I want to run two HEF models custom YOLOv11n for object detection and SCDepthV3 for depth estimation simultaneously on a single Hailo‑8 (Raspberry Pi 5 AI Hat 26 TOPS). The idea is:
• YOLO runs continuously to detect objects and get their center points.
• SCDepthV3 runs in parallel to provide depth at those centers.
• I just need the depth values overlayed next to each detected object.
My Questions:
1. Is it possible to load and run two HEFs in parallel on one Hailo‑8?
2. Should I use separate HEFs or merge them via DFC JOIN?
3. What’s the recommended way to implement this?
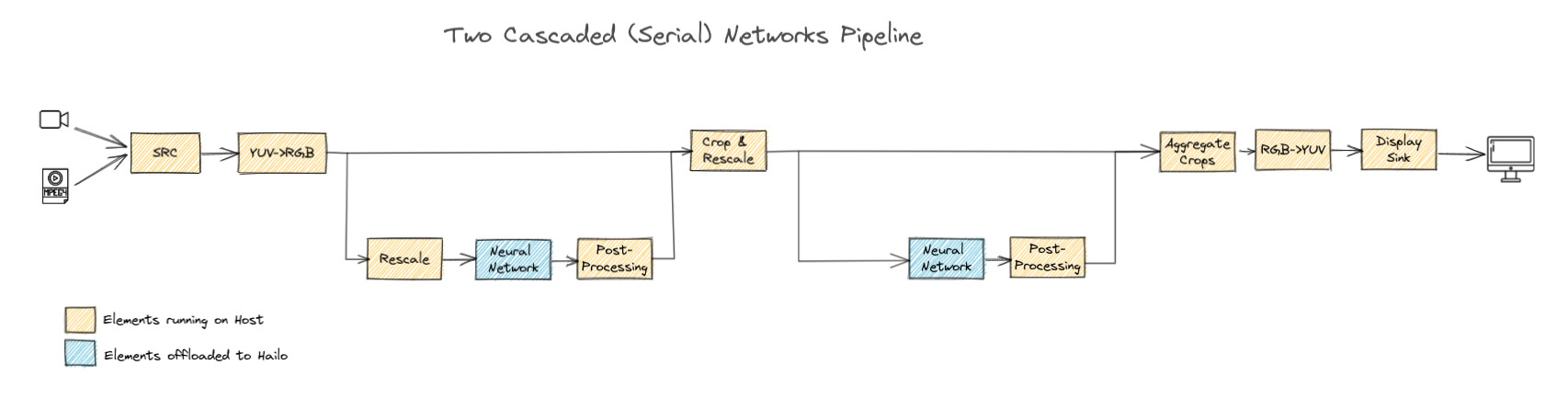
I’d recommend going with cascaded networks for this one. You can detect each object first, then run the depth estimation to get depth info for all detected objects.
Definitely don’t merge the HEFs - not recommended for this type of application. The cascaded approach will give you much better flexibility and performance for object detection + depth estimation workflows.
Here’s what I’m thinking and where I’d appreciate some clarity:
Cropping – Does It Affect Depth Accuracy?
The pipeline uses hailocropper to crop detected objects (bounding boxes) before feeding to SCDepthV3. But monocular depth models like SCDepthV3 rely heavily on full-scene context (perspective, scale, shadows, texture gradients) they weren’t trained on small patches only.
Questions:
• Would cropping only the bounding box compromise depth quality?
• Or should I feed the full frame into SCDepthV3 and just sample the pixel at the box’s center to get a more reliable depth
Sampling Full-Frame Depth
Hailo’s depth.py example uses the full depth matrix output to calculate metrics. Similarly, I could run SCDepthV3 on the full frame—at a lower rate, say 2–3 times per second—and sample the depth map only at center points of detected boxes. This avoids cropping and preserves scene context completely.
Questions for the Community:
1. Which approach provides more accurate depth readings for cropped detections?
2. If cropping must be used, is there a standard way to set the cropping context region size?
3. Would full-frame depth → center-sampling be more reliable? And is that what Hailo recommends?
Here’s a snippet of my pipeline with hailocropper, for reference:
You can definitely feed the same full frame , what I showed you was just an example pipeline.
Here’s what I’d recommend:
Full-frame SCDepth with center-sampling - this gives you the best depth accuracy in my experience.
You don’t have to crop, but if you do decide to go that route, make sure to pad your ROIs (I usually go with something like 1.3× the box size) using the DSP’s crop-and-resize parameters.
That’s how we typically handle this kind of setup, and yeah, based on the pipeline I outlined above, it should work well for what you’re trying to do.
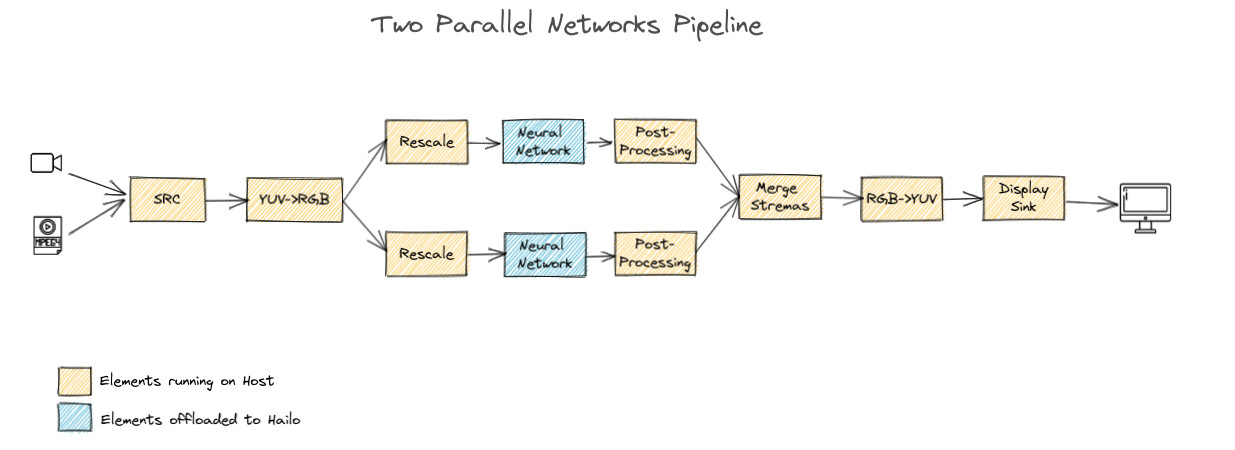
I also notice another type of pipeline which is the parralel network pipeline, like branch 1 do the object detection and branch 2 do the depth estimation. do you think which one would be more suitable in this project? My plan is to display of original image/video with the bounding boxes, and then the estimated depth or distance is written under the bounding box.
I think this approach might work better for you since you’ll have the full depth information available for your detections, and then you can handle the bounding box post-processing.
Just make sure when you’re setting up your merge streams that you properly merge the depth data with the detection frame in the post-processing stage - that way you’ll have both the bounding box coordinates and the corresponding depth information to work with.
Hello, I am fairly new to Hailo and edge AI in general. I was just wondering how I would implement these two HEF files running in parallel on my Pi? Would I have to use Hailo’s Dataflow Compiler in any way?