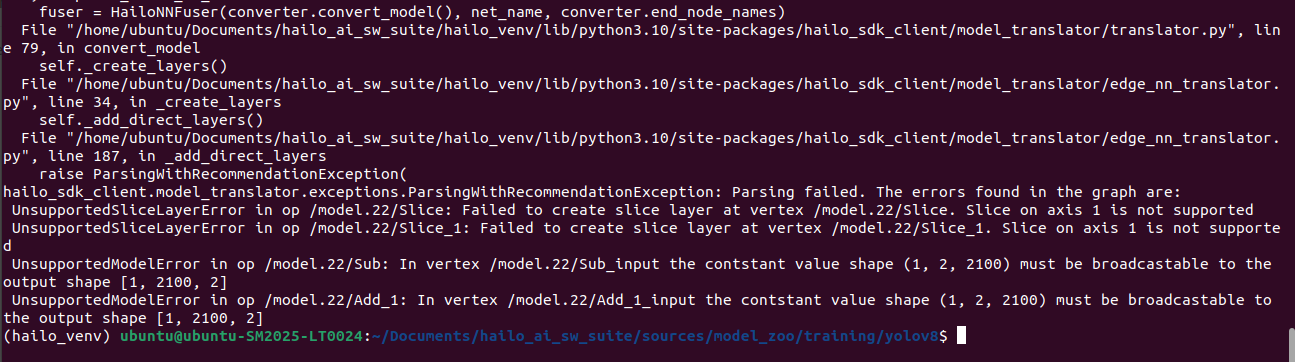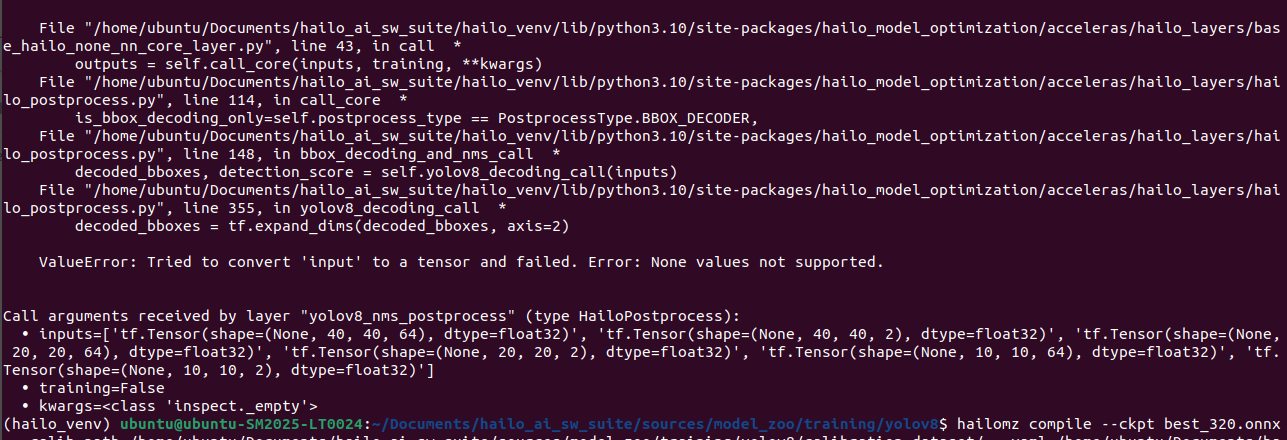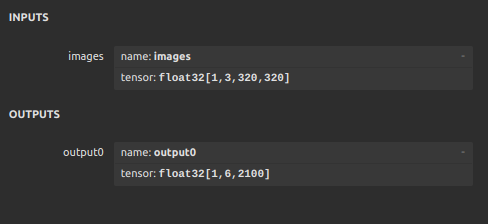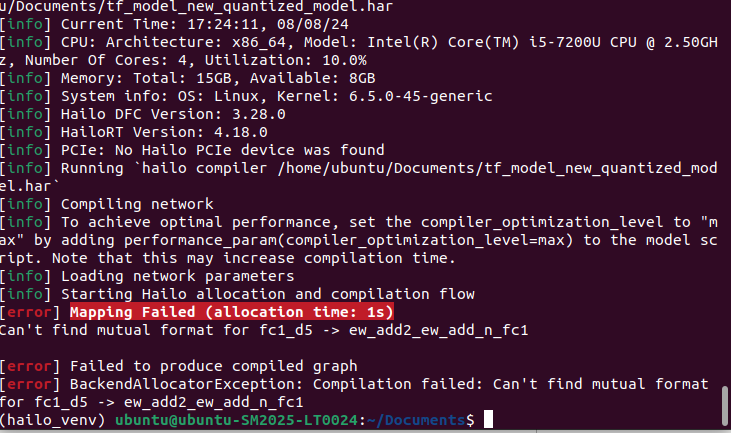
i have followed the below steps
Step1: Training,I have trained my custom dataset and obtained tensorflow model(.h5).Then i converted .h5 to .tflite (without quantization).
This is the training code which i have used,
import os
import numpy as np
import xml.etree.ElementTree as ET
from PIL import Image
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, BatchNormalization, ReLU, MaxPooling2D, Flatten, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
Define image size
IMAGE_SIZE = (320, 320)
def parse_annotation(xml_path):
# Parse XML file to extract annotations
tree = ET.parse(xml_path)
root = tree.getroot()
for obj in root.findall(‘object’):
# Extract class label
class_name = obj.find(‘name’).text
if class_name == ‘person’:
return 1 # Person is present
return 0 # Person is not present
def preprocess_image(image_path):
# Preprocess image: resize and normalize
img = Image.open(image_path).convert(‘RGB’)
img = img.resize(IMAGE_SIZE)
img_array = np.array(img) / 255.0
return img_array
def load_data(image_dir, annotation_dir):
image_files = [f for f in os.listdir(image_dir) if f.endswith(‘.jpg’)]
X, y = ,
for image_file in image_files:
img_path = os.path.join(image_dir, image_file)
xml_path = os.path.join(annotation_dir, image_file.replace('.jpg', '.xml'))
if not os.path.exists(xml_path):
continue
img_array = preprocess_image(img_path)
label = parse_annotation(xml_path)
X.append(img_array)
y.append(label)
X = np.array(X, dtype=np.float32) # Ensure data type consistency
y = np.array(y, dtype=np.float32)
return X, y
Define the model
def create_model():
model = Sequential()
# Add Conv2D layer with batch normalization
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(320, 320, 3), dtype=tf.float32))
model.add(BatchNormalization(dtype=tf.float32))
model.add(ReLU())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), padding='same', dtype=tf.float32))
model.add(BatchNormalization(dtype=tf.float32))
model.add(ReLU())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, dtype=tf.float32))
model.add(BatchNormalization(dtype=tf.float32))
model.add(ReLU())
model.add(Dense(1, activation='sigmoid', dtype=tf.float32)) # Single output for binary classification
return model
Load and preprocess data
image_directory = ‘/home/ubuntu/Downloads/Dataset/person’
annotation_directory = ‘/home/ubuntu/Downloads/Dataset/annotations’
X, y = load_data(image_directory, annotation_directory)
Check if data is loaded correctly
if len(X) == 0 or len(y) == 0:
print(“No data found. Please check your directories and annotations.”)
else:
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.1, random_state=42)
# Compile and train the model
model = create_model()
model.compile(optimizer=Adam(), loss='binary_crossentropy', metrics=['accuracy'])
model.fit(
X_train, y_train,
epochs=10,
validation_data=(X_val, y_val)
)
# Save the model
model.save('/home/ubuntu/Downloads/tf_model_new.h5')
print("Model training and saving completed successfully.")
After training using above code,i have converted .h5 to .tflite
using below code
import os
import tensorflow as tf
Load the trained model
model = tf.keras.models.load_model(‘/home/ubuntu/Downloads/tf_model_new.h5’)
Ensure all layers use float32
for layer in model.layers:
if hasattr(layer, ‘dtype’):
layer._dtype = tf.float32
Convert the model to TensorFlow Lite format without quantization
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.target_spec.supported_types = [tf.float32] # Ensure float32 is used
tflite_model = converter.convert()
Save the TFLite model
tflite_model_path = ‘/home/ubuntu/Downloads/tf_model_new.tflite’
with open(tflite_model_path, ‘wb’) as f:
f.write(tflite_model)
print(f"TFLite model saved at: {tflite_model_path}")
The training part and conversion from .h5 to .tflite i have done in different environment not hailo environment
step2: I am using ubuntu