I’m using the hailomz compile command of the Hailo model zoo to convert my Yolov8x model to a .hef file that I can run on my Hailo8 chip.
While the compiled model makes similar predictions as the original Ultralytics/PyTorch model, there is some degradation that I want to eliminate as much as possible.
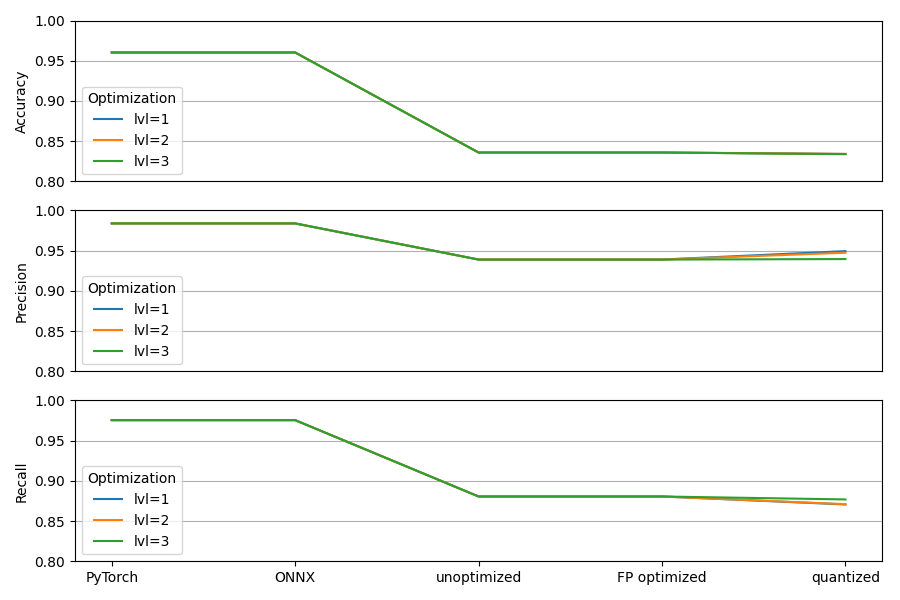
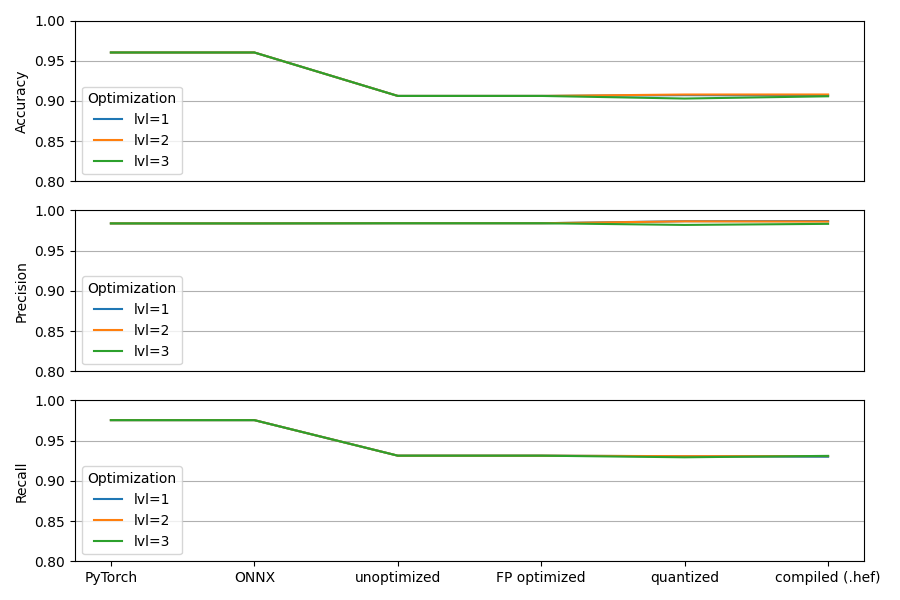
To inspect at which step most degradation happens, I’ve emulated the model’s performance at different stages using InferenceContext.SDK_FP_OPTIMIZED(FP optimized), InferenceContext.SDK_QUANTIZED(quantized) for different optimization levels, and the .predict method of the original YOLO model when importing the PyTorch / ONNX file.
Also, I ran hailomz compile with optimization level -100 to obtain a .har file that should not have undergone any changes w.r.t. the original .onnx input, and extract post-processed output using InferenceContext.SDK_FP_OPTIMIZED (which is unoptimized since optimization level = -100).
The result is shown below. Quite notably:
- The performance degrades significantly after only parsing.
- The performance hardly changes when increasing the optimization level
To further investigate, I’ve also looked at the InferenceContext.SDK_NATIVE output, comparing it to the output of the original PyTorch model by adding forward hooks to the corresponding end nodes. Strangely enough, the outputted values of these layers do not match at all (even though their sizes match well).
Any thoughts on this? Specifically:
- How come the performance degrades after parsing alone?
- How come that, after parsing, the network seems to have substantially changed and does not return the same values anymore?
- Any steps I need to double-check or verify?