What are differences between Hailo-8 and Hailo-8L?
Actually, I can find TOPS information only. (26 vs. 13)
Are there any details about chipset specifications such as tensor core counts, memory size and core clocks?
And they seem to use different compiled hef binaries for same models, hef binaries are not compatible each other even though the model has same parameter size like the following.
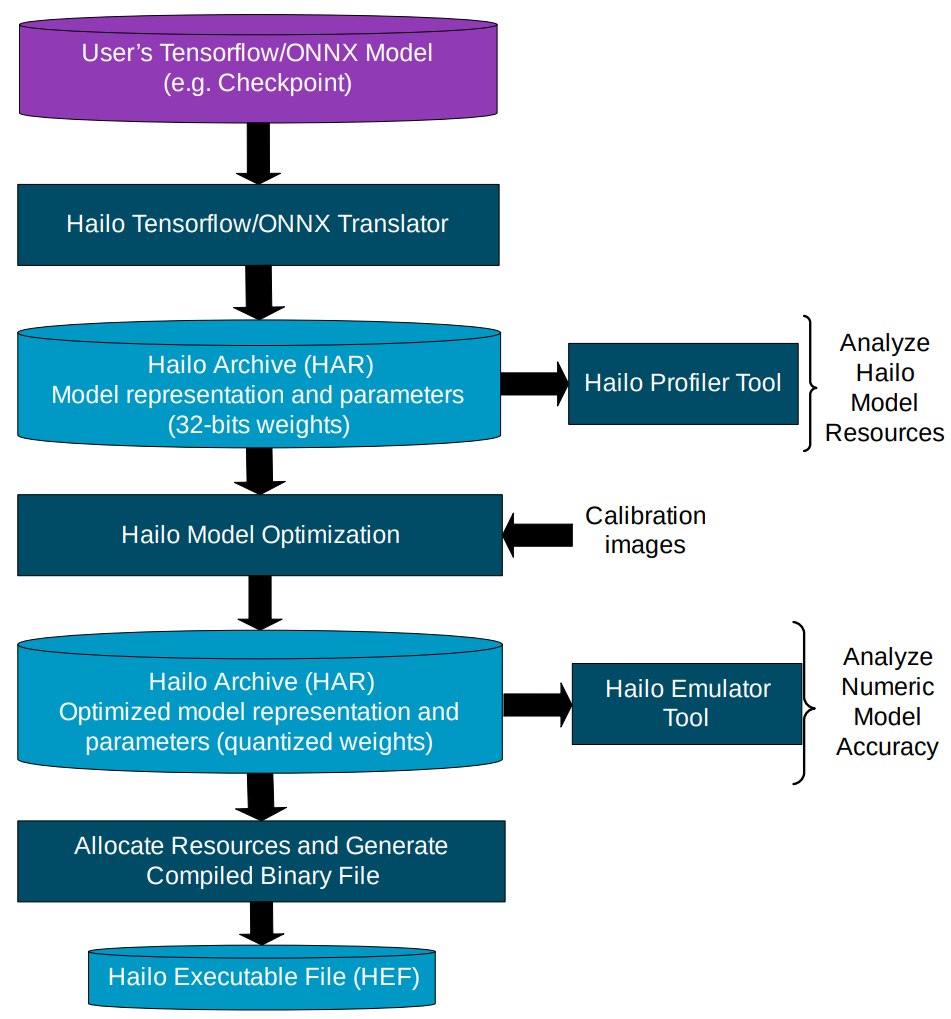
So, do we need to do separate whole “model build process” for each arch if we build models or only need to do “Allocate Resources and Generate Compiled Binary File” step in “model build process” flow?
And Is there easy way to convert hef files from Hailo-8 to Hailo-8L?
The Hailo-8L has half the resources of the Hailo-8. Otherwise it runs at the same speed. The Hailo-8L modules are available as M.2 key B+M and A+E which both have 2 PCIe lanes while the Hailo-8 additionally is available as M.2 key M with 4 PCIe lanes.
In your conversion script you only need to change the architecture flag to hailo8l.
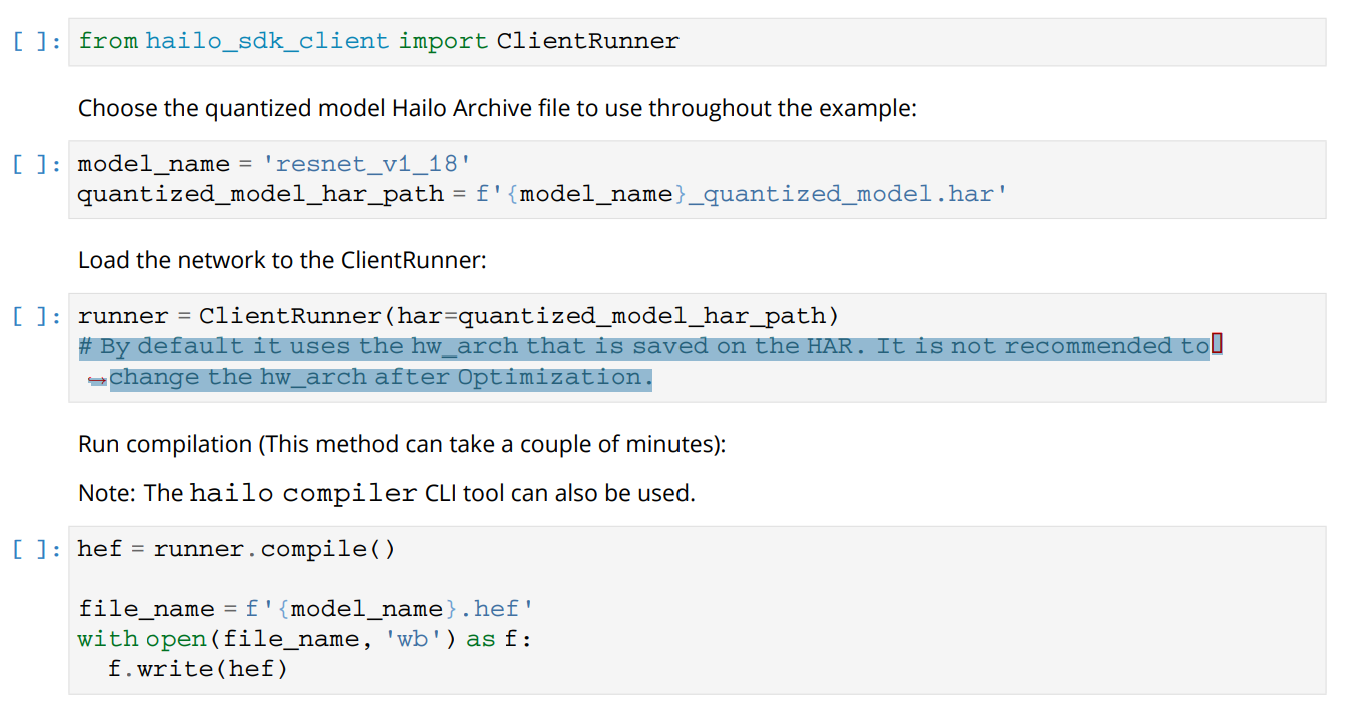
But I can see it is not recommended to change the hw_arch after Optimization in “4.4.1. Hailo Compilation Example from Hailo Archive Quantized Model to HEF” section of “Hailo Dataflow Compiler User Guide” as you see below picture.