break
if c==1 and h in (20,40,80): scores_scales.append(nhwc.astype(np.float32,copy=False)); break
if c==32 and h in (20,40,80): coeff_scales.append(nhwc.astype(np.float32,copy=False)); break
if c==32 and h==160 and w==160: proto = nhwc[0]; break
if len(boxes_scales)==3 and len(scores_scales)==3 and len(coeff_scales)==3 and proto is not None:
boxes_scales.sort(key=lambda a:a.shape[1])
scores_scales.sort(key=lambda a:a.shape[1])
coeff_scales.sort(key=lambda a:a.shape[1])
return boxes_scales, scores_scales, coeff_scales, proto
raise RuntimeError("Failed to assemble heads")
def decode_distribution_boxes(raw_boxes_scales, input_shape, reg_max, strides):
ih, iw = input_shape
all_xywh = []
for t, stride in zip(raw_boxes_scales, strides):
n,h,w,c = t.shape
t = t.reshape(n, h*w, 4, reg_max+1)
prob = softmax(t, axis=-1)
bins = np.arange(reg_max+1, dtype=np.float32)
dist = (prob * bins).sum(axis=-1) * stride
gy = (np.arange(h)+0.5)*stride; gx = (np.arange(w)+0.5)*stride
gx,gy = np.meshgrid(gx,gy)
centers = np.stack([gx.ravel(), gy.ravel(), gx.ravel(), gy.ravel()], axis=1)[None,:,:]
dist = np.concatenate([-dist[:,:,:2], dist[:,:,2:]], axis=-1)
xyxy = centers + dist
cx = (xyxy[:,:,0]+xyxy[:,:,2])*0.5
cy = (xyxy[:,:,1]+xyxy[:,:,3])*0.5
ww = xyxy[:,:,2]-xyxy[:,:,0]
hh = xyxy[:,:,3]-xyxy[:,:,1]
xywh = np.stack([cx,cy,ww,hh], axis=-1)
all_xywh.append(xywh)
return np.concatenate(all_xywh, axis=1)
def process_masks(proto, coeffs, boxes_xyxy, out_shape):
ph,pw,pc = proto.shape
ih,iw = out_shape
proto_flat = proto.reshape(-1, pc).T
masks = sigmoid(coeffs @ proto_flat).reshape(-1, ph, pw)
out = np.empty((masks.shape[0], ih, iw), dtype=np.float32)
for i in range(masks.shape[0]):
out[i] = cv2.resize(masks[i], (iw, ih), interpolation=cv2.INTER_LINEAR)
boxes = boxes_xyxy.round().astype(np.int32)
boxes[:,[0,2]] = np.clip(boxes[:,[0,2]], 0, iw-1)
boxes[:,[1,3]] = np.clip(boxes[:,[1,3]], 0, ih-1)
cropped = np.zeros_like(out)
for i in range(out.shape[0]):
x1,y1,x2,y2 = boxes[i]
cropped[i, y1:y2, x1:x2] = out[i, y1:y2, x1:x2]
return cropped
def postprocess(outputs, input_shape, conf=0.40, iou=0.50, max_det=100, no_nms=False, min_lanes=3, mask_thr=0.50):
ih, iw = input_shape
boxes_scales, scores_scales, coeff_scales, proto = _assemble_heads(outputs)
strides = [ih // a.shape[1] for a in boxes_scales] # 640/80=8, /40=16, /20=32
reg_max = boxes_scales[0].shape[-1] // 4 - 1 # 64 -> 15
decoded_xywh = decode_distribution_boxes(boxes_scales, (ih, iw), reg_max, strides)
scores = [s.reshape(s.shape[0], -1, 1) for s in scores_scales]
scores = np.concatenate(scores, axis=1)
obj = np.ones((scores.shape[0], scores.shape[1], 1), dtype=np.float32)
preds = np.concatenate([decoded_xywh, obj, scores], axis=-1) # (N,Nprop,6)
coeffs = [c.reshape(c.shape[0], -1, 32) for c in coeff_scales]
coeffs = np.concatenate(coeffs, axis=1)
preds = np.concatenate([preds, coeffs], axis=-1) # (N,Nprop,38)
xywh = preds[0,:,:4]
confs = preds[0,:,4] * preds[0,:,5]
keep = confs > conf
if not np.any(keep):
return dict(mask_union=np.zeros((ih,iw),dtype=np.uint8), masks=np.zeros((0,ih,iw),dtype=np.uint8))
xyxy_all = xywh2xyxy(xywh)[keep]
conf_all = confs[keep]
coeff_all = preds[0,keep,6:]
if no_nms:
order = np.argsort(conf_all)[::-1]
sel_idx = order[:max_det]
else:
nms_idx = nms_cpu(xyxy_all, conf_all, iou, max_det)
if nms_idx.size < min_lanes:
order = np.argsort(conf_all)[::-1]
needed = min(min_lanes, xyxy_all.shape[0])
union_idx = list(dict.fromkeys(list(nms_idx) + list(order[:needed])))
sel_idx = np.array(union_idx[:max_det], dtype=np.int64)
else:
sel_idx = nms_idx
xyxy = xyxy_all[sel_idx]
coeff_sel = coeff_all[sel_idx]
masks_f = process_masks(proto.astype(np.float32,copy=False), coeff_sel, xyxy, (ih,iw))
bin_masks = (masks_f > float(mask_thr)).astype(np.uint8)
union = (bin_masks>0).any(axis=0).astype(np.uint8)
return dict(mask_union=union, masks=bin_masks)
def masks_union_to_fullsize(masks_bin, pad, out_shape):
"""
Build a union mask at the original frame size from per-instance masks.
This mirrors the logic used by lane_positions_from_masks, so status and
/lane_mask will always agree.
"""
if not publish_overlay_flag: # <-- add this parameter
return None
import cv2
h0, w0 = out_shape
out = np.zeros((h0, w0), dtype=np.uint8)
if masks_bin is None or not isinstance(masks_bin, np.ndarray) or masks_bin.ndim != 3 or masks_bin.shape[0] == 0:
return out # all zeros
ih, iw = masks_bin.shape[1], masks_bin.shape[2]
top, left = pad
nh = ih - 2 * top
nw = iw - 2 * left
y0, y1 = top, top + nh
x0, x1 = left, left + nw
# clamp just in case
y0 = max(0, min(ih, y0)); y1 = max(0, min(ih, y1))
x0 = max(0, min(iw, x0)); x1 = max(0, min(iw, x1))
if y1 <= y0 or x1 <= x0:
# fallback: resize whole mask
for m in masks_bin:
tmp = cv2.resize(m.astype(np.uint8), (w0, h0), interpolation=cv2.INTER_NEAREST)
out |= (tmp & 1)
return out * 255
# normal path: de-pad then resize each instance, OR into union
for m in masks_bin:
unpadded = m[y0:y1, x0:x1]
if unpadded.shape[:2] != (h0, w0):
unpadded = cv2.resize(unpadded, (w0, h0), interpolation=cv2.INTER_NEAREST)
out |= (unpadded.astype(np.uint8) & 1)
return out * 255 # 0/255
def lane_positions_from_masks(masks_bin, pad, out_wh, yroi, bottom_frac=0.25, min_pixels=1):
if masks_bin.ndim != 3 or masks_bin.shape[0]==0: return []
ih, iw = masks_bin.shape[1], masks_bin.shape[2]
top,left = pad
h0,w0 = out_wh
y0f,y1f = yroi
y0 = int(round(h0*y0f)); y1 = int(round(h0*y1f))
y0 = max(0,min(h0,y0)); y1 = max(0,min(h0,y1))
if y1<=y0: y0,y1 = 0,h0
frac = max(0.02, min(0.50, float(bottom_frac)))
lanes=[]
for m in masks_bin:
unpadded = m[top: ih-top, left: iw-left]
if unpadded.shape[:2] != (h0,w0):
unpadded = cv2.resize(unpadded,(w0,h0),interpolation=cv2.INTER_NEAREST)
found=False
for scale in (1.0,1.5,2.0):
use_frac = min(0.50, frac*scale)
roi_h = y1-y0
ys0 = y0 + int(round((1.0-use_frac)*roi_h))
ys0 = min(ys0, y1-1)
strip = unpadded[ys0:y1,:]
if strip.size==0: continue
colsum = strip.sum(axis=0)
idx = np.where(colsum >= min_pixels)[0]
if idx.size:
w = colsum[idx].astype(np.float32)
x = float((idx*w).sum()/(w.sum()+1e-6))
lanes.append({"x_px":x, "x_norm": x/float(w0)})
found=True; break
if not found:
strip = unpadded[y0:y1,:]
if strip.size:
colsum = strip.sum(axis=0)
idx = np.where(colsum >= min_pixels)[0]
if idx.size:
w = colsum[idx].astype(np.float32)
x = float((idx*w).sum()/(w.sum()+1e-6))
lanes.append({"x_px":x, "x_norm": x/float(w0)})
lanes.sort(key=lambda d:d["x_px"])
return lanes
class LaneEngine:
def __init__(self, hef_path, output_type="FLOAT32"):
self.hailo = HailoInfer(hef_path, batch_size=1, output_type=output_type)
ih, iw, _ = self.hailo.get_input_shape()
self.input_h, self.input_w = ih, iw
self._q = queue.Queue(maxsize=1)
def infer(self, bgr_img):
# preprocess
letter, pad = letterbox_bgr(bgr_img, (self.input_w, self.input_h))
# run async and wait result
def cb(*cb_args, **cb_kwargs):
try:
if cb_kwargs:
completion_info = cb_kwargs.get("completion_info", None)
bindings_list = cb_kwargs.get("bindings_list", None)
else:
completion_info, bindings_list = cb_args[0], cb_args[1]
except Exception:
return
if hasattr(completion_info,"exception") and completion_info.exception:
return
try:
b = bindings_list[0]
names = getattr(b, "_output_names", None)
outs = {}
if names:
for name in names:
arr = b.output(name).get_buffer()
if isinstance(arr,np.ndarray) and arr.ndim==3: arr = arr[None,...]
outs[name]=arr
else:
arr=b.output().get_buffer()
if isinstance(arr,np.ndarray) and arr.ndim==3: arr=arr[None,...]
outs["out0"]=arr
if self._q.full(): self._q.get_nowait()
self._q.put_nowait(outs)
except Exception:
pass
try:
# try kw first, then positional
self.hailo.run([letter], callback=cb)
except TypeError:
self.hailo.run([letter], cb)
t0=time.time()
outputs=None
while outputs is None:
try:
outputs=self._q.get(timeout=0.5)
except queue.Empty:
if time.time()-t0>2.0:
# retry once
try: self.hailo.run([letter], callback=cb)
except TypeError: self.hailo.run([letter], cb)
t0=time.time()
return outputs, pad
def close(self):
self.hailo.close()
#!/usr/bin/env python3
import json
import threading
import numpy as np
import cv2
import rclpy
from rclpy.node import Node
from rclpy.qos import qos_profile_sensor_data
from sensor_msgs.msg import Image
from std_msgs.msg import String
from .lane_core import (
LaneEngine,
postprocess,
masks_union_to_fullsize,
lane_positions_from_masks,
)
class LaneSegNode(Node):
def __init__(self):
super().__init__('lane_seg_node')
# Params
self.net = self.declare_parameter('net', 'lane2.hef').get_parameter_value().string_value
self.input_topic = self.declare_parameter('input_topic', '/image_raw').get_parameter_value().string_value
self.mask_topic = self.declare_parameter('mask_topic', '/lane_mask').get_parameter_value().string_value
self.status_topic = self.declare_parameter('status_topic', '/lane_status').get_parameter_value().string_value
self.overlay_topic = self.declare_parameter('overlay_topic', '/lane_overlay').get_parameter_value().string_value
self.publish_overlay = self.declare_parameter('publish_overlay', False).get_parameter_value().bool_value
self.conf = float(self.declare_parameter('conf', 0.40).get_parameter_value().double_value)
self.nms_iou = float(self.declare_parameter('nms_iou', 0.90).get_parameter_value().double_value)
self.no_nms = bool(self.declare_parameter('no_nms', False).get_parameter_value().bool_value)
self.min_lanes = int(self.declare_parameter('min_lanes', 3).get_parameter_value().integer_value)
self.mask_thr = float(self.declare_parameter('mask_thr', 0.45).get_parameter_value().double_value)
yroi_str = self.declare_parameter('yroi', '0.45,1.0').get_parameter_value().string_value
self.yroi = tuple(map(float, yroi_str.split(',')))
self.bottom_frac = float(self.declare_parameter('bottom_frac', 0.30).get_parameter_value().double_value)
self.min_pix = int(self.declare_parameter('min_pix', 1).get_parameter_value().integer_value)
# Engine
self.engine = LaneEngine(self.net, output_type="FLOAT32")
self.get_logger().info(f"Loaded HEF: {self.net} input {self.engine.input_w}x{self.engine.input_h}")
# ROS I/O
self.sub = self.create_subscription(Image, self.input_topic, self.cb_image, qos_profile_sensor_data)
self.pub_mask = self.create_publisher(Image, self.mask_topic, 10)
self.pub_status = self.create_publisher(String, self.status_topic, 10)
self.pub_overlay = self.create_publisher(Image, self.overlay_topic, 10) if self.publish_overlay else None
self.lock = threading.Lock()
self.frame_id = 0
def _image_to_bgr(self, msg: Image):
enc = (msg.encoding or '').lower()
buf = memoryview(msg.data)
h, w = msg.height, msg.width
if enc == 'bgr8':
return np.frombuffer(buf, np.uint8).reshape(h, w, 3)
if enc == 'rgb8':
arr = np.frombuffer(buf, np.uint8).reshape(h, w, 3)
return arr[:, :, ::-1].copy()
if enc in ('yuv422_yuy2', 'yuyv', 'yuyv422'):
yuyv = np.frombuffer(buf, np.uint8).reshape(h, w, 2)
return cv2.cvtColor(yuyv, cv2.COLOR_YUV2BGR_YUY2)
if enc == 'mono8':
arr = np.frombuffer(buf, np.uint8).reshape(h, w)
return np.stack([arr, arr, arr], axis=-1)
# Fallback: assume at least 3 channels
arr = np.frombuffer(buf, np.uint8).reshape(h, w, -1)
if arr.shape[2] >= 3:
return arr[:, :, :3]
return np.repeat(arr.reshape(h, w, 1), 3, axis=2)
def cb_image(self, msg: Image):
with self.lock:
try:
bgr = self._image_to_bgr(msg)
outputs, pad = self.engine.infer(bgr)
pp = postprocess(
outputs,
(self.engine.input_h, self.engine.input_w),
conf=self.conf, iou=self.nms_iou, max_det=100,
no_nms=self.no_nms, min_lanes=self.min_lanes, mask_thr=self.mask_thr
)
# Build union mask at the ORIGINAL msg size (0/255)
valid_mask = masks_union_to_fullsize(pp["masks"], pad, (msg.height, msg.width)) if self.publish_overlay else None
# Publish mono8 mask
mask_msg = Image()
mask_msg.header = msg.header
mask_msg.height = msg.height
mask_msg.width = msg.width
mask_msg.encoding = 'mono8'
mask_msg.is_bigendian = 0
mask_msg.step = msg.width
mask_msg.data = valid_mask.tobytes()
self.pub_mask.publish(mask_msg)
# Status
lanes = lane_positions_from_masks(
pp['masks'], pad, (msg.height, msg.width),
self.yroi, bottom_frac=self.bottom_frac, min_pixels=self.min_pix
)
s = String()
s.data = json.dumps({
"count": int(len(lanes)),
"lanes_px": [float(d["x_px"]) for d in lanes],
"lanes_norm": [float(d["x_norm"]) for d in lanes]
}, separators=(',', ':'))
self.pub_status.publish(s)
# Optional overlay
if self.publish_overlay and self.pub_overlay:
ov = bgr.copy()
ov[valid_mask > 0] = (255, 128, 0)
overlay_msg = Image()
overlay_msg.header = msg.header
overlay_msg.height = msg.height
overlay_msg.width = msg.width
overlay_msg.encoding = 'bgr8'
overlay_msg.is_bigendian = 0
overlay_msg.step = msg.width * 3
overlay_msg.data = ov.tobytes()
self.pub_overlay.publish(overlay_msg)
# Optional periodic debug
self.frame_id += 1
if self.frame_id % 30 == 0:
nnz = int((valid_mask > 0).sum())
self.get_logger().info(f"mask nnz: {nnz}")
except Exception as e:
# Do not crash the process on a single bad frame
self.get_logger().error(f"cb_image failed: {type(e).__name__}: {e}")
def main():
rclpy.init()
node = LaneSegNode()
try:
rclpy.spin(node)
except KeyboardInterrupt:
pass
finally:
try:
node.engine.close()
except Exception:
pass
node.destroy_node()
if rclpy.ok():
rclpy.shutdown()
if __name__ == "__main__":
main()
Because we are a team and three people have their own detection model developed, we are using roboflow to hand label things, and we couldnt find a way to combine object detection yolov8 model with lane segmentation yolov8_seg model.