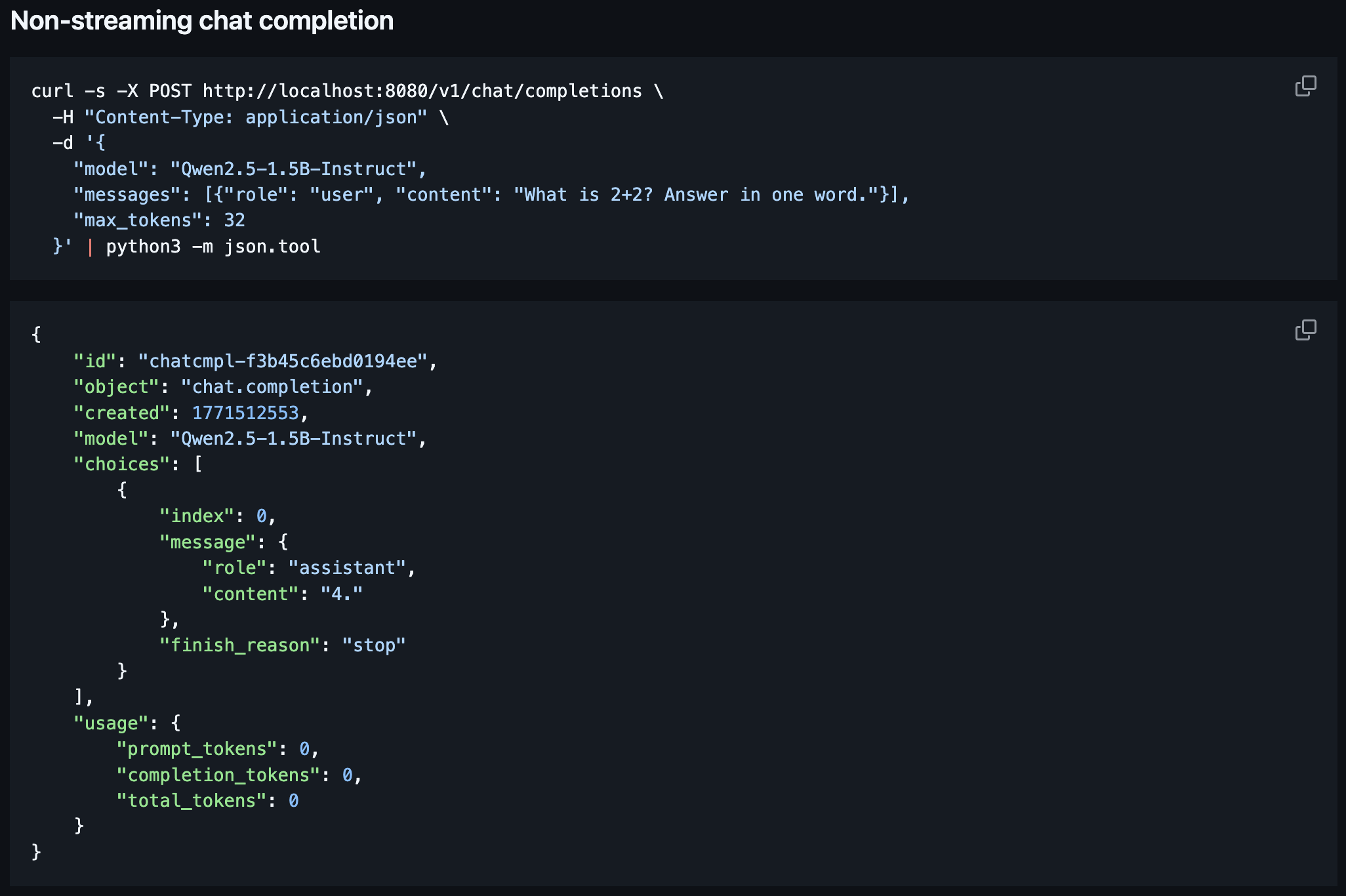
I went ahead and did a thing. Claude and I added some high level API support for the Hailo 10h chip into llama.cpp. Everything is documented in HAILO_README.md.
Disclaimer: You will need to use my fork since I did use AI to write the C code for this integration. The kind people at llama.cpp won’t use this code because of that.
Calling this llama.cpp with Hailo support is very misleading in my opinion. In fact you can take the code that Claude generated for you tools/hailo folder extract it from the project and compile it standalone. The only thing else required are two of the vendored libraries cpp-http and json.hppbut in my opinion this does not qualify as a llama.cpp specific. The resulting code uses none of the llama.cpp infrastructure for handling chat templates, grammar constraining or anything. There are zero dependencies to the llama.cpp project specfically. So this could just be a standalone mini inference api server.
Look I don’t mean to be rude, I just think it is important to be honest about what something is. This is a perfect example of why AI usage policies in projects are important. Just removing AGENTS.md containing the instructions to help guide an user with an agent along the way to get good results and telling Claude to go wild is not how to go about this (yes i did look at the single commit you did) …
Llama.cpp is a standard as well as a server. Meaning the API endpoints produced by the llama.cpp server are in fact what makes this a supported fork of llama.cpp. All my code does is let’s llama.cpp use the Hailo10h chip for inference using the pre-installed HailoRT libraries.
I do not think you know what you are talking about. When someone says they don’t mean to be rude, it is just them being politely rude.
This is not a toy! We actually have some quite serious things in mind for these chips once the code catches up.
No Llama.cpp is not a standard … there is something called the OpenAI API, which is sort of standard across the AI provider world and llama.cpp provides a compatible API. I know exactly what I am talking about. I could make the same argument about your competence, but let’s not go there. That is stupid kindergarden behaviour and nobody benefits from that, also I have no way of judging your knowledge as you have no way of judging mine.
Also if you put something out there and call it something you should probably make sure that it is what people would expect of such a thing. Don’t act surprised if people are disappointed for finding out that is not that. My point is entirely valid the code Claude wrote is mostly standalone and has nothing to do with most of the llama.cpp codebase. I know because I actually tried that … Which means that essential features that llama.cpp provides are not available, and also means to me that calling this llama.cpp with hailo support is misleading. An actual integration would not implement it’s own separate binary for running an inference server and would allow using the entire infrastructure that llama.cpp has already inplace for bending these models. Compared to the full feature set of llama.cpp this very much is a toy. (This does not mean that is not useful … But it is very much not llama.cpp)
I really did not mean to be rude, but tried to provide some constructive critisim:
The resulting code is mostly standalone and has nothing to do with most of the valuable parts of llama.cpp. Namely support for different model chat templates and corresponding parsing functionality as well as grammar constrained output and control of inference parameters. → This would be better as it’s own project, right now it is exactly that. Just embedded into the llama.cpp code repository for no particular reason apart from it being generated there.
The reason for why this happend seams obvious to me from the commit. Removing files guiding that are supposed to guide the model to a more useful integration were just removed, they are there for this exact reason.
I never assumed that you did any of this in bad faith or anything. I just wanted to provide my perspective on the end result. It was meant as feedback nothing more …
OK so what you actually are is a critic of other people’s contributions. You can’t or won’t contribute anything useful yourself, so you seek out someone else’s attempts to at least try. I still believe you are missing a specific skill set to even be having this conversation i.e. you don’t know what you are talking about.
Your so called constructive criticism is just you covering up being rude. I mean, who are you anyway? Nobody to me. Who do you think you are to come at me when you haven’t contributed anything yourself.
I’ve already written more than I should have. What a waste of time you have been.
I am an open source developer and have released and contributed to different kinds of projects. In fact I have contributed code to the projects related to llama.cpp and also released a project based on llama.cpp … If you did two seconds of research you should be able to find my github profile: Hint same username.
In communication there is always a sender and a receiver. Right now you are not engaging with what I am trying to say in good faith. As the sender I have tried to communicate my point clearly without any kind of personal attacks. But if you want to interpret what I am saying as being rude and ignore any valid criticism, then that is your problem not mine.
Ultimately it does not matter code does not lie, the result is there for everybody do see and validate as they see fit. And given my backgound in c++ and c development I am very confident that I am right about what I am saying.
I don’t need or expect you to do anything, do what you please. My goal was to make clear what the result of what you are calling “llama.cpp” actually is. If you don’t want to take my feedback seriously then that’s that.
For anybody else how got excited that they could port their llama.cpp projects to a hailo based device, sorry to disappoint but this is not what you are looking for.