Hello.
I am doing some inferences with RegnetX-800MF on Hailo-8 raspberry pi.
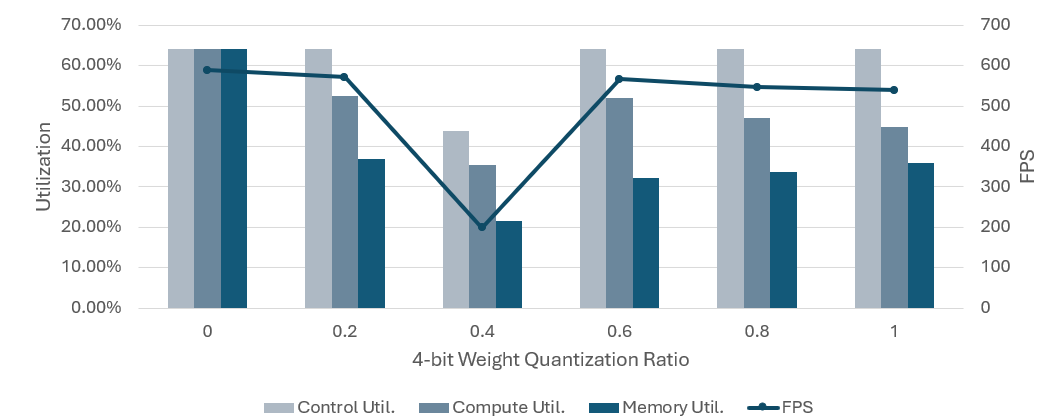
Recently I encountered some FPS drops when I apply 4-bit quantization while compiling. I know that applying 4-bit quantization to small models are not a recommended configuration, but anyway I wanted to figure out the root cause of the issue.
The hardware utilization metrics which are printed right after the compilation using the hailo DFC showed a consistent trend with FPS, so I suspect the cause of the FPS drop is the underutilization of hardware units.
Consequently, I am wondering what really makes the hardware being underutilized if 4-bit quantization is applied to the model. I want to see the memory dumps to inspect how the 4-bit and 8-bit data values are aligned in the memory during the inference and figure out that if the arrangement of data actually causes some bottlenecks.
Could you please inform me of any method that I can observe how the data are actually stored and managed in the memory(L1, L2, L3, L4)?
And if possible, could you also explain the underlying mechanisms contributing to the observed FPS drops when the 4-bit quantization is applied to relatively small models?
Thanks!
- The example model script used for compilation
normalization1 = normalization([123.675, 116.28, 103.53], [58.395, 57.12, 57.375])
model_optimization_flavor(optimization_level=2, compression_level=0, batch_size=8)
model_optimization_config(compression_params, auto_4bit_weights_ratio=0.4)