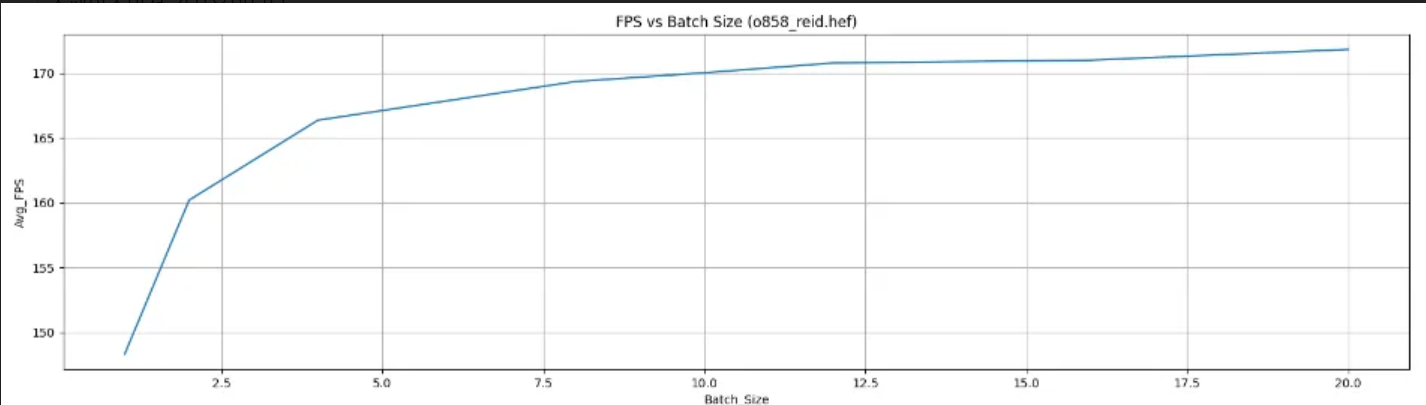
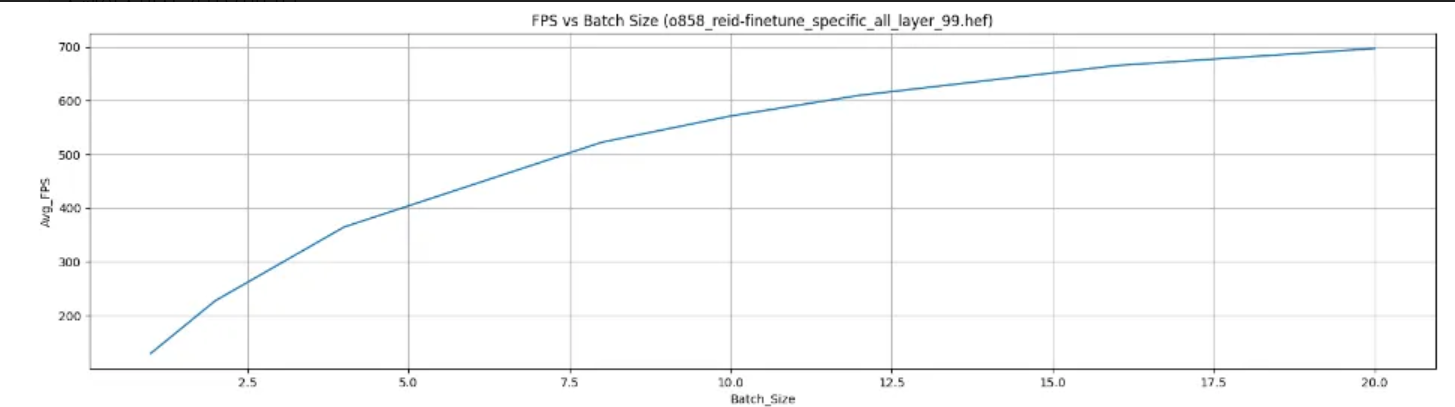
The two HEF models attached below have the same ONNX model, but different optimization model scripts.
However, as shown in the plots below, when varying the input batch size using a Python SDK, the FPS speed patterns differ.
The first model does not significantly increase in speed with larger batch sizes, whereas the second model experiences a substantial speed increase as the batch size grows.
Could you explain the potential reasons for this difference?
Hi @roiyim,
Using batch size will speed up the model in case it’s complied in multiple contexts - a situation where the model is too large to fit the Hailo8 resources as a whole, so the model is “broken down” into several contexts so that only one contexts is loaded to the device each time, while the other wait on the host platform’s memory.
It might be that the higher optimization level also includes higher 4-bit compression and therefore have one of the models is compiled into single context\less contexts than the other one? this can explain why for one model using batch size is more significant.