Hey @ksj,
Sorry if I didn’t catch what you meant exactly.
So, here’s how the example app works when using a camera as the input:
cv::VideoCapture capture;
double frame_count;
if (input_path.empty()) {
capture.open(0, cv::CAP_ANY);
if (!capture.isOpened()) {
throw "Error in camera input";
}
frame_count = -1;
}
else {
capture.open(input_path, cv::CAP_ANY);
if (!capture.isOpened()){
throw "Error when reading video";
}
if (!image_num.empty()){
if (input_path.find(".avi") == std::string::npos && input_path.find(".mp4") == std::string::npos){
frame_count = std::stoi(image_num);
}
else {
frame_count = capture.get(cv::CAP_PROP_FRAME_COUNT);
image_num = "";
}
}
else {
frame_count = capture.get(cv::CAP_PROP_FRAME_COUNT);
}
}
double org_height = capture.get(cv::CAP_PROP_FRAME_HEIGHT);
double org_width = capture.get(cv::CAP_PROP_FRAME_WIDTH);
capture.release();
In this setup, if frame_count is set to -1, the app will keep processing frames indefinitely when it’s using a camera input (or if the input is empty, it just assumes it’s a camera). Basically, it captures each frame one at a time and treats them as single images, so there’s no “video” handling here. To keep it running indefinitely, just make sure frame_count is -1.
To get images from the DMA buffer, you can tweak the code like this:
// Get DMA buffer pointer directly
void* dma_buffer = frames_futures[i].get();
// Set input from DMA buffer
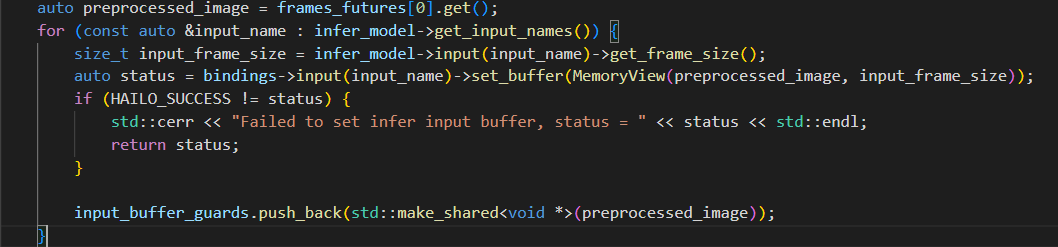
for (const auto &input_name : infer_model->get_input_names()) {
size_t input_frame_size = infer_model->input(input_name)->get_frame_size();
auto status = bindings->input(input_name)->set_buffer(MemoryView(dma_buffer, input_frame_size));
if (HAILO_SUCCESS != status) {
std::cerr << "Failed to set infer input buffer, status = " << status << std::endl;
return status;
}
}
std::vector<std::promise<void*>>& frames_promises, // Changed to void* for DMA
std::vector<std::future<void*>>& frames_futures, // Changed to void* for DMA
Alternatively:
Here’s an untested bit of code that skips the whole “futures and promises” part to work directly with the DMA buffer, which might simplify things:
while (true) {
try {
// Set input buffer using DMA buffer directly
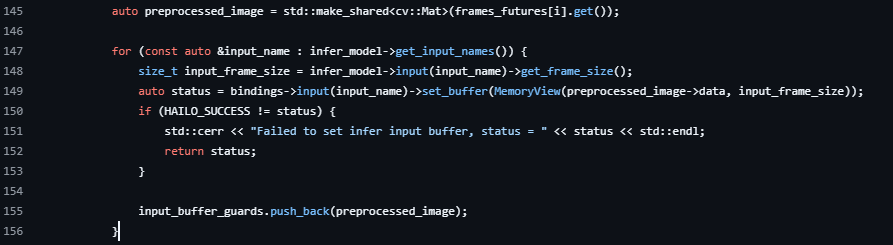
for (const auto &input_name : infer_model->get_input_names()) {
size_t input_frame_size = infer_model->input(input_name)->get_frame_size();
auto status = bindings->input(input_name)->set_buffer(MemoryView(dma_buffer, input_frame_size));
if (HAILO_SUCCESS != status) {
std::cerr << "Failed to set infer input buffer, status = " << status << std::endl;
return status;
}
// Store DMA buffer pointer in guards
input_buffer_guards.push_back(std::make_shared<void*>(dma_buffer));
}
// Handle output buffers
std::vector<std::pair<uint8_t*, hailo_vstream_info_t>> output_data_and_infos;
for (const auto &output_name : output_names) {
size_t output_frame_size = infer_model->output(output_name)->get_frame_size();
output_buffer = page_aligned_alloc(output_frame_size);
auto status = bindings->output(output_name)->set_buffer(MemoryView(output_buffer.get(), output_frame_size));
if (HAILO_SUCCESS != status) {
std::cerr << "Failed to set infer output buffer, status = " << status << std::endl;
return status;
}
output_data_and_infos.push_back(std::make_pair(
bindings->output(output_name)->get_buffer()->data(),
infer_model->hef().get_output_vstream_infos().release()[0]
));
output_buffer_guards.push_back(output_buffer);
}
auto status = configured_infer_model->wait_for_async_ready(std::chrono::milliseconds(1000));
if (HAILO_SUCCESS != status) {
std::cerr << "Failed to run wait_for_async_ready, status = " << status << std::endl;
return status;
}
auto job = configured_infer_model->run_async(bindings.value(),
[&inferred_data_queue, output_data_and_infos, output_buffer](const hailort::AsyncInferCompletionInfo& info) {
inferred_data_queue.push(output_data_and_infos);
(void)output_buffer;
});
if (!job) {
std::cerr << "Failed to start async infer job, status = " << job.status() << std::endl;
return job.status();
}
job->detach();
if (frame_count != -1 && current_frame == frame_count - 1) {
last_infer_job = job.release();
break;
}
current_frame++;
} catch (const std::exception& e) {
std::cerr << "Error during inference: " << e.what() << std::endl;
break;
}
}
Hopefully, this clears things up! If you have any more questions, don’t hesitate to reach out.
Best Regards,
Omri