Hello,
Thank you for the response, here’s my end to end process. Here’s the link the the model I want to use: PaddleOCR. Reason for choosing this specific OCR model, performs well on blurry and non-blurry images and has a very high accuracy. This is all done on google colab, more info on how I compiled it can be found here, I believe the main places of error could be
- Step 6: The end nodes or net_input_shapes when converting to ONNX.
- Step 7: Generating a calibration dataset, my .alls script, and lack of nms_config? Not sure if the post process is needed for PaddleOCR.
- For my .alls commands, I ran into a lot of issues with all of the avgpooling layers like:
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool1, division_factors=[2, 2]), adding this line solved enabled the optimization step to move forward, but I’m not sure if that is the right way to solve the warnings that I got, which were just that the values lied outside the expected range.
- The calibration dataset is a little confusing to me, should the calibration dataset be on the same images as the dataset used to train PaddleOCR?
- If I didn’t normalize the dataset beforehand (values lie between 0-255), do I have to specify
normalization = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])in the .alls script? - Vice versa, if I normalized it beforehand (values lie between 0-1), what do I do here for the .alls?
Step 1 - Installing Packages:
!pip install paddleocr paddle2onnx colorama ffmpeg-python paddlepaddle
Step 2 - Exporting PaddleOCR to ONNX for conversion:
from paddleocr import PaddleOCR
ocr = PaddleOCR()
!paddle2onnx \
--model_dir /root/.paddleocr/whl/det/ch/ch_PP-OCRv4_det_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file /content/ch_PP-OCRv4_det.onnx
Step 3 - Updating all packages and venv for the DFC:
!sudo apt-get update
!sudo apt-get install -y python3-dev python3-distutils python3-tk libfuse2 graphviz libgraphviz-dev
!pip install --upgrade pip virtualenv
!sudo apt install python3.10
!sudo apt install python3.10-venv
!python3.10 -m venv my_env
Step 4 - Installing the DFC 3.29.0:
#Installing the WHL file for Hailo DFC
# Just saved it to my gdrive
!gdown 15ORXdfAgFgN6TloxGxO_ClR_ZNoe6lwX
!my_env/bin/pip install /content/hailo_dataflow_compiler-3.29.0-py3-none-linux_x86_64.whl
Step 5 - Reverting CUDA drivers to 11.8 since it doesn’t work with 12.2:
Pretty long process, can add if needed
Step 6 - Translation Scripts:
with open("translate_model.py", "w") as f:
f.write("""
from hailo_sdk_client import ClientRunner
# Define the ONNX model path and configuration
onnx_path = "/content/ch_PP-OCRv4_det.onnx"
onnx_model_name = "paddleOCR_renamed"
chosen_hw_arch = "hailo8" # Specify the target hardware architecture
# Initialize the ClientRunner
runner = ClientRunner(hw_arch=chosen_hw_arch)
#For paddle overwrite
net_input_shapes = {
"x": [16, 3, 640, 640] # Replace dimensions if necessary for your model
}
end_node_names = [
"sigmoid_0.tmp_0"
]
try:
# Translate the ONNX model to Hailo's format
hn, npz = runner.translate_onnx_model(
onnx_path,
onnx_model_name,
end_node_names=end_node_names,
net_input_shapes=net_input_shapes, # Adjust input shapes if needed
)
print("Model translation successful.")
except Exception as e:
print(f"Error during model translation: {e}")
raise
# Save the Hailo model HAR file
hailo_model_har_name = f"{onnx_model_name}_hailo_model.har"
try:
runner.save_har(hailo_model_har_name)
print(f"HAR file saved as: {hailo_model_har_name}")
except Exception as e:
print(f"Error saving HAR file: {e}")
""")
Then running it in the venv:
!my_env/bin/python translate_model.py
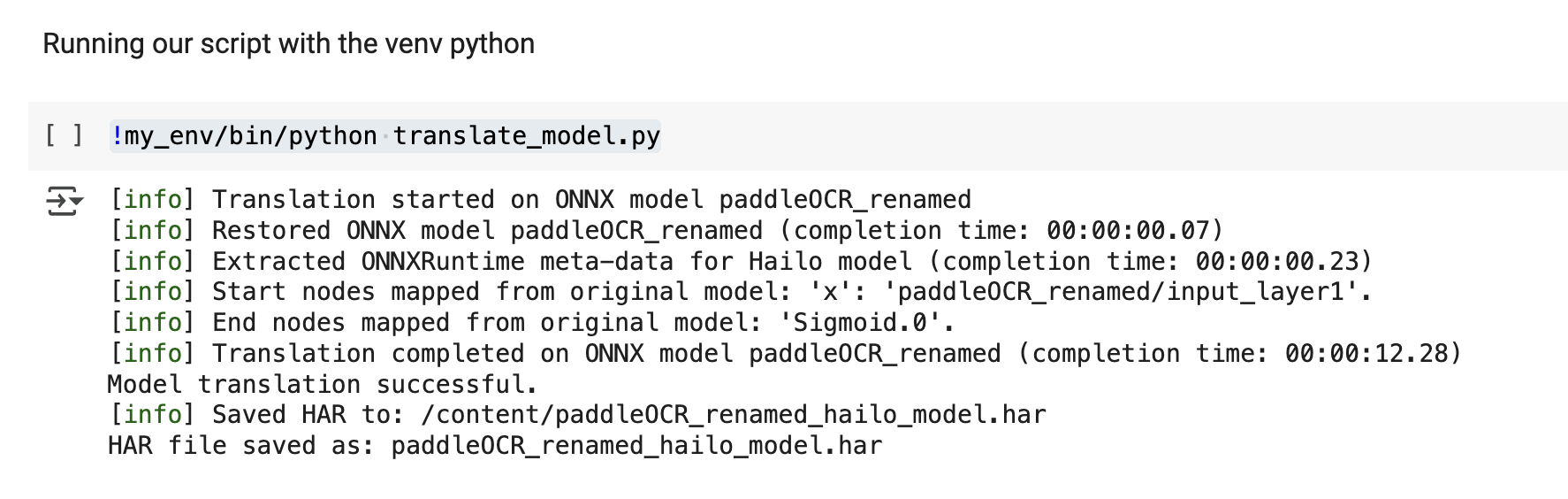
Step 7 - Optimizing script:
with open("optimize_model.py", "w") as f:
f.write("""
import os
from hailo_sdk_client import ClientRunner
# Define your model's HAR file name
model_name = "paddleOCR_renamed"
hailo_model_har_name = f"{model_name}_hailo_model.har"
# Ensure the HAR file exists
assert os.path.isfile(hailo_model_har_name), "Please provide a valid path for the HAR file"
# Initialize the ClientRunner with the HAR file
runner = ClientRunner(har=hailo_model_har_name)
# Define the model script to reduce global average pooling spatial dimensions
model_script = \"\"\"
normalization = normalization([0.0, 0.0, 0.0], [255.0, 255.0, 255.0])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool1, division_factors=[2, 2])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool2, division_factors=[2, 2])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool9, division_factors=[2, 2])
pre_quantization_optimization(global_avgpool_reduction, layers=avgpool10, division_factors=[4, 4])
performance_param(compiler_optimization_level=max)
\"\"\"
# Load the model script into the ClientRunner
runner.load_model_script(model_script)
# Define a calibration dataset
# Replace '/content/processed_calibration_data.npy' with your actual dataset path
calib_dataset = "/content/paddleocr_calibration_data_1024_255.npy"
assert os.path.exists(calib_dataset), "Calibration dataset not found!"
# Perform optimization with the calibration dataset
runner.optimize(calib_dataset)
# Save the optimized model to a new Quantized HAR file
quantized_model_har_path = f"{model_name}_quantized_model.har"
runner.save_har(quantized_model_har_path)
print(f"Quantized HAR file saved to: {quantized_model_har_path}")
""")
Then running it:
!my_env/bin/python optimize_model.py
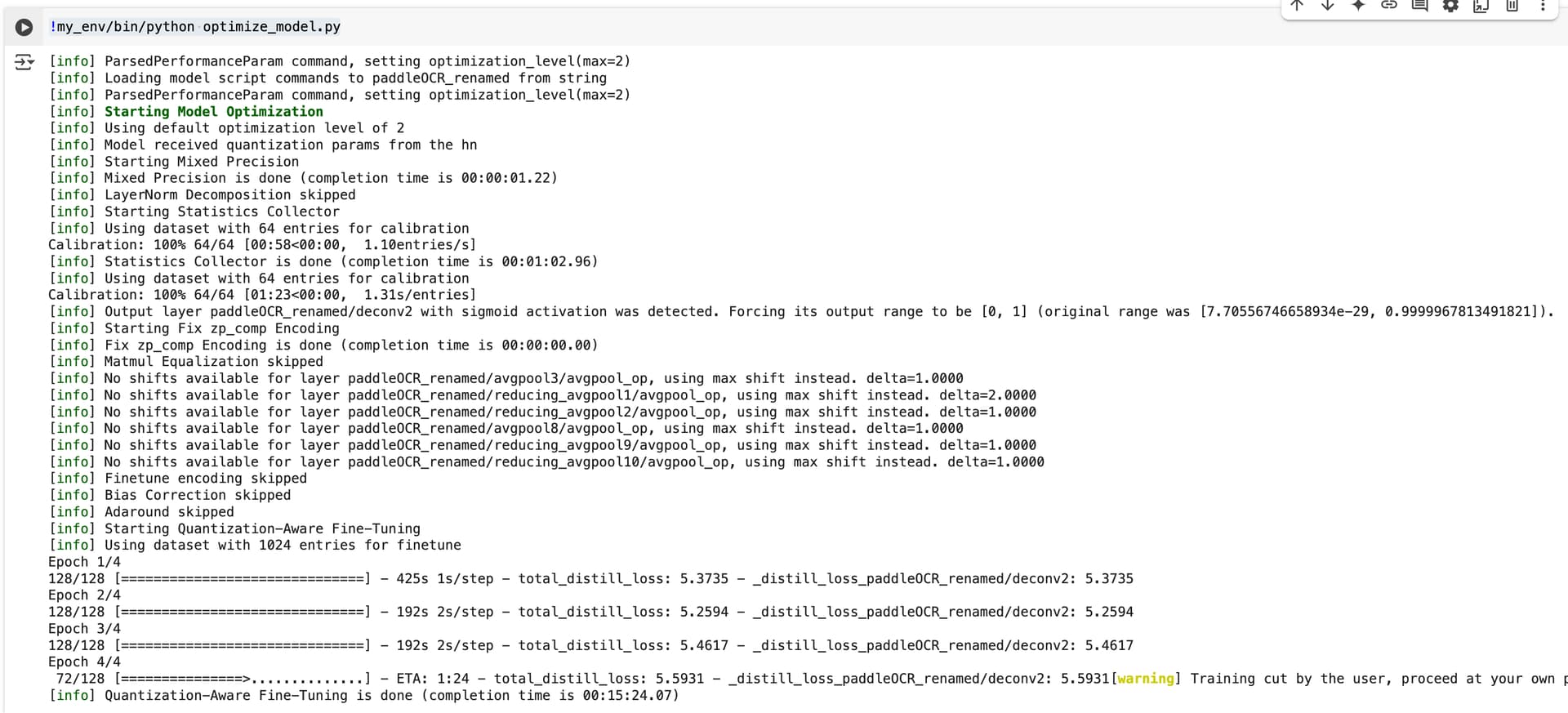
Step 8 - Compilation:
with open("compile_model.py", "w") as f:
f.write("""
from hailo_sdk_client import ClientRunner
import os
# Define the quantized model HAR file
model_name = "paddleOCR_renamed"
quantized_model_har_path = f"{model_name}_quantized_model.har"
output_directory = "/content/paddle_output"
os.makedirs(output_directory, exist_ok=True)
# Initialize the ClientRunner with the HAR file
runner = ClientRunner(har=quantized_model_har_path)
print("[info] ClientRunner initialized successfully.")
# Compile the model
try:
hef = runner.compile()
print("[info] Compilation completed successfully.")
except Exception as e:
print(f"[error] Failed to compile the model: {e}")
raise
# Save the compiled model to the specified directory
output_file_path = os.path.join(output_directory, f"{model_name}.hef")
with open(output_file_path, "wb") as f:
f.write(hef)
print(f"[info] Compiled model saved successfully to {output_file_path}")
""")
This process completes just fine, just takes a super long time (overnight on a T4 GPU) to compile. Keeps iterating through a “multi-context” flow several times, then eventually compiles into a .hef.
Sorry about the long response, let me know if I can provide anything else, would love your feedback!