I want to change the input resolution pipeline for my object detection model and i couldn’t find any documentation mentioning how exactly i have to do that or i have to retrain my whole model to increase the input resolution??
Second question is How to increase the display resolution pipeline as it is very small and can’t be enlarged and i want to maximise it for display monitor.
Thanks you for your help in advance, Please try to answer in detail so that it would help every one who is facing similar problem.
Hi @2101030400090,
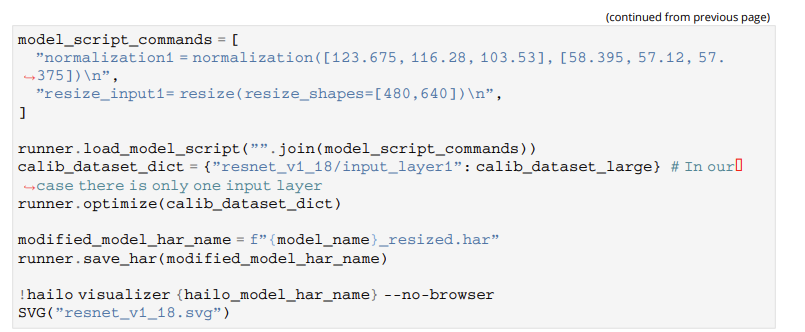
Best practice is to train your model with the resolution you desire. In case you are using a pre-trained model and just want to feed it different input resolution images, you can use Hailo’s input resize option using the model script commands. You can see and example in Hailo’s Dataflow Compiler’s user guide on page 36:
About your second question - what do you mean by display resolution? are you referring to one of our examples or in an example you created on your own?
How can I make the display show in full screen. I am currently facing the issue where the output display is too small and cannot be effectively used for showcasing the results. I would like to increase the output frame size and ensure it appears in full screen on a larger monitor. Could you please advise on how to modify the display pipeline to achieve this?
Also, regarding your first suggestion, if I retrain my YOLOv8 model with larger images, will that help me make better use of the high-quality camera input? What approach would you recommend to get the best performance and image quality? and then i don’t have to change any pipeline setting right?
Sorry if my questions are basic, but I really appreciate your help.
Hi @2101030400090,
To display your output in full screen, you’ll need to resize your relevant output to your screen resolution size. It requires resizing and scaling the output, depending on the vision task you are performing. It can be done using OpenCV.
And yes, if you retrain your model with larger images AND change input resolution of the model in the model’s code. It will give you better image quality for a camera input, but will lower your inference performance (less FPS, more latency). The pipeline itself shouldn’t change except for you won’t have to perform image resize.
Hey i am currently facing an issue i am using --use-frame to give me desired output but the problem is it is creating two output window can you tell me how to disable main windows or use cv2 to draw and do different things in the main window generated hailo , i am really stuck here need some help from your.
and where is the file located of bouding boxes color etc i am only defining class name in json file but where is the color etc are beign defined
the thing is i am only able to edit things when i use --use-frame and can’t in the main frame and because of this two windows are generated and there is no option to disable it.