@Erez as mentioned here, it seems that you are compiling the model with --performance flag.
The compiler will try several configurations, some of which may not be allocated (that’s why the error), but it will eventually find the right solution. This is a time consuming compilation that you should use only to get the best performance.
To have a faster compilation during the first tests, you can compile without performance mode.
Hi
right now this is the nvidia-smi output
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 36C P0 26W / 70W | 2MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
does this phase use the GPU?
And I want to run it with the performance mode…
I’m not sure what to do with your reply? is it ok? should I do something else? is there a problem with my model?
i ran the same command without the performance flag and I’m able to see processes that using the GPU
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 41C P0 26W / 70W | 147MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 135962 C ...rkspace/hailo_virtualenv/bin/python 142MiB |
+---------------------------------------------------------------------------------------+
@Erez my bad, the command to use to monitor the GPU is nvtop (I corrected the original post).
Optimization phase uses the GPU, while compilation does not.
Regarding performance mode itself, the entire process may take hours. I suggest:
-
Run a first compilation without performance mode and make sure the model compiles… Without performance mode, the compilation will take less time.
-
Once you know the model compiles, run the compilation with performance mode. The DFC will try to allocate the model many times. Some tentatives may fail, but the compilation process will continue with the next iteration.
Here you mentioned:The training is still running. Looks like that
[error] Mapping Failed (Timeout, allocation time: 21m 7s)I assume that with “training” you meant the compilation process. That should be the case: despite the failure, the compilation process should still continue with the next iteration. If you have doubts, please share the full log after the failure
this is the NVtop output

this is the output of the compile process without the --performance flag:
Looks like that it worked correctly!
<Hailo Model Zoo INFO> Start run for network yolov8n ...
<Hailo Model Zoo INFO> Initializing the hailo8 runner...
[info] Translation started on ONNX model yolov8n
[info] Restored ONNX model yolov8n (completion time: 00:00:00.08)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:00.28)
[info] Simplified ONNX model for a parsing retry attempt (completion time: 00:00:00.80)
[info] According to recommendations, retrying parsing with end node names: ['/model.22/Concat_3'].
[info] Translation started on ONNX model yolov8n
[info] Restored ONNX model yolov8n (completion time: 00:00:00.04)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:00.22)
[info] NMS structure of yolov8 (or equivalent architecture) was detected.
[info] In order to use HailoRT post-processing capabilities, these end node names should be used: /model.22/cv2.0/cv2.0.2/Conv /model.22/cv3.0/cv3.0.2/Conv /model.22/cv2.1/cv2.1.2/Conv /model.22/cv3.1/cv3.1.2/Conv /model.22/cv2.2/cv2.2.2/Conv /model.22/cv3.2/cv3.2.2/Conv.
[info] Start nodes mapped from original model: 'images': 'yolov8n/input_layer1'.
[info] End nodes mapped from original model: '/model.22/Concat_3'.
[info] Translation completed on ONNX model yolov8n (completion time: 00:00:00.87)
[info] Translation started on ONNX model yolov8n
[info] Restored ONNX model yolov8n (completion time: 00:00:00.04)
[info] Extracted ONNXRuntime meta-data for Hailo model (completion time: 00:00:00.26)
[info] NMS structure of yolov8 (or equivalent architecture) was detected.
[info] In order to use HailoRT post-processing capabilities, these end node names should be used: /model.22/cv2.0/cv2.0.2/Conv /model.22/cv3.0/cv3.0.2/Conv /model.22/cv2.1/cv2.1.2/Conv /model.22/cv3.1/cv3.1.2/Conv /model.22/cv2.2/cv2.2.2/Conv /model.22/cv3.2/cv3.2.2/Conv.
[info] Start nodes mapped from original model: 'images': 'yolov8n/input_layer1'.
[info] End nodes mapped from original model: '/model.22/cv2.0/cv2.0.2/Conv', '/model.22/cv3.0/cv3.0.2/Conv', '/model.22/cv2.1/cv2.1.2/Conv', '/model.22/cv3.1/cv3.1.2/Conv', '/model.22/cv2.2/cv2.2.2/Conv', '/model.22/cv3.2/cv3.2.2/Conv'.
[info] Translation completed on ONNX model yolov8n (completion time: 00:00:01.11)
[info] Appending model script commands to yolov8n from string
[info] Added nms postprocess command to model script.
[info] Saved HAR to: /local/workspace/yolov8n.har
<Hailo Model Zoo INFO> Preparing calibration data...
[info] Loading model script commands to yolov8n from /local/workspace/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov8n.alls
[info] Loading model script commands to yolov8n from string
[info] Starting Model Optimization
[info] Using default optimization level of 2
[info] Model received quantization params from the hn
[info] MatmulDecompose skipped
[info] Starting Mixed Precision
[info] Model Optimization Algorithm Mixed Precision is done (completion time is 00:00:00.97)
[info] LayerNorm Decomposition skipped
[info] Starting Statistics Collector
[info] Using dataset with 64 entries for calibration
Calibration: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 64/64 [00:34<00:00, 1.84entries/s]
[info] Model Optimization Algorithm Statistics Collector is done (completion time is 00:00:37.77)
[info] Starting Fix zp_comp Encoding
[info] Model Optimization Algorithm Fix zp_comp Encoding is done (completion time is 00:00:00.00)
[info] Matmul Equalization skipped
[info] No shifts available for layer yolov8n/conv60/conv_op, using max shift instead. delta=0.4878
[info] No shifts available for layer yolov8n/conv60/conv_op, using max shift instead. delta=0.2439
[warning] Reducing output bits of yolov8n/conv63 by 6.0 bits (More than half)
[info] Finetune encoding skipped
[info] Bias Correction skipped
[info] Adaround skipped
[info] Starting Quantization-Aware Fine-Tuning
[warning] Dataset is larger than expected size. Increasing the algorithm dataset size might improve the results
[info] Using dataset with 1024 entries for finetune
Epoch 1/4
1/128 [..............................] - ETA: 5:21:32 - total_distill_loss: 1.8694 - _distill_loss_yolov8n/conv41: 0.0937 - _distill_loss_yolov8n/conv42: 0.1283 - _distill_loss_yolov8n/conv52: 0.1109 - _distill_loss_yolov8n/conv53: 0.1843 - _distill_loss_yolov8n/conv62: 0.0538 - _distill_loss_yolov8n/conv63: 0.8238 - _distill_loss_yolov8n/conv35: 0.1064 - _distill 2/128 [..............................] - ETA: 1:25 - total_distill_loss: 2.1331 - _distill_loss_yolov8n/conv41: 0.0834 - _distill_loss_yolov8n/conv42: 0.1281 - _distill_loss_yolov8n/conv52: 0.1330 - _distill_loss_yolov8n/conv53: 0.2078 - _distill_loss_yolov8n/conv62: 0.1663 - _distill_loss_yolov8n/conv63: 0.9119 - _distill_loss_yolov8n/conv35: 0.1065 - _distill_lo
[info] Model Optimization Algorithm Quantization-Aware Fine-Tuning is done (completion time is 00:08:32.55)
[info] Starting Layer Noise Analysis
Full Quant Analysis: 100%|████████████████████████████| 2/2 [02:59<00:00, 89.71s/iterations]
[info] Model Optimization Algorithm Layer Noise Analysis is done (completion time is 00:03:03.60)
[info] Model Optimization is done
[info] Saved HAR to: /local/workspace/yolov8n.har
[info] Loading model script commands to yolov8n from /local/workspace/hailo_model_zoo/hailo_model_zoo/cfg/alls/generic/yolov8n.alls
[info] To achieve optimal performance, set the compiler_optimization_level to "max" by adding performance_param(compiler_optimization_level=max) to the model script. Note that this may increase compilation time.
[info] Loading network parameters
[info] Starting Hailo allocation and compilation flow
[info] Adding an output layer after conv41
[info] Adding an output layer after conv42
[info] Adding an output layer after conv52
[info] Adding an output layer after conv53
[info] Adding an output layer after conv62
[info] Adding an output layer after conv63
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=75%, max_compute_utilization=75%, max_compute_16bit_utilization=75%, max_memory_utilization (weights)=75%, max_input_aligner_utilization=75%, max_apu_utilization=75%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=75%, max_compute_utilization=75%, max_compute_16bit_utilization=75%, max_memory_utilization (weights)=75%, max_input_aligner_utilization=75%, max_apu_utilization=75%
Validating context_0 layer by layer (100%)
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
● Finished
[info] Solving the allocation (Mapping), time per context: 59m 59s
Context:0/0 Iteration 0: Mapping prepost...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost
worker0 * * * * * * * * V
Context:0/0 Iteration 0: Trying parallel splits...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost
worker0
Context:0/0 Iteration 0: Trying parallel splits...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost
worker0
Context:0/0 Iteration 0: Trying parallel splits...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * * * * * *
worker0
Context:0/0 Iteration 0: Trying parallel splits... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * * * * * *
worker0
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * * * * * *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * * * * * *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * * * * * *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * V * * * *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * V * * V *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * * V * * V *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... * * * *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... * V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... * V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost * V V * V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V *
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V * * * * * * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V * * * * V * *
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V * * V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
Context:0/0 Iteration 4: Trying parallel mapping... V V V *
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost V V V V V V V
worker0 * * * * * * * * V V V V V V V V
worker1 V V V V V V V * V it failed: 0
worker2 V V V V V V V V V ster mapping: 0
worker3 V V V V V V V V V -mapping validation: 0
Reverts on split failed: 0
00:05
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 0
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] Iterations: 4
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 1
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] +-----------+---------------------+---------------------+--------------------+
[info] | Cluster | Control Utilization | Compute Utilization | Memory Utilization |
[info] +-----------+---------------------+---------------------+--------------------+
[info] | cluster_0 | 100% | 53.1% | 50.8% |
[info] | cluster_1 | 75% | 42.2% | 25% |
[info] | cluster_2 | 100% | 64.1% | 28.1% |
[info] | cluster_3 | 100% | 40.6% | 36.7% |
[info] | cluster_4 | 100% | 71.9% | 26.6% |
[info] | cluster_5 | 56.3% | 26.6% | 14.8% |
[info] | cluster_6 | 68.8% | 46.9% | 23.4% |
[info] +-----------+---------------------+---------------------+--------------------+
[info] | Total | 75% | 43.2% | 25.7% |
[info] +-----------+---------------------+---------------------+--------------------+
[info] Successful Mapping (allocation time: 29s)
[info] Compiling context_0...
[info] Bandwidth of model inputs: 9.375 Mbps, outputs: 4.29382 Mbps (for a single frame)
[info] Bandwidth of DDR buffers: 0.0 Mbps (for a single frame)
[info] Bandwidth of inter context tensors: 0.0 Mbps (for a single frame)
[info] Building HEF...
[info] Successful Compilation (compilation time: 12s)
[info] Saved HAR to: /local/workspace/yolov8n.har
<Hailo Model Zoo INFO> HEF file written to yolov8n.hef
I’m getting the timeout error for each epoch (3 times, then i stopped the process)
What are the next step? should I ran the command again without the performance step and to see what is the final results?
@Erez to sum up:
- Optimization is now working correctly, with GPU
- Compilation without --performance flag also worked fine
If you want, you can try the performance mode again and let it run until the end. As mentioned before, it is normal to have some failures, since the first iterations are run with higher resources utilization level (see your picture above), leaving little margin to interconnect the layers.
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=120%, max_compute_utilization=100%, max_compute_16bit_utilization=100%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=100%, max_apu_utilization=100%
Eventually, the compilation will succeed with lower utilization levels.
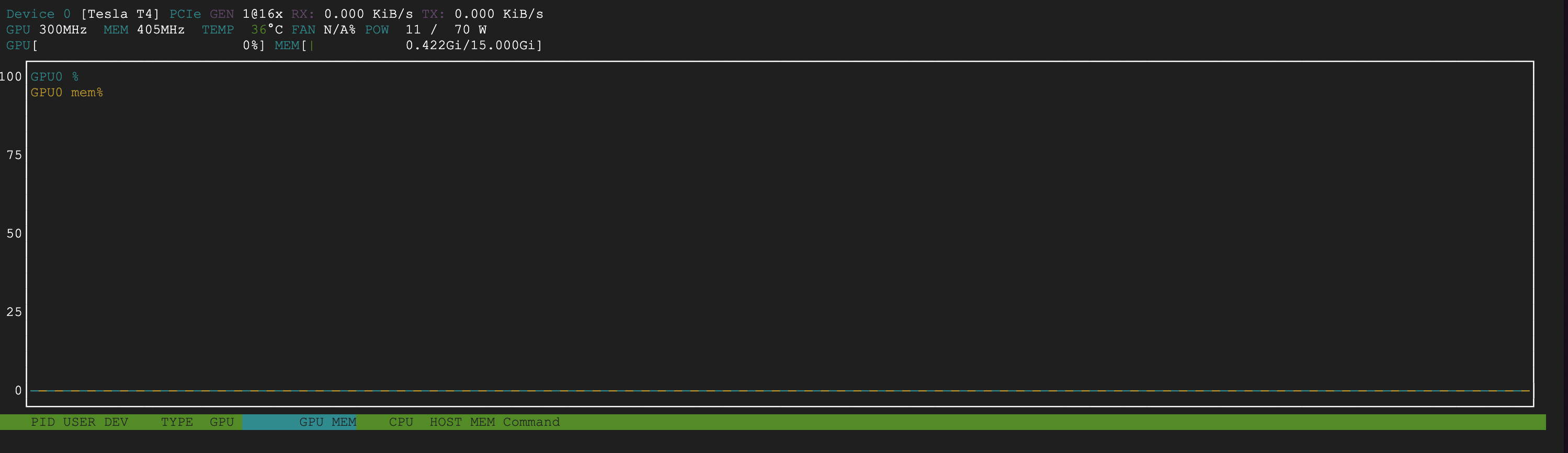
Looks like that the gpu is not working at all during this phase:
In addition, The process is running for 2 hours… still have timeouts after 20 mins over and over again.
Something here is not right, Am I missing something?
@Erez, as mentioned in one of my posts above:
Optimization phase uses the GPU, while compilation does not.
Regarding the performance mode compilation:
In addition, The process is running for 2 hours… still have timeouts after 20 mins over and over again.
Something here is not right, Am I missing something?
Please let the compilation finish, it is a long process.
Thank you!
it was ended
this is the bottom of the log:
[info] Iterations: 4
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 2
Reverts on pre-mapping validation: 1
Reverts on split failed: 0
[error] Mapping Failed (Timeout, allocation time: 16m 32s)
[info] Running Auto-Merger
[info] Auto-Merger is done
[info] Running Auto-Merger
[info] Auto-Merger is done
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=97.5%, max_compute_utilization=97.5%, max_compute_16bit_utilization=97.5%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=97.5%, max_apu_utilization=97.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=97.5%, max_compute_utilization=97.5%, max_compute_16bit_utilization=97.5%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=97.5%, max_apu_utilization=97.5%
Validating context_0 layer by layer (100%)
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
● Finished_shortcut_conv37_to_conv39v38_sd0-1s
[info] Solving the allocation (Mapping), time per context: 9m 59s
Context:0/0 Iteration 4: Trying parallel mapping...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost
worker0 * * * * * * * * V
worker1 V V X V V V V V V
worker2
worker3
17:32
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 0
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] Iterations: 4
Reverts on cluster mapping: 1
Reverts on inter-cluster connectivity: 1
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[error] Mapping Failed (Timeout, allocation time: 18m 4s)
[info] Running Auto-Merger
[info] Auto-Merger is done
[info] Running Auto-Merger
[info] Auto-Merger is done
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=95%, max_compute_utilization=95%, max_compute_16bit_utilization=95%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=95%, max_apu_utilization=95%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=95%, max_compute_utilization=95%, max_compute_16bit_utilization=95%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=95%, max_apu_utilization=95%
Validating context_0 layer by layer (100%)
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
+ + + + + + + + + + + + + + + + + + + +
● Finished0shortcut_conv4_to_conv5onv38_sd0-1s
[info] Solving the allocation (Mapping), time per context: 9m 59s
Context:0/0 Iteration 0: Trying parallel splits...
cluster_0 cluster_1 cluster_2 cluster_3 cluster_4 cluster_5 cluster_6 cluster_7 prepost
worker0
worker1
worker2
worker3 V V V V V V V V V
00:23
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 0
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] Iterations: 4
Reverts on cluster mapping: 0
Reverts on inter-cluster connectivity: 0
Reverts on pre-mapping validation: 0
Reverts on split failed: 0
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=92.5%, max_compute_utilization=92.5%, max_compute_16bit_utilization=92.5%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=92.5%, max_apu_utilization=92.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=92.5%, max_compute_utilization=92.5%, max_compute_16bit_utilization=92.5%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=92.5%, max_apu_utilization=92.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=90%, max_compute_utilization=90%, max_compute_16bit_utilization=90%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=90%, max_apu_utilization=90%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=90%, max_compute_utilization=90%, max_compute_16bit_utilization=90%, max_memory_utilization (weights)=90%, max_input_aligner_utilization=90%, max_apu_utilization=90%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=87.5%, max_compute_utilization=87.5%, max_compute_16bit_utilization=87.5%, max_memory_utilization (weights)=87.5%, max_input_aligner_utilization=87.5%, max_apu_utilization=87.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=87.5%, max_compute_utilization=87.5%, max_compute_16bit_utilization=87.5%, max_memory_utilization (weights)=87.5%, max_input_aligner_utilization=87.5%, max_apu_utilization=87.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=85%, max_compute_utilization=85%, max_compute_16bit_utilization=85%, max_memory_utilization (weights)=85%, max_input_aligner_utilization=85%, max_apu_utilization=85%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=85%, max_compute_utilization=85%, max_compute_16bit_utilization=85%, max_memory_utilization (weights)=85%, max_input_aligner_utilization=85%, max_apu_utilization=85%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=82.5%, max_compute_utilization=82.5%, max_compute_16bit_utilization=82.5%, max_memory_utilization (weights)=82.5%, max_input_aligner_utilization=82.5%, max_apu_utilization=82.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=82.5%, max_compute_utilization=82.5%, max_compute_16bit_utilization=82.5%, max_memory_utilization (weights)=82.5%, max_input_aligner_utilization=82.5%, max_apu_utilization=82.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=80%, max_compute_utilization=80%, max_compute_16bit_utilization=80%, max_memory_utilization (weights)=80%, max_input_aligner_utilization=80%, max_apu_utilization=80%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=80%, max_compute_utilization=80%, max_compute_16bit_utilization=80%, max_memory_utilization (weights)=80%, max_input_aligner_utilization=80%, max_apu_utilization=80%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=77.5%, max_compute_utilization=77.5%, max_compute_16bit_utilization=77.5%, max_memory_utilization (weights)=77.5%, max_input_aligner_utilization=77.5%, max_apu_utilization=77.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=77.5%, max_compute_utilization=77.5%, max_compute_16bit_utilization=77.5%, max_memory_utilization (weights)=77.5%, max_input_aligner_utilization=77.5%, max_apu_utilization=77.5%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=75%, max_compute_utilization=75%, max_compute_16bit_utilization=75%, max_memory_utilization (weights)=75%, max_input_aligner_utilization=75%, max_apu_utilization=75%
[info] Using Single-context flow
[info] Resources optimization guidelines: Strategy -> GREEDY Objective -> MAX_FPS
[info] Resources optimization params: max_control_utilization=75%, max_compute_utilization=75%, max_compute_16bit_utilization=75%, max_memory_utilization (weights)=75%, max_input_aligner_utilization=75%, max_apu_utilization=75%
[info] +-----------+---------------------+---------------------+--------------------+
[info] | Cluster | Control Utilization | Compute Utilization | Memory Utilization |
[info] +-----------+---------------------+---------------------+--------------------+
[info] | cluster_0 | 100% | 64.1% | 45.3% |
[info] | cluster_1 | 93.8% | 50% | 55.5% |
[info] | cluster_2 | 87.5% | 81.3% | 47.7% |
[info] | cluster_3 | 75% | 89.1% | 38.3% |
[info] | cluster_4 | 100% | 78.1% | 50.8% |
[info] | cluster_5 | 100% | 92.2% | 36.7% |
[info] | cluster_6 | 100% | 76.6% | 32.8% |
[info] | cluster_7 | 100% | 71.9% | 39.1% |
[info] +-----------+---------------------+---------------------+--------------------+
[info] | Total | 94.5% | 75.4% | 43.3% |
[info] +-----------+---------------------+---------------------+--------------------+
[info] Successful Mapping (allocation time: 17s)
[info] Compiling context_0...
[info] Bandwidth of model inputs: 9.375 Mbps, outputs: 4.29382 Mbps (for a single frame)
[info] Bandwidth of DDR buffers: 0.0 Mbps (for a single frame)
[info] Bandwidth of inter context tensors: 0.0 Mbps (for a single frame)
[info] Building HEF...
[info] Successful Compilation (compilation time: 7s)
[info] Saved HAR to: /local/workspace/yolov8n.har
<Hailo Model Zoo INFO> HEF file written to yolov8n.hef
Can you verify that it’s completed successfully?
Thanks for your help!
@Erez yes, the model was compiled successfully.
In the log, you can see that the compiler many different configurations, in order to find the best solution.
Thanks a lot! I must to admit that I got today a great help by you.
I’ve 2 recommendations for you:
- The logs can be soften a little bit and to write info message instead of errors.
- I would skip the GPU verification in the bash script or adding additional parameter to attach any GPU available.
@Erez Thanks for your feedback.
Unfortunately, the presence of a valid GPU must be verified, to avoid issues in case the GPU is not present at all or not valid. The check in docker run script will be enhanced to take care of Nvidia GPUs that appear as “3D controller”
1 Like