Hello Hailo Community
Please can someone help me understand what I may be doing wrong when using activation_clipping as a pre_quantization_optimization() step during model optimization. My model optimization script is
model_optimization_flavor(optimization_level=2, compression_level=0, batch_size=1)
pre_quantization_optimization(global_avgpool_reduction, layers=[avgpool1, avgpool2, avgpool3 ], division_factors=[5, 5])
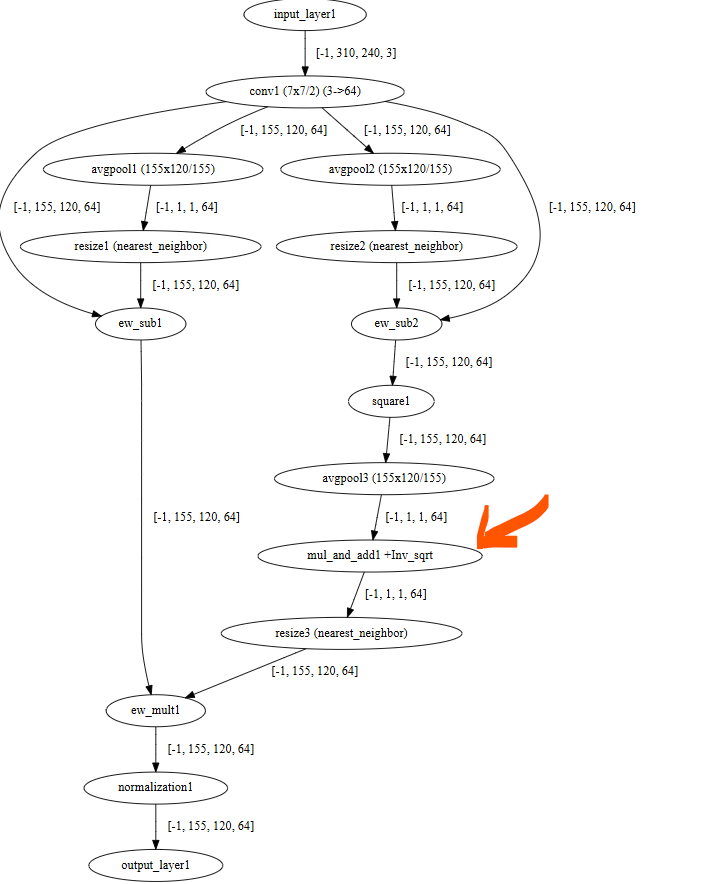
pre_quantization_optimization(activation_clipping, layers=[small/mul_and_add1],mode=manual, clipping_values=[0.71, 5.0])
From what I can see no clipping appears to occur. (I am unsure if the layer name should include the full name small/mul_and_add1 or just the layer name mul_and_add1 . I tried both but don’t see any change in behavior)
Background to my question:
I ended up trying activation_clipping as an outcome of an analysis to improve our custom model’s performance when quantized compared to the original non quantized versions. I am using V3.31 of the dataflow compiler and followed all the detailed recommendations in the Hailo Dataflow Compiler user guide, including sections 4.3.2 In-depth Optimization tutorial and section" 5.3 Model optimizations. The model was developed and trained using pytorch, converted to onnx, parsed into a .har file and optimized as shown in the tutorial. The onnx and har versions are compared to the original pytorch model. The har models are tested using a ClientRunner() using SDK_NATIVE, SDK_FP_OPTIMIZED and finally SDK_QUANTIZED contexts. The onnx, native and FP_Optimized all pass the tests perfectly when compared to the original pytorch, but the quantized version fails miserably.
I tried all levels of optimization_level, going all the way to optimization_level=4. Then tried the analyze_noise API described in section 4.6.2 of the guide. This is a very cool tool. Kudos to the development team for the tool that provides great insight into model behavior.
Visualizing the output from the analysis tool, it became apparent that quantization of the mul_and_add1 layer part of our modified batch normalization layer is problematic with a very low SNR

This layer is a modification of the BatchNorm2D pytorch module. It implements the same normalization, but instead of having fixed means and variances at run time these are computed from the layer input, that is the same behavior as during training. The issue occurs when the channel wise data is near constant resulting in a variance that tends to zero. The small epsilon ensures a finite denominator. In floating point when numerator is zero and denominator small it is well behaved, but breaks down when the layer is quantized. This can be seen in the tool’s scatter plot for the layer where there are significant outlier values (point on the extreme right).
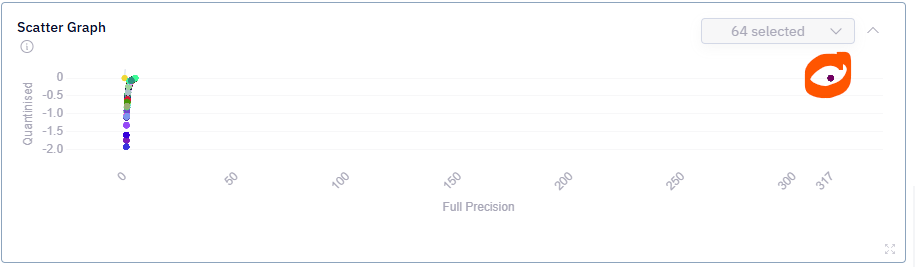
My expectation is that by adding the activation_clipping in the optimization script would clip the inputs to a maximum value of 10 (Instead of around 316) and hence allow reasonable quantization of the layer. What I observe when adding the layer and re-running the analysis tool is that the scatter plot for this layer is unchanged regardless if the activation_clipping directive is added or left out.
My question
How can I clip the inputs to the mul_and_add1 layer to remove the outliers and restrict the “Full Precision” range to less than 10.0?
Additional Information
To investigate the issue I simplified the original model down to just 2 layers. The visualization of this small parsed model with the problematic layer indicated is:
Thanks