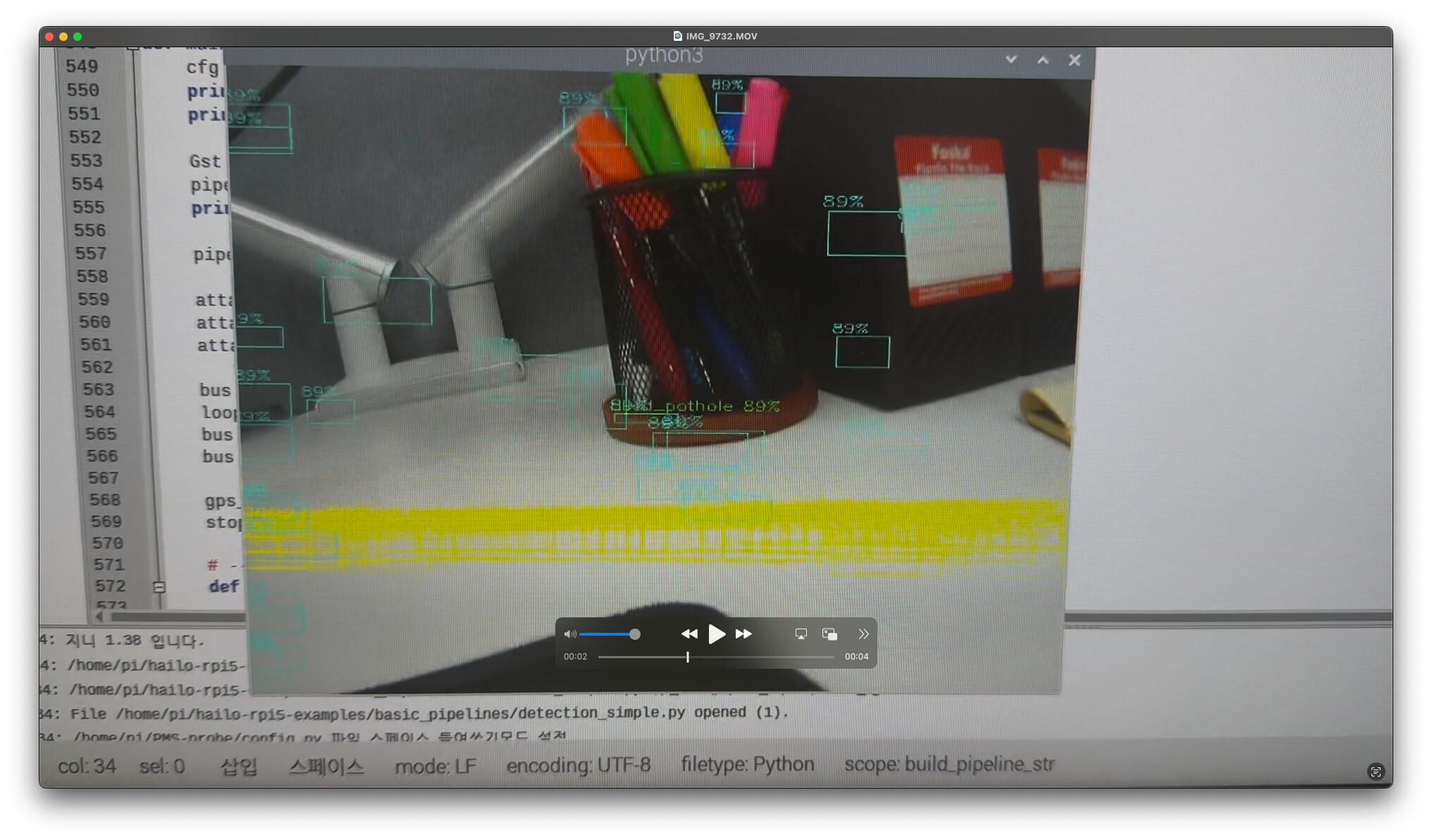
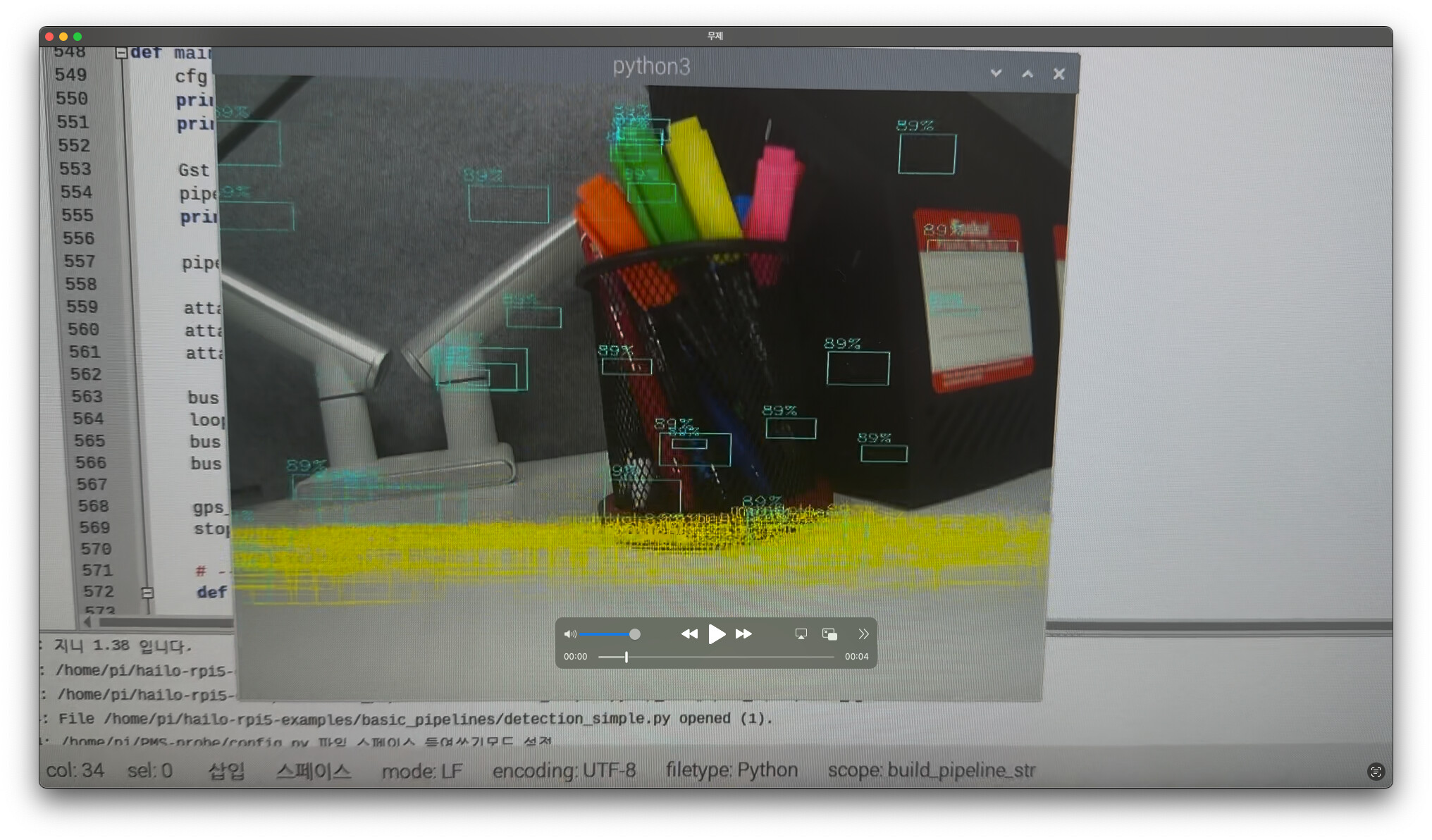
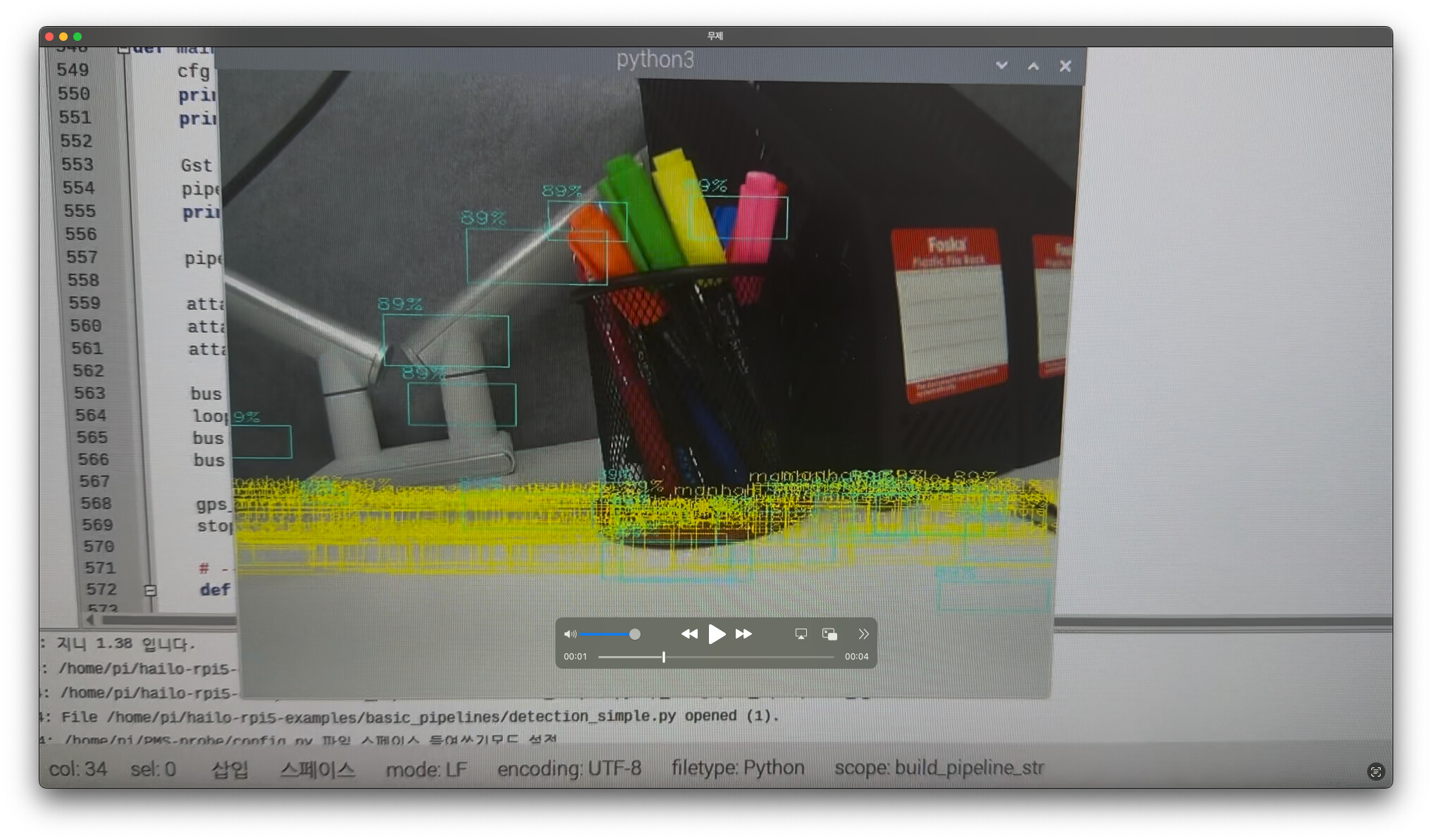
I converted my fine-tuned YOLO11L .pt model into an .hef file, but as you can see in the attached image, the detections look very strange.
Could this issue be caused by the quantization process, or is it more likely related to the post-processing pipeline?
I would greatly appreciate any insights or guidance from experts on this matter.
Thank you!
Welcome to the Hailo Community!
I would not think so. You can test your model in full precision using the emulator in the Hailo AI Software Suite Docker.
Inference with the ONNX model worked correctly.
are you saying that by testing with the full precision emulator, I will be able to clearly identify the cause?
I have already converted the model to HEF through quantization using the Hailo AI Software Suite Docker. Are you saying that what you are referring to is a different process from this?