I trained a custom YOLO model for small object detection. On my NVIDIA 4060 it achieves good accuracy and fast inference, but after converting it to .HEF format, performance drops to a maximum of 14 FPS on the HAILO-8L device.
To maintain accuracy on small objects, the model relies on larger tensors with bigger spatial dimensions, which I suspect may be exceeding the HAILO memory limits.
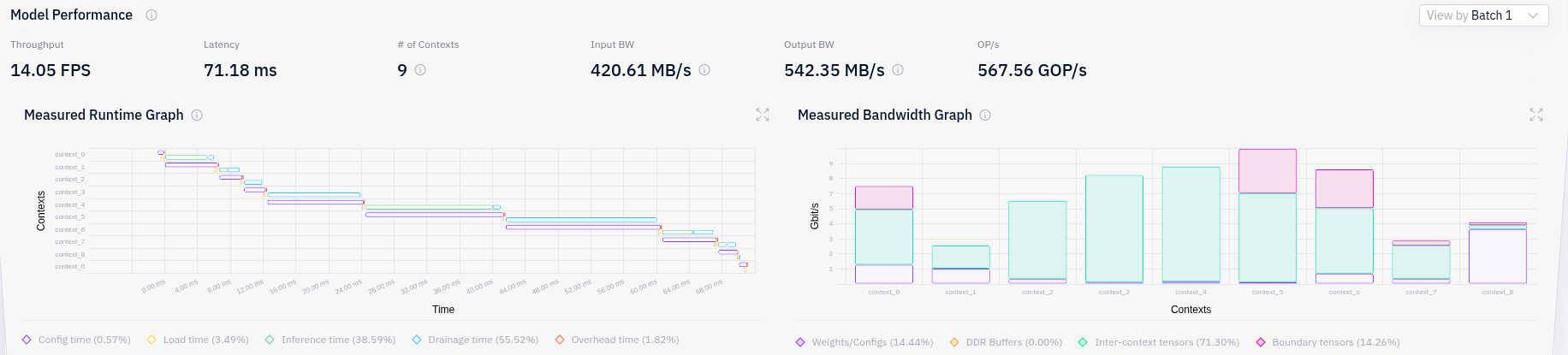
Below is some information from the Hailo Profiler report:
Additionally, I recommend having a look at the YOLO models in the Model Zoo to compare accuracy and performance on the Hailo-8L. You may need to chose another model variant.
You will have some additional performance degradation because of the single PCIe lane on the Raspberry Pi (see forum post mentioned above).
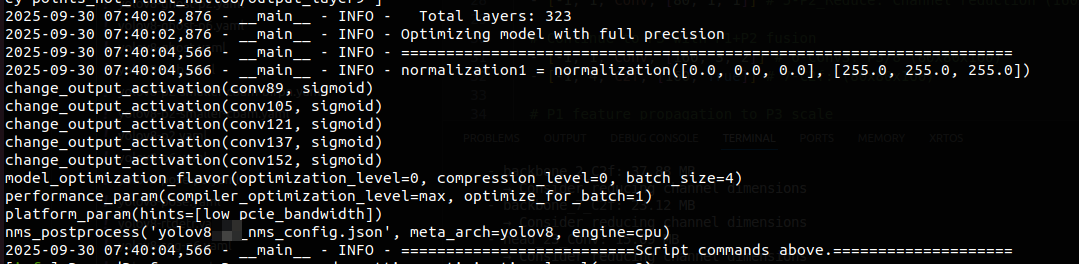
The Hailo Dataflow Compiler has a performance mode in which the compiler will try as hard as it can to find a solution with the highest performance. See Hailo Dataflow Compiler User Guide. This will take significantly longer time to complete. It will not be able to compile your model into a single context on Hailo-8L. Your profiler report shows 274 layers.
You can also try to compile your model for Hailo-8. That should allow you to run your model faster because you will reduce the context switch overhead by compiling to fewer contexts. However it needs a Hailo-8 device to run.
 Background
Background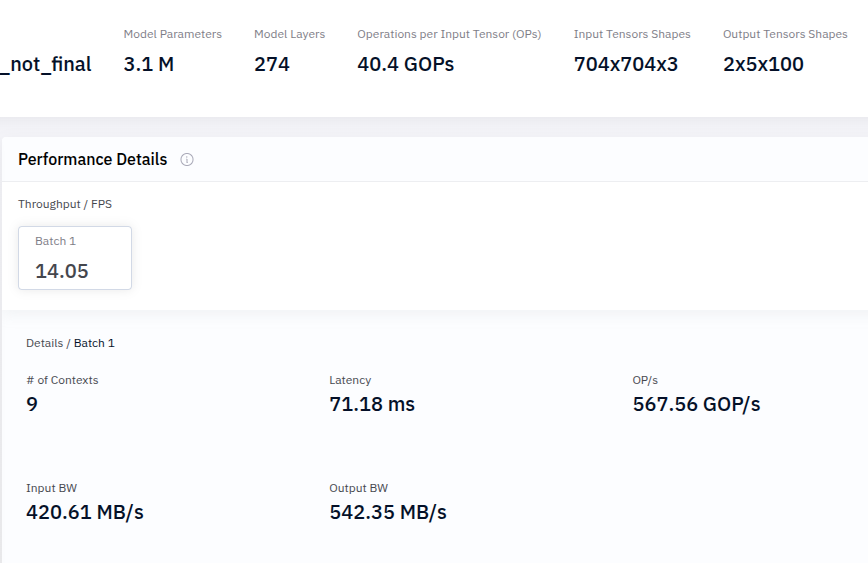
 Questions
Questions