Are you inferencing a model with ONNXRuntime + Hailo EP, but all the nodes are executed on the CPU?
[V:onnxruntime:, inference_session.cc:152 VerifyEachNodeIsAssignedToAnEp] All nodes have been placed on [CPUExecutionProvider].
This log indicates that the ONNX model has not been converted for Hailo architecture. Indeed, If you want execute a model with ONNXRuntime on Hailo, you still have to generate the HEF file, and then wrap it in an ONNX graph. This is mandatory, since the model must be quantized and compiled for Hailo NN core.
The flow is the following:
- parse the model, specifying start and end node names to exclude pre/postprocessing operators that are not supported by Hailo (if any)
- optimize the model, using a proper calibration set
- compile the model
- reconstruct the ONNX graph. You can do this using runner.get_hailo_runtime_model() Python API, or hailo har-onnx-rt command line tool
Additional information is available in the DataFlow Compiler User Guide.
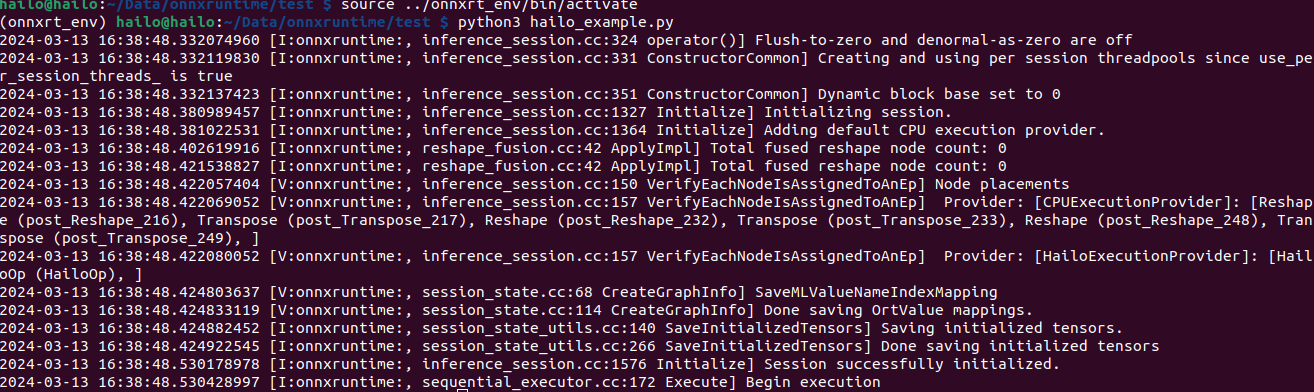
Here is an example of a Yolov5 model. As you can see, the HEF is wrapped in a HailoOp, that will be executed on the Hailo NN core. The other operations (the pre/postprocessing we excluded before) will be executed on the CPU.

When running the model with ONNXRuntime, it is possible to see that only the postprocessing nodes have been placed on the CPU, like in the picture below (required the log to be enabled)