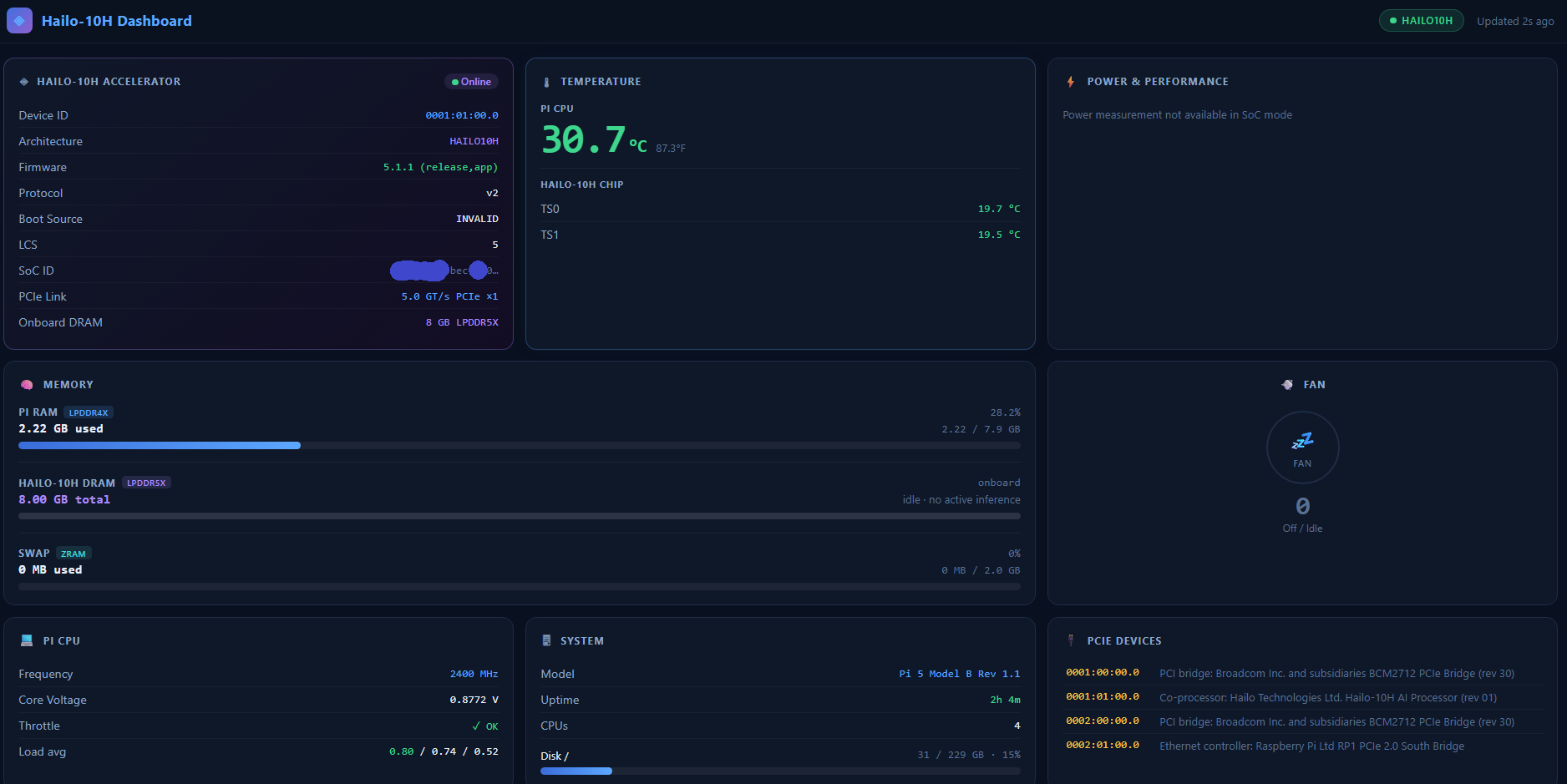
I was curious how much of the memory was being used on the Hailo hat, versus the Raspberry Pi, in my multi-model inference pipeline – so I made a little web dashboard to view all the fun stats. Setup and code over on github…
I am running a small model to “detect” (cheapest), and a slightly larger model to “describe” (cheaper) – both are running locally on the PI, but one is on the Hailo Hat, and one is in ollama on the Pi. Any further processing can be passed further down the pipe ( where it is more expensive )